 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Tokenizer To Rule Them All: Emergent Language Plasticity via Multilingual Tokenizers
Jun 12, 2025Pretraining massively multilingual Large Language Models (LLMs) for many languages at once is challenging due to limited model capacity, scarce high-quality data, and compute constraints. Moreover, the lack of language coverage of the tokenizer makes it harder to address the gap for new languages purely at the post-training stage. In this work, we study what relatively cheap interventions early on in training improve "language plasticity", or adaptation capabilities of the model post-training to new languages. We focus on tokenizer design and propose using a universal tokenizer that is trained for more languages than the primary pretraining languages to enable efficient adaptation in expanding language coverage after pretraining. Our systematic experiments across diverse groups of languages and different training strategies show that a universal tokenizer enables significantly higher language adaptation, with up to 20.2% increase in win rates compared to tokenizers specific to pretraining languages. Furthermore, a universal tokenizer also leads to better plasticity towards languages that are completely unseen in the tokenizer and pretraining, by up to 5% win rate gain. We achieve this adaptation to an expanded set of languages with minimal compromise in performance on the majority of languages included in pretraining.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Rope to Nope and Back Again: A New Hybrid Attention Strategy
Jan 30, 2025



Long-context large language models (LLMs) have achieved remarkable advancements, driven by techniques like Rotary Position Embedding (RoPE) (Su et al., 2023) and its extensions (Chen et al., 2023; Liu et al., 2024c; Peng et al., 2023). By adjusting RoPE parameters and incorporating training data with extended contexts, we can train performant models with considerably longer input sequences. However, existing RoPE-based methods exhibit performance limitations when applied to extended context lengths. This paper presents a comprehensive analysis of various attention mechanisms, including RoPE, No Positional Embedding (NoPE), and Query-Key Normalization (QK-Norm), identifying their strengths and shortcomings in long-context modeling. Our investigation identifies distinctive attention patterns in these methods and highlights their impact on long-context performance, providing valuable insights for architectural design. Building on these findings, we propose a novel architectural based on a hybrid attention mechanism that not only surpasses conventional RoPE-based transformer models in long context tasks but also achieves competitive performance on benchmarks requiring shorter context lengths.
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier
Dec 05, 2024



We introduce the Aya Expanse model family, a new generation of 8B and 32B parameter multilingual language models, aiming to address the critical challenge of developing highly performant multilingual models that match or surpass the capabilities of monolingual models. By leveraging several years of research at Cohere For AI and Cohere, including advancements in data arbitrage, multilingual preference training, and model merging, Aya Expanse sets a new state-of-the-art in multilingual performance. Our evaluations on the Arena-Hard-Auto dataset, translated into 23 languages, demonstrate that Aya Expanse 8B and 32B outperform leading open-weight models in their respective parameter classes, including Gemma 2, Qwen 2.5, and Llama 3.1, achieving up to a 76.6% win-rate. Notably, Aya Expanse 32B outperforms Llama 3.1 70B, a model with twice as many parameters, achieving a 54.0% win-rate. In this short technical report, we present extended evaluation results for the Aya Expanse model family and release their open-weights, together with a new multilingual evaluation dataset m-ArenaHard.
Aya 23: Open Weight Releases to Further Multilingual Progress
May 23, 2024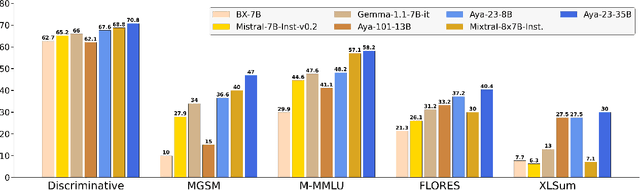

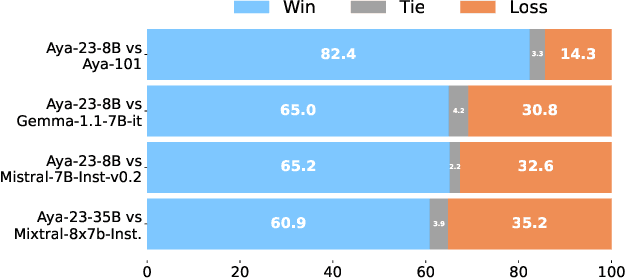

This technical report introduces Aya 23, a family of multilingual language models. Aya 23 builds on the recent release of the Aya model (\"Ust\"un et al., 2024), focusing on pairing a highly performant pre-trained model with the recently released Aya collection (Singh et al., 2024). The result is a powerful multilingual large language model serving 23 languages, expanding state-of-art language modeling capabilities to approximately half of the world's population. The Aya model covered 101 languages whereas Aya 23 is an experiment in depth vs breadth, exploring the impact of allocating more capacity to fewer languages that are included during pre-training. Aya 23 outperforms both previous massively multilingual models like Aya 101 for the languages it covers, as well as widely used models like Gemma, Mistral and Mixtral on an extensive range of discriminative and generative tasks. We release the open weights for both the 8B and 35B models as part of our continued commitment for expanding access to multilingual progress.
On the Theory of Cross-Modality Distillation with Contrastive Learning
May 06, 2024Cross-modality distillation arises as an important topic for data modalities containing limited knowledge such as depth maps and high-quality sketches. Such techniques are of great importance, especially for memory and privacy-restricted scenarios where labeled training data is generally unavailable. To solve the problem, existing label-free methods leverage a few pairwise unlabeled data to distill the knowledge by aligning features or statistics between the source and target modalities. For instance, one typically aims to minimize the L2 distance or contrastive loss between the learned features of pairs of samples in the source (e.g. image) and the target (e.g. sketch) modalities. However, most algorithms in this domain only focus on the experimental results but lack theoretical insight. To bridge the gap between the theory and practical method of cross-modality distillation, we first formulate a general framework of cross-modality contrastive distillation (CMCD), built upon contrastive learning that leverages both positive and negative correspondence, towards a better distillation of generalizable features. Furthermore, we establish a thorough convergence analysis that reveals that the distance between source and target modalities significantly impacts the test error on downstream tasks within the target modality which is also validated by the empirical results. Extensive experimental results show that our algorithm outperforms existing algorithms consistently by a margin of 2-3\% across diverse modalities and tasks, covering modalities of image, sketch, depth map, and audio and tasks of recognition and segmentation.
Speciality vs Generality: An Empirical Study on Catastrophic Forgetting in Fine-tuning Foundation Models
Sep 12, 2023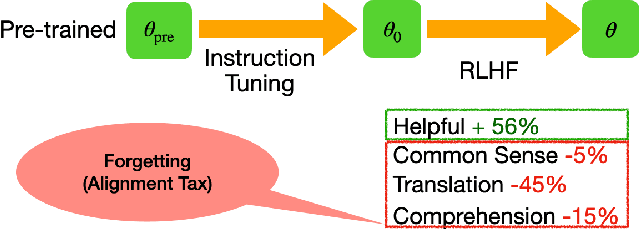
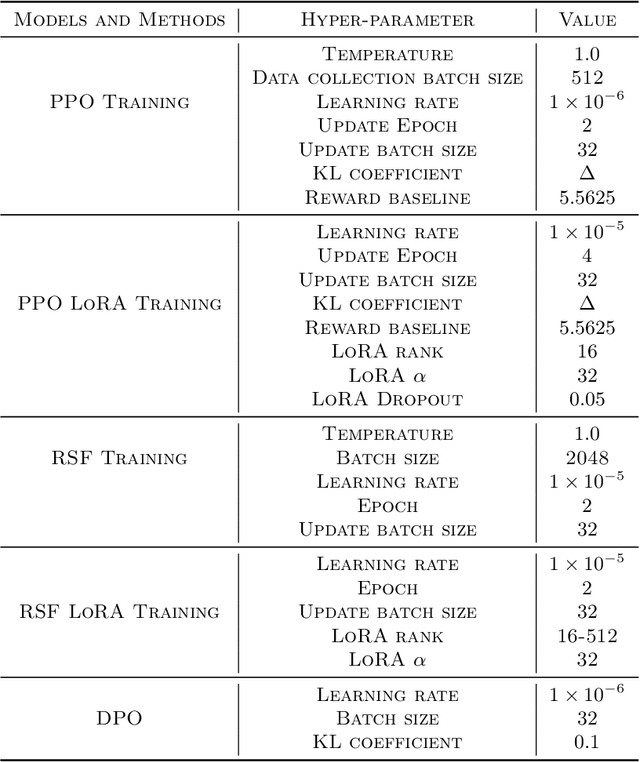
Foundation models, including Vision Language Models (VLMs) and Large Language Models (LLMs), possess the $generality$ to handle diverse distributions and tasks, which stems from their extensive pre-training datasets. The fine-tuning of foundation models is a common practice to enhance task performance or align the model's behavior with human expectations, allowing them to gain $speciality$. However, the small datasets used for fine-tuning may not adequately cover the diverse distributions and tasks encountered during pre-training. Consequently, the pursuit of speciality during fine-tuning can lead to a loss of {generality} in the model, which is related to catastrophic forgetting (CF) in deep learning. In this study, we demonstrate this phenomenon in both VLMs and LLMs. For instance, fine-tuning VLMs like CLIP on ImageNet results in a loss of generality in handling diverse distributions, and fine-tuning LLMs like Galactica in the medical domain leads to a loss in following instructions and common sense. To address the trade-off between the speciality and generality, we investigate multiple regularization methods from continual learning, the weight averaging method (Wise-FT) from out-of-distributional (OOD) generalization, which interpolates parameters between pre-trained and fine-tuned models, and parameter-efficient fine-tuning methods like Low-Rank Adaptation (LoRA). Our findings show that both continual learning and Wise-ft methods effectively mitigate the loss of generality, with Wise-FT exhibiting the strongest performance in balancing speciality and generality.
Sketch-BERT: Learning Sketch Bidirectional Encoder Representation from Transformers by Self-supervised Learning of Sketch Gestalt
May 19, 2020


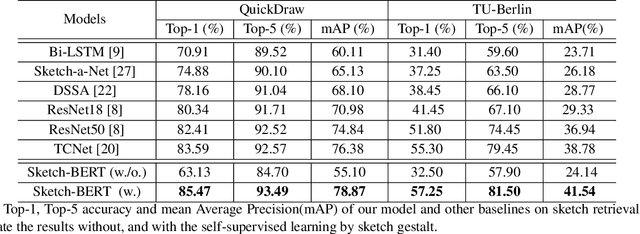
Previous researches of sketches often considered sketches in pixel format and leveraged CNN based models in the sketch understanding. Fundamentally, a sketch is stored as a sequence of data points, a vector format representation, rather than the photo-realistic image of pixels. SketchRNN studied a generative neural representation for sketches of vector format by Long Short Term Memory networks (LSTM). Unfortunately, the representation learned by SketchRNN is primarily for the generation tasks, rather than the other tasks of recognition and retrieval of sketches. To this end and inspired by the recent BERT model, we present a model of learning Sketch Bidirectional Encoder Representation from Transformer (Sketch-BERT). We generalize BERT to sketch domain, with the novel proposed components and pre-training algorithms, including the newly designed sketch embedding networks, and the self-supervised learning of sketch gestalt. Particularly, towards the pre-training task, we present a novel Sketch Gestalt Model (SGM) to help train the Sketch-BERT. Experimentally, we show that the learned representation of Sketch-BERT can help and improve the performance of the downstream tasks of sketch recognition, sketch retrieval, and sketch gestalt.
Learning Large Euclidean Margin for Sketch-based Image Retrieval
Dec 11, 2018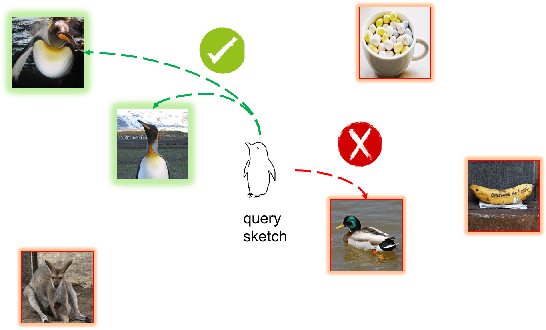



This paper addresses the problem of Sketch-Based Image Retrieval (SBIR), for which bridge the gap between the data representations of sketch images and photo images is considered as the key. Previous works mostly focus on learning a feature space to minimize intra-class distances for both sketches and photos. In contrast, we propose a novel loss function, named Euclidean Margin Softmax (EMS), that not only minimizes intra-class distances but also maximizes inter-class distances simultaneously. It enables us to learn a feature space with high discriminability, leading to highly accurate retrieval. In addition, this loss function is applied to a conditional network architecture, which could incorporate the prior knowledge of whether a sample is a sketch or a photo. We show that the conditional information can be conveniently incorporated to the recently proposed Squeeze and Excitation (SE) module, lead to a conditional SE (CSE) module. Extensive experiments are conducted on two widely used SBIR benchmark datasets. Our approach, although being very simple, achieved new state-of-the-art on both datasets, surpassing existing methods by a large margin.
Instance-level Sketch-based Retrieval by Deep Triplet Classification Siamese Network
Nov 28, 2018



Sketch has been employed as an effective communicative tool to express the abstract and intuitive meanings of object. Recognizing the free-hand sketch drawing is extremely useful in many real-world applications. While content-based sketch recognition has been studied for several decades, the instance-level Sketch-Based Image Retrieval (SBIR) tasks have attracted significant research attention recently. The existing datasets such as QMUL-Chair and QMUL-Shoe, focus on the retrieval tasks of chairs and shoes. However, there are several key limitations in previous instance-level SBIR works. The state-of-the-art works have to heavily rely on the pre-training process, quality of edge maps, multi-cropping testing strategy, and augmenting sketch images. To efficiently solve the instance-level SBIR, we propose a new Deep Triplet Classification Siamese Network (DeepTCNet) which employs DenseNet-169 as the basic feature extractor and is optimized by the triplet loss and classification loss. Critically, our proposed DeepTCNet can break the limitations existed in previous works. The extensive experiments on five benchmark sketch datasets validate the effectiveness of the proposed model. Additionally, to study the tasks of sketch-based hairstyle retrieval, this paper contributes a new instance-level photo-sketch dataset - Hairstyle Photo-Sketch dataset, which is composed of 3600 sketches and photos, and 2400 sketch-photo pairs.