 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Protection For Out-of-distribution Generalization
May 25, 2024


With the availability of large pre-trained models, a modern workflow for building real-world machine learning solutions is to fine-tune such models on a downstream task with a relatively small domain-specific dataset. In such applications, one major challenge is that the small fine-tuning dataset does not have sufficient coverage of the distribution encountered when the model is deployed. It is thus important to design fine-tuning methods that are robust to out-of-distribution (OOD) data that are under-represented by the training data. This paper compares common fine-tuning methods to investigate their OOD performance and demonstrates that standard methods will result in a significant change to the pre-trained model so that the fine-tuned features overfit the fine-tuning dataset. However, this causes deteriorated OOD performance. To overcome this issue, we show that protecting pre-trained features leads to a fine-tuned model more robust to OOD generalization. We validate the feature protection methods with extensive experiments of fine-tuning CLIP on ImageNet and DomainNet.
Speciality vs Generality: An Empirical Study on Catastrophic Forgetting in Fine-tuning Foundation Models
Sep 12, 2023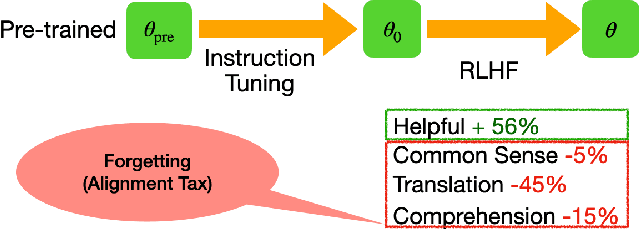
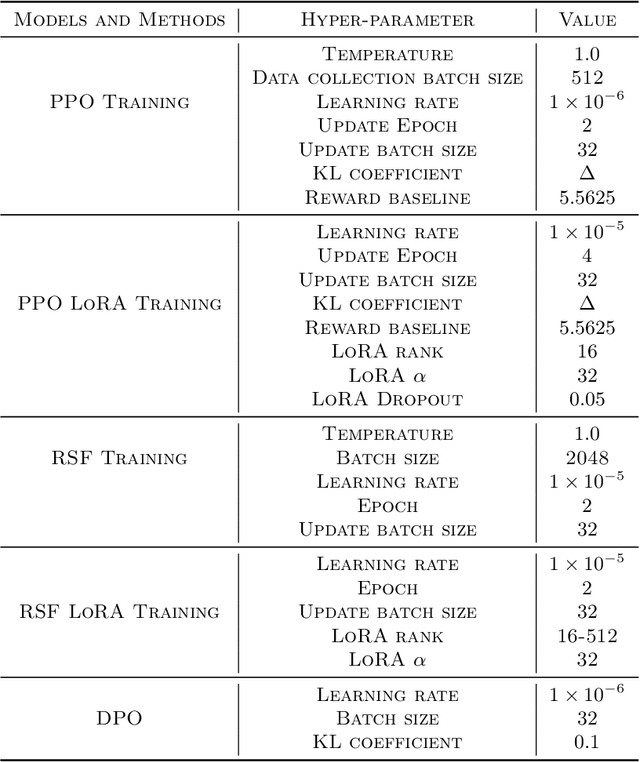
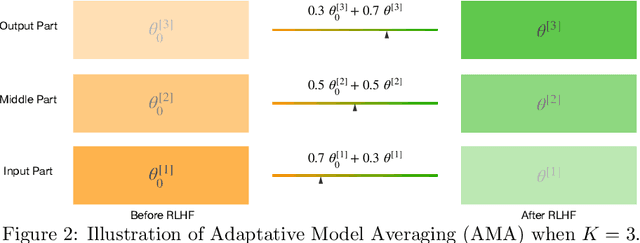
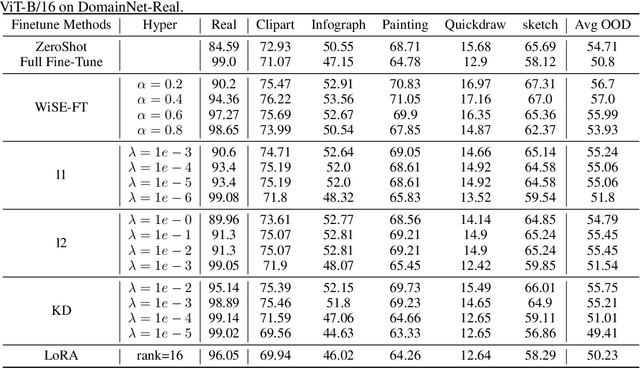
Foundation models, including Vision Language Models (VLMs) and Large Language Models (LLMs), possess the $generality$ to handle diverse distributions and tasks, which stems from their extensive pre-training datasets. The fine-tuning of foundation models is a common practice to enhance task performance or align the model's behavior with human expectations, allowing them to gain $speciality$. However, the small datasets used for fine-tuning may not adequately cover the diverse distributions and tasks encountered during pre-training. Consequently, the pursuit of speciality during fine-tuning can lead to a loss of {generality} in the model, which is related to catastrophic forgetting (CF) in deep learning. In this study, we demonstrate this phenomenon in both VLMs and LLMs. For instance, fine-tuning VLMs like CLIP on ImageNet results in a loss of generality in handling diverse distributions, and fine-tuning LLMs like Galactica in the medical domain leads to a loss in following instructions and common sense. To address the trade-off between the speciality and generality, we investigate multiple regularization methods from continual learning, the weight averaging method (Wise-FT) from out-of-distributional (OOD) generalization, which interpolates parameters between pre-trained and fine-tuned models, and parameter-efficient fine-tuning methods like Low-Rank Adaptation (LoRA). Our findings show that both continual learning and Wise-ft methods effectively mitigate the loss of generality, with Wise-FT exhibiting the strongest performance in balancing speciality and generality.