 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCityGen: Structure-Guided City-Style Synthesis for Cross-City Autonomous Driving
May 28, 2026Autonomous driving systems are commonly trained and evaluated within limited geographic regions, which hinders their scalability when deployed in new cities. However, significant domain shifts in appearance, road topology, and traffic patterns often cause severe performance degradation under cross-city deployment. Existing approaches based on domain adaptation, data augmentation, or synthetic data generation typically rely on labeled target data, city-specific annotations, or task-specific designs, limiting their scalability and effectiveness for holistic evaluation. In this paper, we introduce CityTransfer-Bench, a geographically disjoint benchmark for evaluating cross-city generalization across perception, segmentation, and planning, and propose CityGen, a diffusion-based generative framework that performs zero-label city adaptation via HD-map-conditioned synthesis guided by city-level visual prompts. Extensive experiments demonstrate that CityGen consistently improves cross-city robustness across multiple tasks, establishing a scalable and label-efficient foundation for generalizable autonomous driving.
Feature Protection For Out-of-distribution Generalization
May 25, 2024


With the availability of large pre-trained models, a modern workflow for building real-world machine learning solutions is to fine-tune such models on a downstream task with a relatively small domain-specific dataset. In such applications, one major challenge is that the small fine-tuning dataset does not have sufficient coverage of the distribution encountered when the model is deployed. It is thus important to design fine-tuning methods that are robust to out-of-distribution (OOD) data that are under-represented by the training data. This paper compares common fine-tuning methods to investigate their OOD performance and demonstrates that standard methods will result in a significant change to the pre-trained model so that the fine-tuned features overfit the fine-tuning dataset. However, this causes deteriorated OOD performance. To overcome this issue, we show that protecting pre-trained features leads to a fine-tuned model more robust to OOD generalization. We validate the feature protection methods with extensive experiments of fine-tuning CLIP on ImageNet and DomainNet.
Continuous Invariance Learning
Oct 09, 2023



Invariance learning methods aim to learn invariant features in the hope that they generalize under distributional shifts. Although many tasks are naturally characterized by continuous domains, current invariance learning techniques generally assume categorically indexed domains. For example, auto-scaling in cloud computing often needs a CPU utilization prediction model that generalizes across different times (e.g., time of a day and date of a year), where `time' is a continuous domain index. In this paper, we start by theoretically showing that existing invariance learning methods can fail for continuous domain problems. Specifically, the naive solution of splitting continuous domains into discrete ones ignores the underlying relationship among domains, and therefore potentially leads to suboptimal performance. To address this challenge, we then propose Continuous Invariance Learning (CIL), which extracts invariant features across continuously indexed domains. CIL is a novel adversarial procedure that measures and controls the conditional independence between the labels and continuous domain indices given the extracted features. Our theoretical analysis demonstrates the superiority of CIL over existing invariance learning methods. Empirical results on both synthetic and real-world datasets (including data collected from production systems) show that CIL consistently outperforms strong baselines among all the tasks.
Spurious Feature Diversification Improves Out-of-distribution Generalization
Sep 29, 2023Generalization to out-of-distribution (OOD) data is a critical challenge in machine learning. Ensemble-based methods, like weight space ensembles that interpolate model parameters, have been shown to achieve superior OOD performance. However, the underlying mechanism for their effectiveness remains unclear. In this study, we closely examine WiSE-FT, a popular weight space ensemble method that interpolates between a pre-trained and a fine-tuned model. We observe an unexpected phenomenon, in which WiSE-FT successfully corrects many cases where each individual model makes incorrect predictions, which contributes significantly to its OOD effectiveness. To gain further insights, we conduct theoretical analysis in a multi-class setting with a large number of spurious features. Our analysis predicts the above phenomenon and it further shows that ensemble-based models reduce prediction errors in the OOD settings by utilizing a more diverse set of spurious features. Contrary to the conventional wisdom that focuses on learning invariant features for better OOD performance, our findings suggest that incorporating a large number of diverse spurious features weakens their individual contributions, leading to improved overall OOD generalization performance. Empirically we demonstrate the effectiveness of utilizing diverse spurious features on a MultiColorMNIST dataset, and our experimental results are consistent with the theoretical analysis. Building upon the new theoretical insights into the efficacy of ensemble methods, we further identify an issue of WiSE-FT caused by the overconfidence of fine-tuned models in OOD situations. This overconfidence magnifies the fine-tuned model's incorrect prediction, leading to deteriorated OOD ensemble performance. To remedy this problem, we propose a novel method called BAlaNced averaGing (BANG), which significantly enhances the OOD performance of WiSE-FT.
Speciality vs Generality: An Empirical Study on Catastrophic Forgetting in Fine-tuning Foundation Models
Sep 12, 2023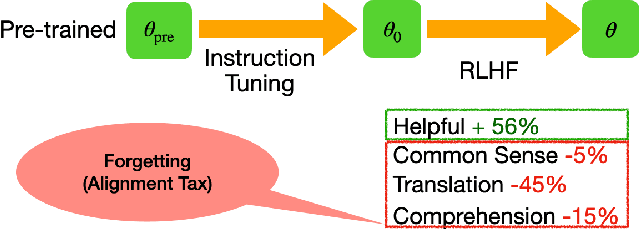
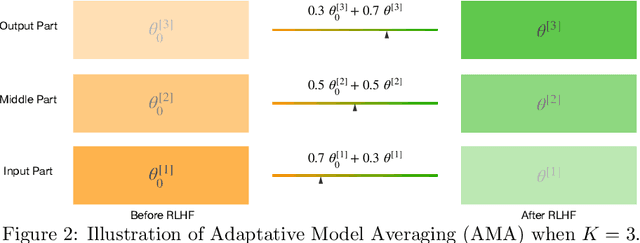
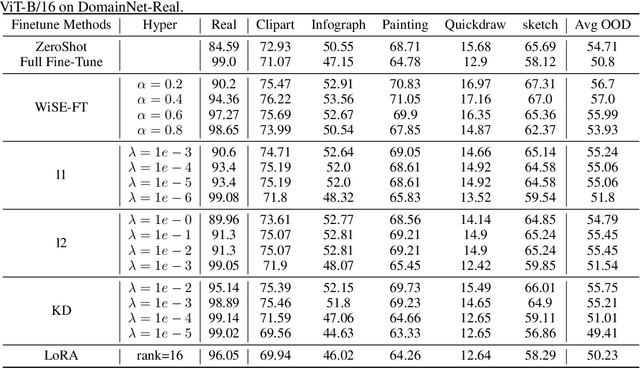
Foundation models, including Vision Language Models (VLMs) and Large Language Models (LLMs), possess the $generality$ to handle diverse distributions and tasks, which stems from their extensive pre-training datasets. The fine-tuning of foundation models is a common practice to enhance task performance or align the model's behavior with human expectations, allowing them to gain $speciality$. However, the small datasets used for fine-tuning may not adequately cover the diverse distributions and tasks encountered during pre-training. Consequently, the pursuit of speciality during fine-tuning can lead to a loss of {generality} in the model, which is related to catastrophic forgetting (CF) in deep learning. In this study, we demonstrate this phenomenon in both VLMs and LLMs. For instance, fine-tuning VLMs like CLIP on ImageNet results in a loss of generality in handling diverse distributions, and fine-tuning LLMs like Galactica in the medical domain leads to a loss in following instructions and common sense. To address the trade-off between the speciality and generality, we investigate multiple regularization methods from continual learning, the weight averaging method (Wise-FT) from out-of-distributional (OOD) generalization, which interpolates parameters between pre-trained and fine-tuned models, and parameter-efficient fine-tuning methods like Low-Rank Adaptation (LoRA). Our findings show that both continual learning and Wise-ft methods effectively mitigate the loss of generality, with Wise-FT exhibiting the strongest performance in balancing speciality and generality.
Using the Split Bregman Algorithm to Solve the Self-Repelling Snake Model
Mar 28, 2020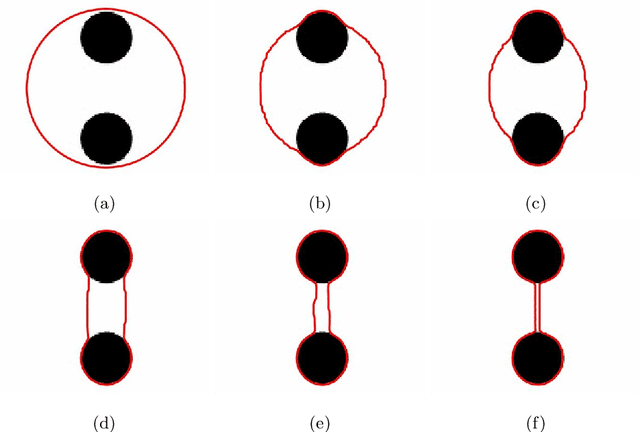


Preserving the contour topology during image segmentation is useful in manypractical scenarios. By keeping the contours isomorphic, it is possible to pre-vent over-segmentation and under-segmentation, as well as to adhere to giventopologies. The self-repelling snake model (SR) is a variational model thatpreserves contour topology by combining a non-local repulsion term with thegeodesic active contour model (GAC). The SR is traditionally solved using theadditive operator splitting (AOS) scheme. Although this solution is stable, thememory requirement grows quickly as the image size increases. In our paper,we propose an alternative solution to the SR using the Split Bregman method.Our algorithm breaks the problem down into simpler subproblems to use lower-order evolution equations and approximation schemes. The memory usage issignificantly reduced as a result. Experiments show comparable performance to the original algorithm with shorter iteration times.
A Novel Euler's Elastica based Segmentation Approach for Noisy Images via using the Progressive Hedging Algorithm
Feb 20, 2019


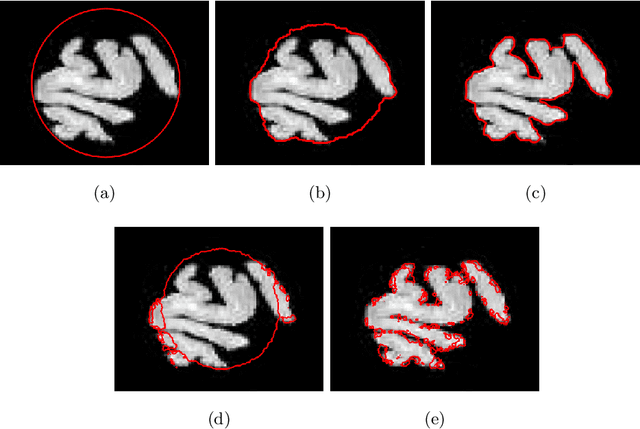
Euler's Elastica based unsupervised segmentation models have strong capability of completing the missing boundaries for existing objects in a clean image, but they are not working well for noisy images. This paper aims to establish a Euler's Elastica based approach that properly deals with random noises to improve the segmentation performance for noisy images. We solve the corresponding optimization problem via using the progressive hedging algorithm (PHA) with a step length suggested by the alternating direction method of multipliers (ADMM). Technically, all the simplified convex versions of the subproblems derived from the major framework of PHA can be obtained by using the curvature weighted approach and the convex relaxation method. Then an alternating optimization strategy is applied with the merits of using some powerful accelerating techniques including the fast Fourier transform (FFT) and generalized soft threshold formulas. Extensive experiments have been conducted on both synthetic and real images, which validated some significant gains of the proposed segmentation models and demonstrated the advantages of the developed algorithm.