 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Scaling Laws for Optimal Mixture-of-Experts Architecture Optimization
Mar 23, 2026Scaling laws for Large Language Models govern macroscopic resource allocation, yet translating them into precise Mixture-of-Experts (MoE) architectural configurations remains an open problem due to the combinatorially vast design space. Existing MoE scaling studies are constrained by experimental budgets to either augment scaling formulas with extra MoE variables, risking unreliable fits, or fix all non-MoE factors, ignoring global interactions. We propose a reusable framework for holistic MoE architectural optimization that bridges this gap. We first show that FLOPs per token alone is an inadequate fairness metric for MoE models because differing computational densities across layer types can inflate parameters without proportional compute cost, and establish a joint constraint triad of FLOPs per token, active parameters, and total parameters. We then reduce the 16-dimensional architectural search space to two sequential low-dimensional phases through algebraic constraints and a rank-preserving property of the hidden dimension. Validated across hundreds of MoE models spanning six orders of magnitude in compute, our framework yields robust scaling laws that map any compute budget to a complete, optimal MoE architecture. A key finding is that the near-optimal configuration band widens with scale, giving practitioners quantitative flexibility to balance scaling law recommendations against infrastructure constraints.
Timestep-Aware Block Masking for Efficient Diffusion Model Inference
Mar 20, 2026Diffusion Probabilistic Models (DPMs) have achieved great success in image generation but suffer from high inference latency due to their iterative denoising nature. Motivated by the evolving feature dynamics across the denoising trajectory, we propose a novel framework to optimize the computational graph of pre-trained DPMs on a per-timestep basis. By learning timestep-specific masks, our method dynamically determines which blocks to execute or bypass through feature reuse at each inference stage. Unlike global optimization methods that incur prohibitive memory costs via full-chain backpropagation, our method optimizes masks for each timestep independently, ensuring a memory-efficient training process. To guide this process, we introduce a timestep-aware loss scaling mechanism that prioritizes feature fidelity during sensitive denoising phases, complemented by a knowledge-guided mask rectification strategy to prune redundant spatial-temporal dependencies. Our approach is architecture-agnostic and demonstrates significant efficiency gains across a broad spectrum of models, including DDPM, LDM, DiT, and PixArt. Experimental results show that by treating the denoising process as a sequence of optimized computational paths, our method achieves a superior balance between sampling speed and generative quality. Our code will be released.
AutoQRA: Joint Optimization of Mixed-Precision Quantization and Low-rank Adapters for Efficient LLM Fine-Tuning
Feb 25, 2026Quantization followed by parameter-efficient fine-tuning has emerged as a promising paradigm for downstream adaptation under tight GPU memory constraints. However, this sequential pipeline fails to leverage the intricate interaction between quantization bit-width and LoRA rank. Specifically, a carefully optimized quantization allocation with low quantization error does not always translate to strong fine-tuning performance, and different bit-width and rank configurations can lead to significantly varying outcomes under the same memory budget. To address this limitation, we propose AutoQRA, a joint optimization framework that simultaneously optimizes the bit-width and LoRA rank configuration for each layer during the mixed quantized fine-tuning process. To tackle the challenges posed by the large discrete search space and the high evaluation cost associated with frequent fine-tuning iterations, AutoQRA decomposes the optimization process into two stages. First, it first conducts a global multi-fidelity evolutionary search, where the initial population is warm-started by injecting layer-wise importance priors. This stage employs specific operators and a performance model to efficiently screen candidate configurations. Second, trust-region Bayesian optimization is applied to locally refine promising regions of the search space and identify optimal configurations under the given memory budget. This approach enables active compensation for quantization noise in specific layers during training. Experiments show that AutoQRA achieves performance close to full-precision fine-tuning with a memory footprint comparable to uniform 4-bit methods.
Investigating Data Pruning for Pretraining Biological Foundation Models at Scale
Dec 15, 2025Biological foundation models (BioFMs), pretrained on large-scale biological sequences, have recently shown strong potential in providing meaningful representations for diverse downstream bioinformatics tasks. However, such models often rely on millions to billions of training sequences and billions of parameters, resulting in prohibitive computational costs and significant barriers to reproducibility and accessibility, particularly for academic labs. To address these challenges, we investigate the feasibility of data pruning for BioFM pretraining and propose a post-hoc influence-guided data pruning framework tailored to biological domains. Our approach introduces a subset-based self-influence formulation that enables efficient estimation of sample importance at low computational cost, and builds upon it two simple yet effective selection strategies, namely Top-k Influence (Top I) and Coverage-Centric Influence (CCI). We empirically validate our method on two representative BioFMs, RNA-FM and ESM-C. For RNA, our framework consistently outperforms random selection baselines under an extreme pruning rate of over 99 percent, demonstrating its effectiveness. Furthermore, we show the generalizability of our framework on protein-related tasks using ESM-C. In particular, our coreset even outperforms random subsets that are ten times larger in both RNA and protein settings, revealing substantial redundancy in biological sequence datasets. These findings underscore the potential of influence-guided data pruning to substantially reduce the computational cost of BioFM pretraining, paving the way for more efficient, accessible, and sustainable biological AI research.
Advanced Black-Box Tuning of Large Language Models with Limited API Calls
Nov 17, 2025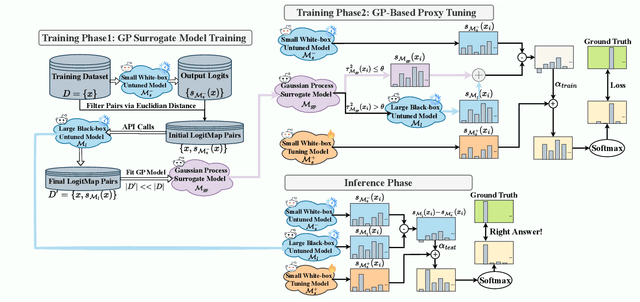
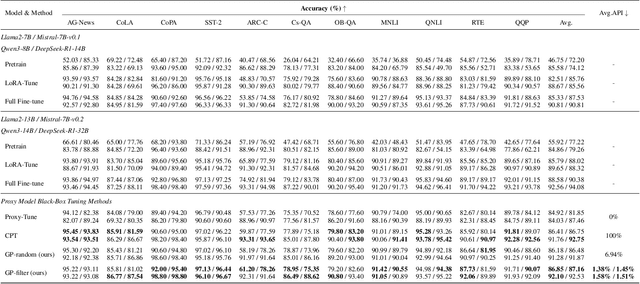

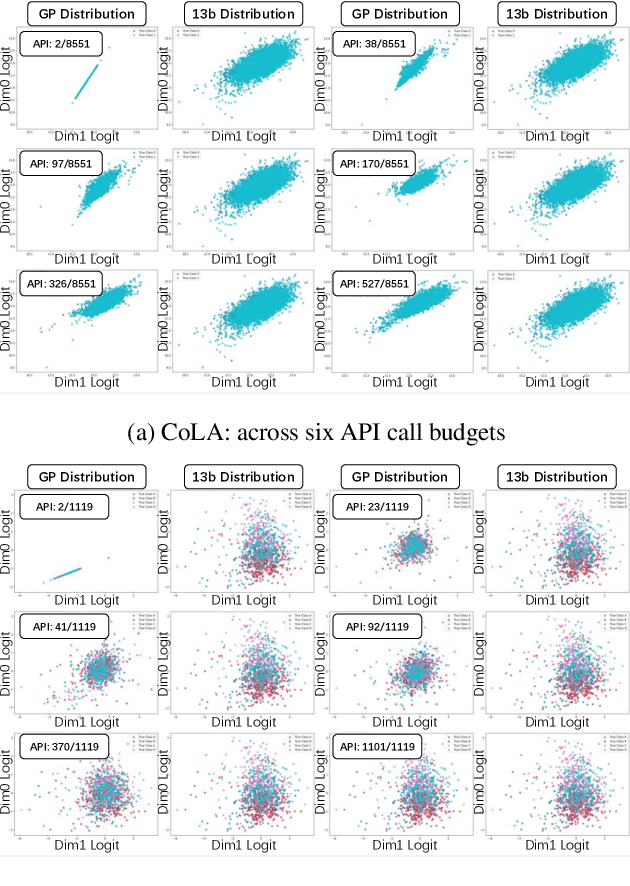
Black-box tuning is an emerging paradigm for adapting large language models (LLMs) to better achieve desired behaviors, particularly when direct access to model parameters is unavailable. Current strategies, however, often present a dilemma of suboptimal extremes: either separately train a small proxy model and then use it to shift the predictions of the foundation model, offering notable efficiency but often yielding limited improvement; or making API calls in each tuning iteration to the foundation model, which entails prohibitive computational costs. Therefore, we propose a novel advanced black-box tuning method for LLMs with limited API calls. Our core strategy involves training a Gaussian Process (GP) surrogate model with "LogitMap Pairs" derived from querying the foundation model on a minimal but highly informative training subset. This surrogate can approximate the outputs of the foundation model to guide the training of the proxy model, thereby effectively reducing the need for direct queries to the foundation model. Extensive experiments verify that our approach elevates pre-trained language model accuracy from 55.92% to 86.85%, reducing the frequency of API queries to merely 1.38%. This significantly outperforms offline approaches that operate entirely without API access. Notably, our method also achieves comparable or superior accuracy to query-intensive approaches, while significantly reducing API costs. This offers a robust and high-efficiency paradigm for language model adaptation.
Explore and Establish Synergistic Effects Between Weight Pruning and Coreset Selection in Neural Network Training
Nov 17, 2025Modern deep neural networks rely heavily on massive model weights and training samples, incurring substantial computational costs. Weight pruning and coreset selection are two emerging paradigms proposed to improve computational efficiency. In this paper, we first explore the interplay between redundant weights and training samples through a transparent analysis: redundant samples, particularly noisy ones, cause model weights to become unnecessarily overtuned to fit them, complicating the identification of irrelevant weights during pruning; conversely, irrelevant weights tend to overfit noisy data, undermining coreset selection effectiveness. To further investigate and harness this interplay in deep learning, we develop a Simultaneous Weight and Sample Tailoring mechanism (SWaST) that alternately performs weight pruning and coreset selection to establish a synergistic effect in training. During this investigation, we observe that when simultaneously removing a large number of weights and samples, a phenomenon we term critical double-loss can occur, where important weights and their supportive samples are mistakenly eliminated at the same time, leading to model instability and nearly irreversible degradation that cannot be recovered in subsequent training. Unlike classic machine learning models, this issue can arise in deep learning due to the lack of theoretical guarantees on the correctness of weight pruning and coreset selection, which explains why these paradigms are often developed independently. We mitigate this by integrating a state preservation mechanism into SWaST, enabling stable joint optimization. Extensive experiments reveal a strong synergy between pruning and coreset selection across varying prune rates and coreset sizes, delivering accuracy boosts of up to 17.83% alongside 10% to 90% FLOPs reductions.
Towards Robust Influence Functions with Flat Validation Minima
May 25, 2025The Influence Function (IF) is a widely used technique for assessing the impact of individual training samples on model predictions. However, existing IF methods often fail to provide reliable influence estimates in deep neural networks, particularly when applied to noisy training data. This issue does not stem from inaccuracies in parameter change estimation, which has been the primary focus of prior research, but rather from deficiencies in loss change estimation, specifically due to the sharpness of validation risk. In this work, we establish a theoretical connection between influence estimation error, validation set risk, and its sharpness, underscoring the importance of flat validation minima for accurate influence estimation. Furthermore, we introduce a novel estimation form of Influence Function specifically designed for flat validation minima. Experimental results across various tasks validate the superiority of our approach.
Efficient Fine-Tuning of Quantized Models via Adaptive Rank and Bitwidth
May 02, 2025
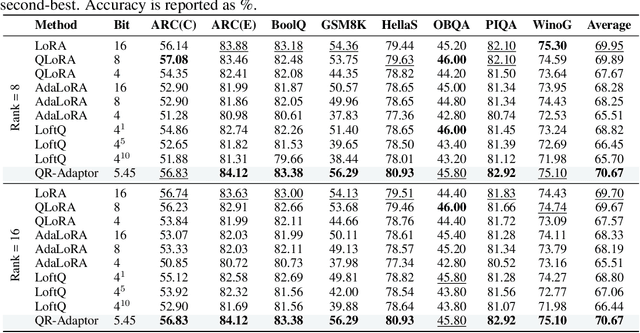
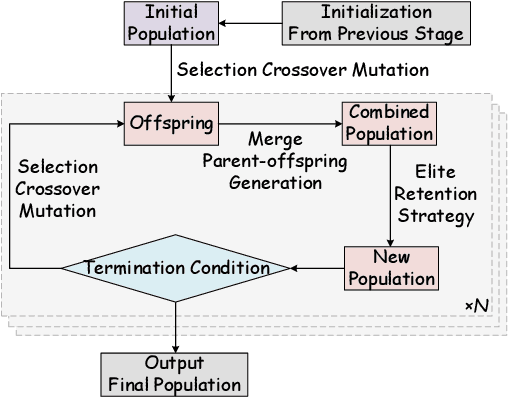
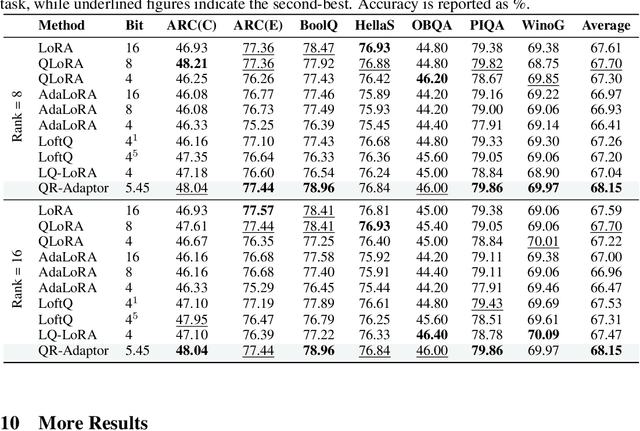
QLoRA effectively combines low-bit quantization and LoRA to achieve memory-friendly fine-tuning for large language models (LLM). Recently, methods based on SVD for continuous update iterations to initialize LoRA matrices to accommodate quantization errors have generally failed to consistently improve performance. Dynamic mixed precision is a natural idea for continuously improving the fine-tuning performance of quantized models, but previous methods often optimize low-rank subspaces or quantization components separately, without considering their synergy. To address this, we propose \textbf{QR-Adaptor}, a unified, gradient-free strategy that uses partial calibration data to jointly search the quantization components and the rank of low-rank spaces for each layer, thereby continuously improving model performance. QR-Adaptor does not minimize quantization error but treats precision and rank allocation as a discrete optimization problem guided by actual downstream performance and memory usage. Compared to state-of-the-art (SOTA) quantized LoRA fine-tuning methods, our approach achieves a 4.89\% accuracy improvement on GSM8K, and in some cases even outperforms the 16-bit fine-tuned model while maintaining the memory footprint of the 4-bit setting.
Large Language Model Compression with Global Rank and Sparsity Optimization
May 02, 2025Low-rank and sparse composite approximation is a natural idea to compress Large Language Models (LLMs). However, such an idea faces two primary challenges that adversely affect the performance of existing methods. The first challenge relates to the interaction and cooperation between low-rank and sparse matrices, while the second involves determining weight allocation across different layers, as redundancy varies considerably among them. To address these challenges, we propose a novel two-stage LLM compression method with the capability of global rank and sparsity optimization. It is noteworthy that the overall optimization space is vast, making comprehensive optimization computationally prohibitive. Therefore, to reduce the optimization space, our first stage utilizes robust principal component analysis to decompose the weight matrices of LLMs into low-rank and sparse components, which span the low dimensional and sparse spaces containing the resultant low-rank and sparse matrices, respectively. In the second stage, we propose a probabilistic global optimization technique to jointly identify the low-rank and sparse structures within the above two spaces. The appealing feature of our approach is its ability to automatically detect the redundancy across different layers and to manage the interaction between the sparse and low-rank components. Extensive experimental results indicate that our method significantly surpasses state-of-the-art techniques for sparsification and composite approximation.
Optimized Gradient Clipping for Noisy Label Learning
Dec 12, 2024



Previous research has shown that constraining the gradient of loss function with respect to model-predicted probabilities can enhance the model robustness against noisy labels. These methods typically specify a fixed optimal threshold for gradient clipping through validation data to obtain the desired robustness against noise. However, this common practice overlooks the dynamic distribution of gradients from both clean and noisy-labeled samples at different stages of training, significantly limiting the model capability to adapt to the variable nature of gradients throughout the training process. To address this issue, we propose a simple yet effective approach called Optimized Gradient Clipping (OGC), which dynamically adjusts the clipping threshold based on the ratio of noise gradients to clean gradients after clipping, estimated by modeling the distributions of clean and noisy samples. This approach allows us to modify the clipping threshold at each training step, effectively controlling the influence of noise gradients. Additionally, we provide statistical analysis to certify the noise-tolerance ability of OGC. Our extensive experiments across various types of label noise, including symmetric, asymmetric, instance-dependent, and real-world noise, demonstrate the effectiveness of our approach. The code and a technical appendix for better digital viewing are included as supplementary materials and scheduled to be open-sourced upon publication.