 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
From Sparse to Dense: Multi-View GRPO for Flow Models via Augmented Condition Space
Mar 13, 2026Group Relative Policy Optimization (GRPO) has emerged as a powerful framework for preference alignment in text-to-image (T2I) flow models. However, we observe that the standard paradigm where evaluating a group of generated samples against a single condition suffers from insufficient exploration of inter-sample relationships, constraining both alignment efficacy and performance ceilings. To address this sparse single-view evaluation scheme, we propose Multi-View GRPO (MV-GRPO), a novel approach that enhances relationship exploration by augmenting the condition space to create a dense multi-view reward mapping. Specifically, for a group of samples generated from one prompt, MV-GRPO leverages a flexible Condition Enhancer to generate semantically adjacent yet diverse captions. These captions enable multi-view advantage re-estimation, capturing diverse semantic attributes and providing richer optimization signals. By deriving the probability distribution of the original samples conditioned on these new captions, we can incorporate them into the training process without costly sample regeneration. Extensive experiments demonstrate that MV-GRPO achieves superior alignment performance over state-of-the-art methods.
DeepGen 1.0: A Lightweight Unified Multimodal Model for Advancing Image Generation and Editing
Feb 13, 2026Current unified multimodal models for image generation and editing typically rely on massive parameter scales (e.g., >10B), entailing prohibitive training costs and deployment footprints. In this work, we present DeepGen 1.0, a lightweight 5B unified model that achieves comprehensive capabilities competitive with or surpassing much larger counterparts. To overcome the limitations of compact models in semantic understanding and fine-grained control, we introduce Stacked Channel Bridging (SCB), a deep alignment framework that extracts hierarchical features from multiple VLM layers and fuses them with learnable 'think tokens' to provide the generative backbone with structured, reasoning-rich guidance. We further design a data-centric training strategy spanning three progressive stages: (1) Alignment Pre-training on large-scale image-text pairs and editing triplets to synchronize VLM and DiT representations, (2) Joint Supervised Fine-tuning on a high-quality mixture of generation, editing, and reasoning tasks to foster omni-capabilities, and (3) Reinforcement Learning with MR-GRPO, which leverages a mixture of reward functions and supervision signals, resulting in substantial gains in generation quality and alignment with human preferences, while maintaining stable training progress and avoiding visual artifacts. Despite being trained on only ~50M samples, DeepGen 1.0 achieves leading performance across diverse benchmarks, surpassing the 80B HunyuanImage by 28% on WISE and the 27B Qwen-Image-Edit by 37% on UniREditBench. By open-sourcing our training code, weights, and datasets, we provide an efficient, high-performance alternative to democratize unified multimodal research.
UniReason 1.0: A Unified Reasoning Framework for World Knowledge Aligned Image Generation and Editing
Feb 02, 2026Unified multimodal models often struggle with complex synthesis tasks that demand deep reasoning, and typically treat text-to-image generation and image editing as isolated capabilities rather than interconnected reasoning steps. To address this, we propose UniReason, a unified framework that harmonizes these two tasks through a dual reasoning paradigm. We formulate generation as world knowledge-enhanced planning to inject implicit constraints, and leverage editing capabilities for fine-grained visual refinement to further correct visual errors via self-reflection. This approach unifies generation and editing within a shared representation, mirroring the human cognitive process of planning followed by refinement. We support this framework by systematically constructing a large-scale reasoning-centric dataset (~300k samples) covering five major knowledge domains (e.g., cultural commonsense, physics, etc.) for planning, alongside an agent-generated corpus for visual self-correction. Extensive experiments demonstrate that UniReason achieves advanced performance on reasoning-intensive benchmarks such as WISE, KrisBench and UniREditBench, while maintaining superior general synthesis capabilities.
Unified Personalized Reward Model for Vision Generation
Feb 02, 2026Recent advancements in multimodal reward models (RMs) have significantly propelled the development of visual generation. Existing frameworks typically adopt Bradley-Terry-style preference modeling or leverage generative VLMs as judges, and subsequently optimize visual generation models via reinforcement learning. However, current RMs suffer from inherent limitations: they often follow a one-size-fits-all paradigm that assumes a monolithic preference distribution or relies on fixed evaluation rubrics. As a result, they are insensitive to content-specific visual cues, leading to systematic misalignment with subjective and context-dependent human preferences. To this end, inspired by human assessment, we propose UnifiedReward-Flex, a unified personalized reward model for vision generation that couples reward modeling with flexible and context-adaptive reasoning. Specifically, given a prompt and the generated visual content, it first interprets the semantic intent and grounds on visual evidence, then dynamically constructs a hierarchical assessment by instantiating fine-grained criteria under both predefined and self-generated high-level dimensions. Our training pipeline follows a two-stage process: (1) we first distill structured, high-quality reasoning traces from advanced closed-source VLMs to bootstrap SFT, equipping the model with flexible and context-adaptive reasoning behaviors; (2) we then perform direct preference optimization (DPO) on carefully curated preference pairs to further strengthen reasoning fidelity and discriminative alignment. To validate the effectiveness, we integrate UnifiedReward-Flex into the GRPO framework for image and video synthesis, and extensive results demonstrate its superiority.
FairExpand: Individual Fairness on Graphs with Partial Similarity Information
Dec 20, 2025
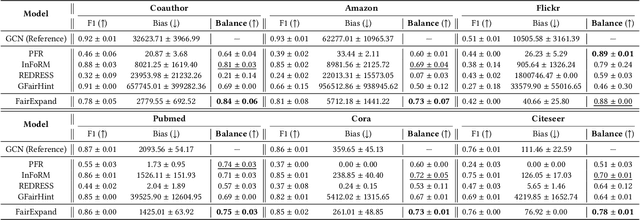
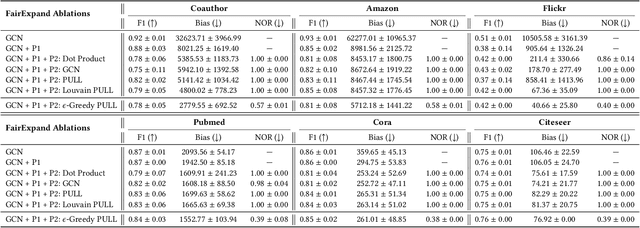
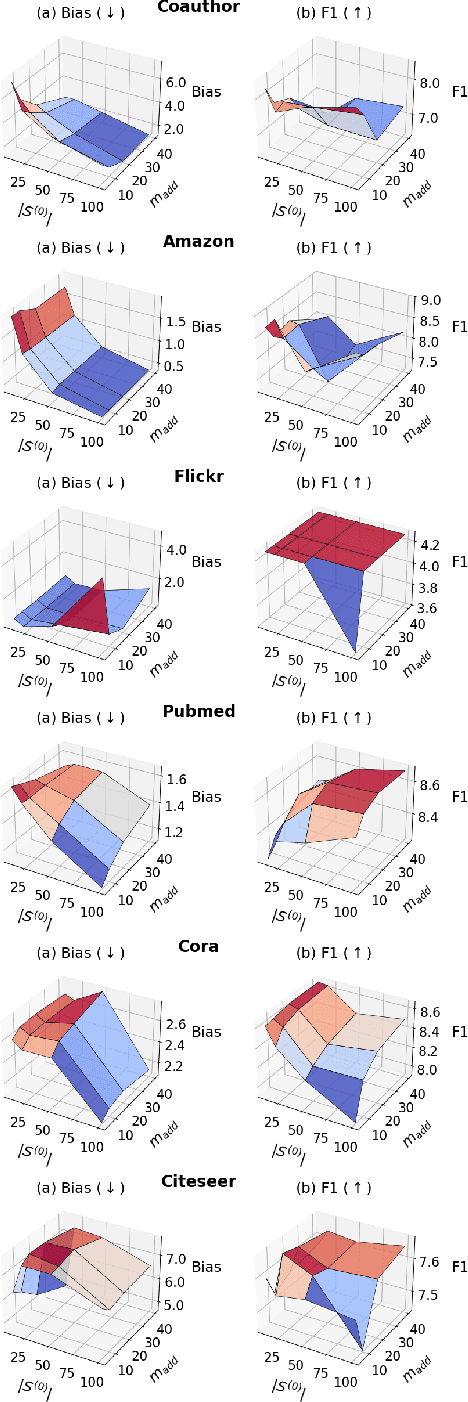
Individual fairness, which requires that similar individuals should be treated similarly by algorithmic systems, has become a central principle in fair machine learning. Individual fairness has garnered traction in graph representation learning due to its practical importance in high-stakes Web areas such as user modeling, recommender systems, and search. However, existing methods assume the existence of predefined similarity information over all node pairs, an often unrealistic requirement that prevents their operationalization in practice. In this paper, we assume the similarity information is only available for a limited subset of node pairs and introduce FairExpand, a flexible framework that promotes individual fairness in this more realistic partial information scenario. FairExpand follows a two-step pipeline that alternates between refining node representations using a backbone model (e.g., a graph neural network) and gradually propagating similarity information, which allows fairness enforcement to effectively expand to the entire graph. Extensive experiments show that FairExpand consistently enhances individual fairness while preserving performance, making it a practical solution for enabling graph-based individual fairness in real-world applications with partial similarity information.
$\text{G}^2$RPO: Granular GRPO for Precise Reward in Flow Models
Oct 02, 2025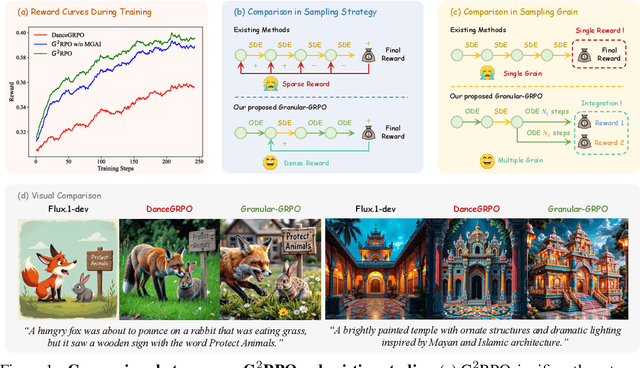
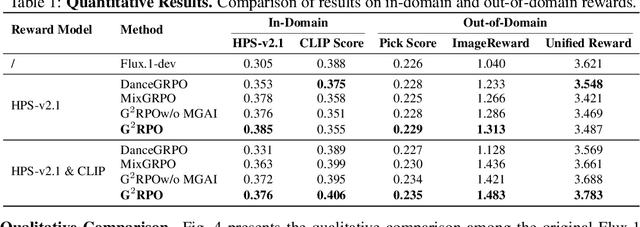
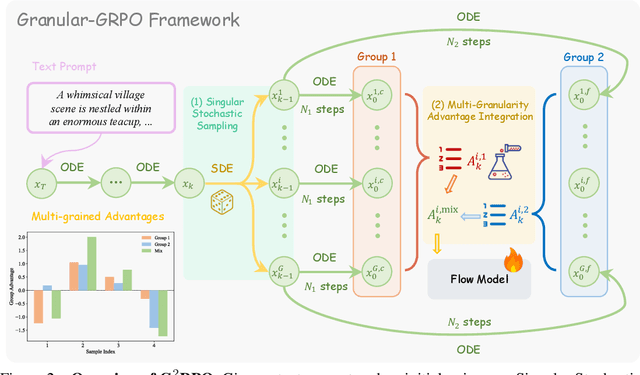
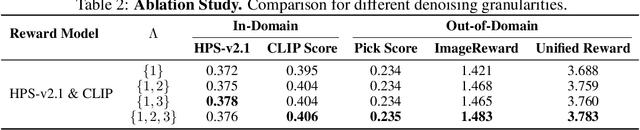
The integration of online reinforcement learning (RL) into diffusion and flow models has recently emerged as a promising approach for aligning generative models with human preferences. Stochastic sampling via Stochastic Differential Equations (SDE) is employed during the denoising process to generate diverse denoising directions for RL exploration. While existing methods effectively explore potential high-value samples, they suffer from sub-optimal preference alignment due to sparse and narrow reward signals. To address these challenges, we propose a novel Granular-GRPO ($\text{G}^2$RPO ) framework that achieves precise and comprehensive reward assessments of sampling directions in reinforcement learning of flow models. Specifically, a Singular Stochastic Sampling strategy is introduced to support step-wise stochastic exploration while enforcing a high correlation between the reward and the injected noise, thereby facilitating a faithful reward for each SDE perturbation. Concurrently, to eliminate the bias inherent in fixed-granularity denoising, we introduce a Multi-Granularity Advantage Integration module that aggregates advantages computed at multiple diffusion scales, producing a more comprehensive and robust evaluation of the sampling directions. Experiments conducted on various reward models, including both in-domain and out-of-domain evaluations, demonstrate that our $\text{G}^2$RPO significantly outperforms existing flow-based GRPO baselines,highlighting its effectiveness and robustness.
Towards Confidential and Efficient LLM Inference with Dual Privacy Protection
Sep 11, 2025CPU-based trusted execution environments (TEEs) and differential privacy (DP) have gained wide applications for private inference. Due to high inference latency in TEEs, researchers use partition-based approaches that offload linear model components to GPUs. However, dense nonlinear layers of large language models (LLMs) result in significant communication overhead between TEEs and GPUs. DP-based approaches apply random noise to protect data privacy, but this compromises LLM performance and semantic understanding. To overcome the above drawbacks, this paper proposes CMIF, a Confidential and efficient Model Inference Framework. CMIF confidentially deploys the embedding layer in the client-side TEE and subsequent layers on GPU servers. Meanwhile, it optimizes the Report-Noisy-Max mechanism to protect sensitive inputs with a slight decrease in model performance. Extensive experiments on Llama-series models demonstrate that CMIF reduces additional inference overhead in TEEs while preserving user data privacy.
An U-Net-Based Deep Neural Network for Cloud Shadow and Sun-Glint Correction of Unmanned Aerial System (UAS) Imagery
Sep 10, 2025The use of unmanned aerial systems (UASs) has increased tremendously in the current decade. They have significantly advanced remote sensing with the capability to deploy and image the terrain as per required spatial, spectral, temporal, and radiometric resolutions for various remote sensing applications. One of the major advantages of UAS imagery is that images can be acquired in cloudy conditions by flying the UAS under the clouds. The limitation to the technology is that the imagery is often sullied by cloud shadows. Images taken over water are additionally affected by sun glint. These are two pose serious issues for estimating water quality parameters from the UAS images. This study proposes a novel machine learning approach first to identify and extract regions with cloud shadows and sun glint and separate such regions from non-obstructed clear sky regions and sun-glint unaffected regions. The data was extracted from the images at pixel level to train an U-Net based deep learning model and best settings for model training was identified based on the various evaluation metrics from test cases. Using this evaluation, a high-quality image correction model was determined, which was used to recover the cloud shadow and sun glint areas in the images.
Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning
Aug 28, 2025Recent advancements highlight the importance of GRPO-based reinforcement learning methods and benchmarking in enhancing text-to-image (T2I) generation. However, current methods using pointwise reward models (RM) for scoring generated images are susceptible to reward hacking. We reveal that this happens when minimal score differences between images are amplified after normalization, creating illusory advantages that drive the model to over-optimize for trivial gains, ultimately destabilizing the image generation process. To address this, we propose Pref-GRPO, a pairwise preference reward-based GRPO method that shifts the optimization objective from score maximization to preference fitting, ensuring more stable training. In Pref-GRPO, images are pairwise compared within each group using preference RM, and the win rate is used as the reward signal. Extensive experiments demonstrate that PREF-GRPO differentiates subtle image quality differences, providing more stable advantages and mitigating reward hacking. Additionally, existing T2I benchmarks are limited by coarse evaluation criteria, hindering comprehensive model assessment. To solve this, we introduce UniGenBench, a unified T2I benchmark comprising 600 prompts across 5 main themes and 20 subthemes. It evaluates semantic consistency through 10 primary and 27 sub-criteria, leveraging MLLM for benchmark construction and evaluation. Our benchmarks uncover the strengths and weaknesses of both open and closed-source T2I models and validate the effectiveness of Pref-GRPO.