 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPERA: Online Data Pruning for Efficient Retrieval Model Adaptation
Mar 17, 2026Domain-specific finetuning is essential for dense retrievers, yet not all training pairs contribute equally to the learning process. We introduce OPERA, a data pruning framework that exploits this heterogeneity to improve both the effectiveness and efficiency of retrieval model adaptation. We first investigate static pruning (SP), which retains only high-similarity query-document pairs, revealing an intrinsic quality-coverage tradeoff: ranking (NDCG) improves while retrieval (Recall) can degrade due to reduced query diversity. To resolve this tradeoff, we propose a two-stage dynamic pruning (DP) strategy that adaptively modulates sampling probabilities at both query and document levels throughout training, prioritizing high-quality examples while maintaining access to the full training set. Evaluations across eight datasets spanning six domains demonstrate the effectiveness of both approaches: SP improves ranking over standard finetuning (NDCG@10 +0.5\%), while DP achieves the strongest performance on both ranking (NDCG@10 +1.9\%) and retrieval (Recall@20 +0.7\%), with an average rank of 1.38 across all methods. These findings scale to Qwen3-Embedding, an LLM-based dense retriever, confirming architecture-agnostic benefits. Notably, DP reaches comparable performance in less than 50\% of the training time required by standard finetuning.
Causal Decoding for Hallucination-Resistant Multimodal Large Language Models
Feb 24, 2026Multimodal Large Language Models (MLLMs) deliver detailed responses on vision-language tasks, yet remain susceptible to object hallucination (introducing objects not present in the image), undermining reliability in practice. Prior efforts often rely on heuristic penalties, post-hoc correction, or generic decoding tweaks, which do not directly intervene in the mechanisms that trigger object hallucination and thus yield limited gains. To address this challenge, we propose a causal decoding framework that applies targeted causal interventions during generation to curb spurious object mentions. By reshaping the decoding dynamics to attenuate spurious dependencies, our approach reduces false object tokens while maintaining descriptive quality. Across captioning and QA benchmarks, our framework substantially lowers object-hallucination rates and achieves state-of-the-art faithfulness without degrading overall output quality.
Allocentric Perceiver: Disentangling Allocentric Reasoning from Egocentric Visual Priors via Frame Instantiation
Feb 05, 2026With the rising need for spatially grounded tasks such as Vision-Language Navigation/Action, allocentric perception capabilities in Vision-Language Models (VLMs) are receiving growing focus. However, VLMs remain brittle on allocentric spatial queries that require explicit perspective shifts, where the answer depends on reasoning in a target-centric frame rather than the observed camera view. Thus, we introduce Allocentric Perceiver, a training-free strategy that recovers metric 3D states from one or more images with off-the-shelf geometric experts, and then instantiates a query-conditioned allocentric reference frame aligned with the instruction's semantic intent. By deterministically transforming reconstructed geometry into the target frame and prompting the backbone VLM with structured, geometry-grounded representations, Allocentric Perceriver offloads mental rotation from implicit reasoning to explicit computation. We evaluate Allocentric Perciver across multiple backbone families on spatial reasoning benchmarks, observing consistent and substantial gains ($\sim$10%) on allocentric tasks while maintaining strong egocentric performance, and surpassing both spatial-perception-finetuned models and state-of-the-art open-source and proprietary models.
FreeText: Training-Free Text Rendering in Diffusion Transformers via Attention Localization and Spectral Glyph Injection
Jan 02, 2026Large-scale text-to-image (T2I) diffusion models excel at open-domain synthesis but still struggle with precise text rendering, especially for multi-line layouts, dense typography, and long-tailed scripts such as Chinese. Prior solutions typically require costly retraining or rigid external layout constraints, which can degrade aesthetics and limit flexibility. We propose \textbf{FreeText}, a training-free, plug-and-play framework that improves text rendering by exploiting intrinsic mechanisms of \emph{Diffusion Transformer (DiT)} models. \textbf{FreeText} decomposes the problem into \emph{where to write} and \emph{what to write}. For \emph{where to write}, we localize writing regions by reading token-wise spatial attribution from endogenous image-to-text attention, using sink-like tokens as stable spatial anchors and topology-aware refinement to produce high-confidence masks. For \emph{what to write}, we introduce Spectral-Modulated Glyph Injection (SGMI), which injects a noise-aligned glyph prior with frequency-domain band-pass modulation to strengthen glyph structure and suppress semantic leakage (rendering the concept instead of the word). Extensive experiments on Qwen-Image, FLUX.1-dev, and SD3 variants across longText-Benchmark, CVTG, and our CLT-Bench show consistent gains in text readability while largely preserving semantic alignment and aesthetic quality, with modest inference overhead.
AuthSig: Safeguarding Scanned Signatures Against Unauthorized Reuse in Paperless Workflows
Nov 12, 2025With the deepening trend of paperless workflows, signatures as a means of identity authentication are gradually shifting from traditional ink-on-paper to electronic formats.Despite the availability of dynamic pressure-sensitive and PKI-based digital signatures, static scanned signatures remain prevalent in practice due to their convenience. However, these static images, having almost lost their authentication attributes, cannot be reliably verified and are vulnerable to malicious copying and reuse. To address these issues, we propose AuthSig, a novel static electronic signature framework based on generative models and watermark, which binds authentication information to the signature image. Leveraging the human visual system's insensitivity to subtle style variations, AuthSig finely modulates style embeddings during generation to implicitly encode watermark bits-enforcing a One Signature, One Use policy.To overcome the scarcity of handwritten signature data and the limitations of traditional augmentation methods, we introduce a keypoint-driven data augmentation strategy that effectively enhances style diversity to support robust watermark embedding. Experimental results show that AuthSig achieves over 98% extraction accuracy under both digital-domain distortions and signature-specific degradations, and remains effective even in print-scan scenarios.
LaVA-Man: Learning Visual Action Representations for Robot Manipulation
Aug 26, 2025Visual-textual understanding is essential for language-guided robot manipulation. Recent works leverage pre-trained vision-language models to measure the similarity between encoded visual observations and textual instructions, and then train a model to map this similarity to robot actions. However, this two-step approach limits the model to capture the relationship between visual observations and textual instructions, leading to reduced precision in manipulation tasks. We propose to learn visual-textual associations through a self-supervised pretext task: reconstructing a masked goal image conditioned on an input image and textual instructions. This formulation allows the model to learn visual-action representations without robot action supervision. The learned representations can then be fine-tuned for manipulation tasks with only a few demonstrations. We also introduce the \textit{Omni-Object Pick-and-Place} dataset, which consists of annotated robot tabletop manipulation episodes, including 180 object classes and 3,200 instances with corresponding textual instructions. This dataset enables the model to acquire diverse object priors and allows for a more comprehensive evaluation of its generalisation capability across object instances. Experimental results on the five benchmarks, including both simulated and real-robot validations, demonstrate that our method outperforms prior art.
Token-Level Uncertainty Estimation for Large Language Model Reasoning
May 16, 2025While Large Language Models (LLMs) have demonstrated impressive capabilities, their output quality remains inconsistent across various application scenarios, making it difficult to identify trustworthy responses, especially in complex tasks requiring multi-step reasoning. In this paper, we propose a token-level uncertainty estimation framework to enable LLMs to self-assess and self-improve their generation quality in mathematical reasoning. Specifically, we introduce low-rank random weight perturbation to LLM decoding, generating predictive distributions that we use to estimate token-level uncertainties. We then aggregate these uncertainties to reflect semantic uncertainty of the generated sequences. Experiments on mathematical reasoning datasets of varying difficulty demonstrate that our token-level uncertainty metrics strongly correlate with answer correctness and model robustness. Additionally, we explore using uncertainty to directly enhance the model's reasoning performance through multiple generations and the particle filtering algorithm. Our approach consistently outperforms existing uncertainty estimation methods, establishing effective uncertainty estimation as a valuable tool for both evaluating and improving reasoning generation in LLMs.
Variational Language Concepts for Interpreting Foundation Language Models
Oct 04, 2024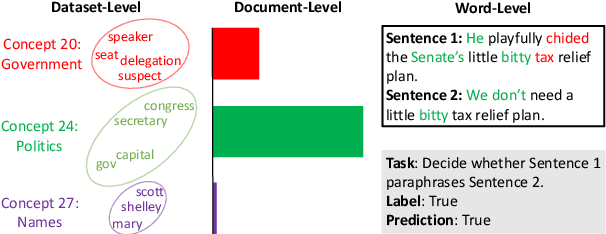

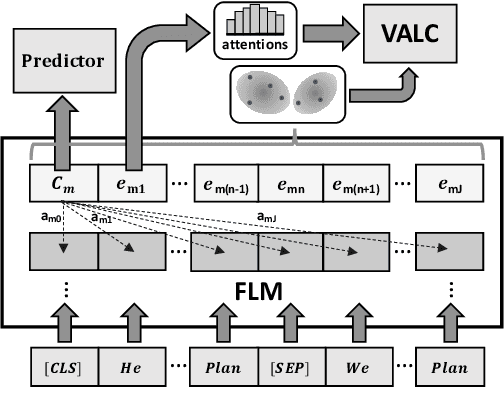
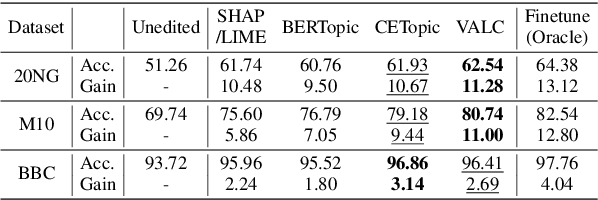
Foundation Language Models (FLMs) such as BERT and its variants have achieved remarkable success in natural language processing. To date, the interpretability of FLMs has primarily relied on the attention weights in their self-attention layers. However, these attention weights only provide word-level interpretations, failing to capture higher-level structures, and are therefore lacking in readability and intuitiveness. To address this challenge, we first provide a formal definition of conceptual interpretation and then propose a variational Bayesian framework, dubbed VAriational Language Concept (VALC), to go beyond word-level interpretations and provide concept-level interpretations. Our theoretical analysis shows that our VALC finds the optimal language concepts to interpret FLM predictions. Empirical results on several real-world datasets show that our method can successfully provide conceptual interpretation for FLMs.
3D Reconstruction with Spatial Memory
Aug 28, 2024We present Spann3R, a novel approach for dense 3D reconstruction from ordered or unordered image collections. Built on the DUSt3R paradigm, Spann3R uses a transformer-based architecture to directly regress pointmaps from images without any prior knowledge of the scene or camera parameters. Unlike DUSt3R, which predicts per image-pair pointmaps each expressed in its local coordinate frame, Spann3R can predict per-image pointmaps expressed in a global coordinate system, thus eliminating the need for optimization-based global alignment. The key idea of Spann3R is to manage an external spatial memory that learns to keep track of all previous relevant 3D information. Spann3R then queries this spatial memory to predict the 3D structure of the next frame in a global coordinate system. Taking advantage of DUSt3R's pre-trained weights, and further fine-tuning on a subset of datasets, Spann3R shows competitive performance and generalization ability on various unseen datasets and can process ordered image collections in real time. Project page: \url{https://hengyiwang.github.io/projects/spanner}
Probabilistic Conceptual Explainers: Trustworthy Conceptual Explanations for Vision Foundation Models
Jun 18, 2024Vision transformers (ViTs) have emerged as a significant area of focus, particularly for their capacity to be jointly trained with large language models and to serve as robust vision foundation models. Yet, the development of trustworthy explanation methods for ViTs has lagged, particularly in the context of post-hoc interpretations of ViT predictions. Existing sub-image selection approaches, such as feature-attribution and conceptual models, fall short in this regard. This paper proposes five desiderata for explaining ViTs -- faithfulness, stability, sparsity, multi-level structure, and parsimony -- and demonstrates the inadequacy of current methods in meeting these criteria comprehensively. We introduce a variational Bayesian explanation framework, dubbed ProbAbilistic Concept Explainers (PACE), which models the distributions of patch embeddings to provide trustworthy post-hoc conceptual explanations. Our qualitative analysis reveals the distributions of patch-level concepts, elucidating the effectiveness of ViTs by modeling the joint distribution of patch embeddings and ViT's predictions. Moreover, these patch-level explanations bridge the gap between image-level and dataset-level explanations, thus completing the multi-level structure of PACE. Through extensive experiments on both synthetic and real-world datasets, we demonstrate that PACE surpasses state-of-the-art methods in terms of the defined desiderata.