 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmazon Nova AI Challenge -- Trusted AI: Advancing secure, AI-assisted software development
Aug 13, 2025AI systems for software development are rapidly gaining prominence, yet significant challenges remain in ensuring their safety. To address this, Amazon launched the Trusted AI track of the Amazon Nova AI Challenge, a global competition among 10 university teams to drive advances in secure AI. In the challenge, five teams focus on developing automated red teaming bots, while the other five create safe AI assistants. This challenge provides teams with a unique platform to evaluate automated red-teaming and safety alignment methods through head-to-head adversarial tournaments where red teams have multi-turn conversations with the competing AI coding assistants to test their safety alignment. Along with this, the challenge provides teams with a feed of high quality annotated data to fuel iterative improvement. Throughout the challenge, teams developed state-of-the-art techniques, introducing novel approaches in reasoning-based safety alignment, robust model guardrails, multi-turn jail-breaking, and efficient probing of large language models (LLMs). To support these efforts, the Amazon Nova AI Challenge team made substantial scientific and engineering investments, including building a custom baseline coding specialist model for the challenge from scratch, developing a tournament orchestration service, and creating an evaluation harness. This paper outlines the advancements made by university teams and the Amazon Nova AI Challenge team in addressing the safety challenges of AI for software development, highlighting this collaborative effort to raise the bar for AI safety.
AddrLLM: Address Rewriting via Large Language Model on Nationwide Logistics Data
Nov 17, 2024



Textual description of a physical location, commonly known as an address, plays an important role in location-based services(LBS) such as on-demand delivery and navigation. However, the prevalence of abnormal addresses, those containing inaccuracies that fail to pinpoint a location, have led to significant costs. Address rewriting has emerged as a solution to rectify these abnormal addresses. Despite the critical need, existing address rewriting methods are limited, typically tailored to correct specific error types, or frequently require retraining to process new address data effectively. In this study, we introduce AddrLLM, an innovative framework for address rewriting that is built upon a retrieval augmented large language model. AddrLLM overcomes aforementioned limitations through a meticulously designed Supervised Fine-Tuning module, an Address-centric Retrieval Augmented Generation module and a Bias-free Objective Alignment module. To the best of our knowledge, this study pioneers the application of LLM-based address rewriting approach to solve the issue of abnormal addresses. Through comprehensive offline testing with real-world data on a national scale and subsequent online deployment, AddrLLM has demonstrated superior performance in integration with existing logistics system. It has significantly decreased the rate of parcel re-routing by approximately 43\%, underscoring its exceptional efficacy in real-world applications.
InLINE: Inner-Layer Information Exchange for Multi-task Learning on Heterogeneous Graphs
Oct 29, 2024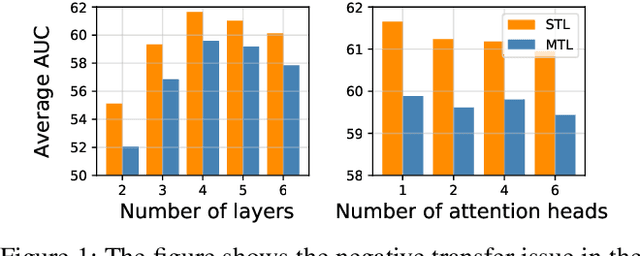
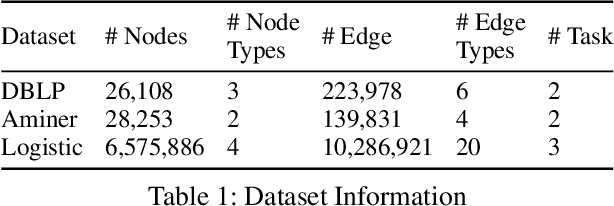
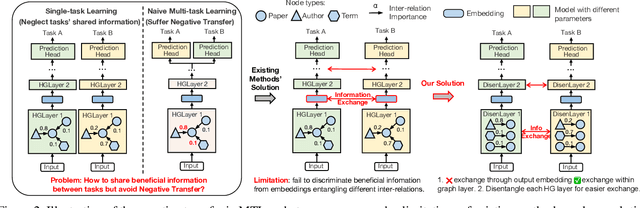
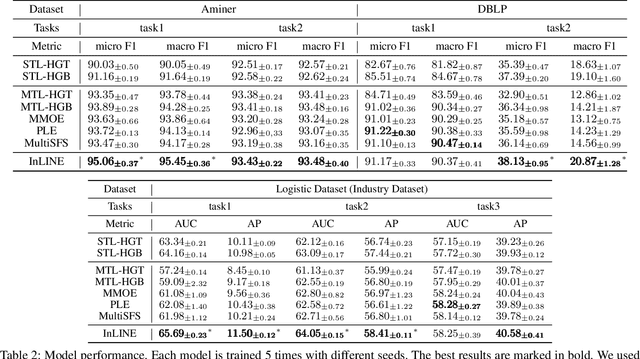
Heterogeneous graph is an important structure for modeling complex relational data in real-world scenarios and usually involves various node prediction tasks within a single graph. Training these tasks separately may neglect beneficial information sharing, hence a preferred way is to learn several tasks in a same model by Multi-Task Learning (MTL). However, MTL introduces the issue of negative transfer, where the training of different tasks interferes with each other as they may focus on different information from the data, resulting in suboptimal performance. To solve the issue, existing MTL methods use separate backbones for each task, then selectively exchange beneficial features through interactions among the output embeddings from each layer of different backbones, which we refer to as outer-layer exchange. However, the negative transfer in heterogeneous graphs arises not simply from the varying importance of an individual node feature across tasks, but also from the varying importance of inter-relation between two nodes across tasks. These inter-relations are entangled in the output embedding, making it difficult for existing methods to discriminate beneficial information from the embedding. To address this challenge, we propose the Inner-Layer Information Exchange (InLINE) model that facilitate fine-grained information exchanges within each graph layer rather than through output embeddings. Specifically, InLINE consists of (1) Structure Disentangled Experts for layer-wise structure disentanglement, (2) Structure Disentangled Gates for assigning disentangled information to different tasks. Evaluations on two public datasets and a large industry dataset show that our model effectively alleviates the significant performance drop on specific tasks caused by negative transfer, improving Macro F1 by 6.3% on DBLP dataset and AUC by 3.6% on the industry dataset compared to SoA methods.
Variational Language Concepts for Interpreting Foundation Language Models
Oct 04, 2024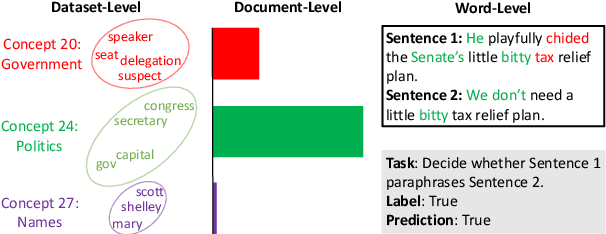

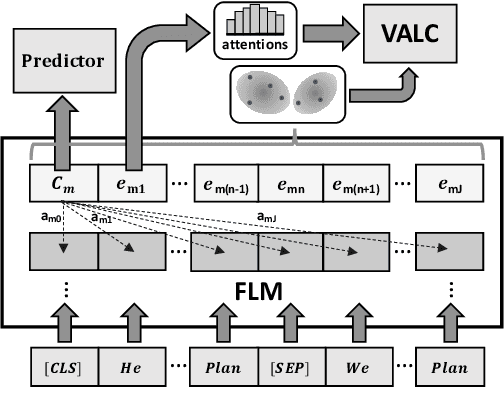
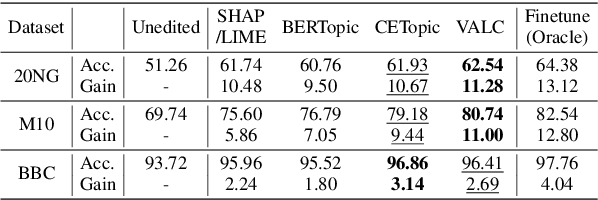
Foundation Language Models (FLMs) such as BERT and its variants have achieved remarkable success in natural language processing. To date, the interpretability of FLMs has primarily relied on the attention weights in their self-attention layers. However, these attention weights only provide word-level interpretations, failing to capture higher-level structures, and are therefore lacking in readability and intuitiveness. To address this challenge, we first provide a formal definition of conceptual interpretation and then propose a variational Bayesian framework, dubbed VAriational Language Concept (VALC), to go beyond word-level interpretations and provide concept-level interpretations. Our theoretical analysis shows that our VALC finds the optimal language concepts to interpret FLM predictions. Empirical results on several real-world datasets show that our method can successfully provide conceptual interpretation for FLMs.
MalLight: Influence-Aware Coordinated Traffic Signal Control for Traffic Signal Malfunctions
Aug 20, 2024



Urban traffic is subject to disruptions that cause extended waiting time and safety issues at signalized intersections. While numerous studies have addressed the issue of intelligent traffic systems in the context of various disturbances, traffic signal malfunction, a common real-world occurrence with significant repercussions, has received comparatively limited attention. The primary objective of this research is to mitigate the adverse effects of traffic signal malfunction, such as traffic congestion and collision, by optimizing the control of neighboring functioning signals. To achieve this goal, this paper presents a novel traffic signal control framework (MalLight), which leverages an Influence-aware State Aggregation Module (ISAM) and an Influence-aware Reward Aggregation Module (IRAM) to achieve coordinated control of surrounding traffic signals. To the best of our knowledge, this study pioneers the application of a Reinforcement Learning(RL)-based approach to address the challenges posed by traffic signal malfunction. Empirical investigations conducted on real-world datasets substantiate the superior performance of our proposed methodology over conventional and deep learning-based alternatives in the presence of signal malfunction, with reduction of throughput alleviated by as much as 48.6$\%$.
Where have you been? A Study of Privacy Risk for Point-of-Interest Recommendation
Oct 28, 2023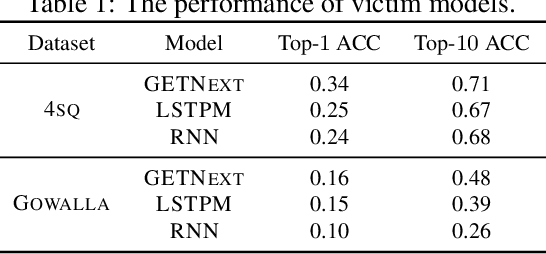
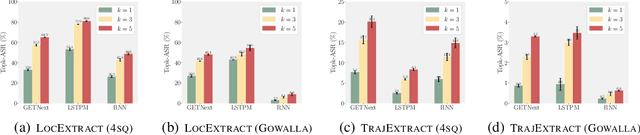
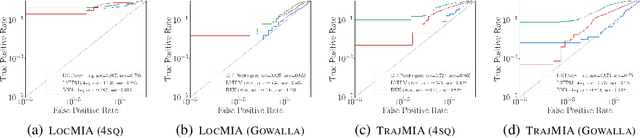

As location-based services (LBS) have grown in popularity, the collection of human mobility data has become increasingly extensive to build machine learning (ML) models offering enhanced convenience to LBS users. However, the convenience comes with the risk of privacy leakage since this type of data might contain sensitive information related to user identities, such as home/work locations. Prior work focuses on protecting mobility data privacy during transmission or prior to release, lacking the privacy risk evaluation of mobility data-based ML models. To better understand and quantify the privacy leakage in mobility data-based ML models, we design a privacy attack suite containing data extraction and membership inference attacks tailored for point-of-interest (POI) recommendation models, one of the most widely used mobility data-based ML models. These attacks in our attack suite assume different adversary knowledge and aim to extract different types of sensitive information from mobility data, providing a holistic privacy risk assessment for POI recommendation models. Our experimental evaluation using two real-world mobility datasets demonstrates that current POI recommendation models are vulnerable to our attacks. We also present unique findings to understand what types of mobility data are more susceptible to privacy attacks. Finally, we evaluate defenses against these attacks and highlight future directions and challenges.
Alexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023



The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
Data-Driven Distributionally Robust Electric Vehicle Balancing for Autonomous Mobility-on-Demand Systems under Demand and Supply Uncertainties
Nov 24, 2022
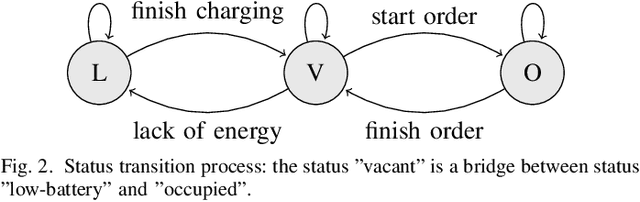
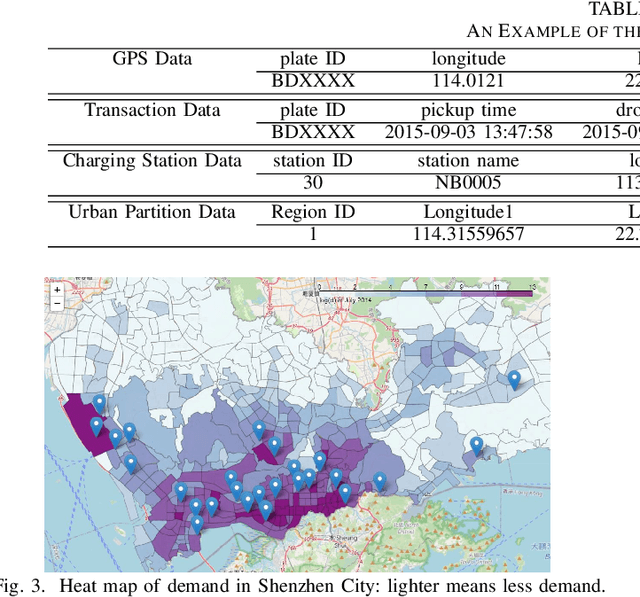
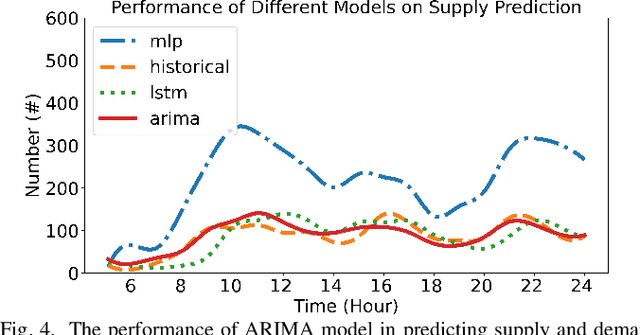
Electric vehicles (EVs) are being rapidly adopted due to their economic and societal benefits. Autonomous mobility-on-demand (AMoD) systems also embrace this trend. However, the long charging time and high recharging frequency of EVs pose challenges to efficiently managing EV AMoD systems. The complicated dynamic charging and mobility process of EV AMoD systems makes the demand and supply uncertainties significant when designing vehicle balancing algorithms. In this work, we design a data-driven distributionally robust optimization (DRO) approach to balance EVs for both the mobility service and the charging process. The optimization goal is to minimize the worst-case expected cost under both passenger mobility demand uncertainties and EV supply uncertainties. We then propose a novel distributional uncertainty sets construction algorithm that guarantees the produced parameters are contained in desired confidence regions with a given probability. To solve the proposed DRO AMoD EV balancing problem, we derive an equivalent computationally tractable convex optimization problem. Based on real-world EV data of a taxi system, we show that with our solution the average total balancing cost is reduced by 14.49%, and the average mobility fairness and charging fairness are improved by 15.78% and 34.51%, respectively, compared to solutions that do not consider uncertainties.
Data-Driven Distributionally Robust Electric Vehicle Balancing for Mobility-on-Demand Systems under Demand and Supply Uncertainties
Oct 19, 2022



As electric vehicle (EV) technologies become mature, EV has been rapidly adopted in modern transportation systems, and is expected to provide future autonomous mobility-on-demand (AMoD) service with economic and societal benefits. However, EVs require frequent recharges due to their limited and unpredictable cruising ranges, and they have to be managed efficiently given the dynamic charging process. It is urgent and challenging to investigate a computationally efficient algorithm that provide EV AMoD system performance guarantees under model uncertainties, instead of using heuristic demand or charging models. To accomplish this goal, this work designs a data-driven distributionally robust optimization approach for vehicle supply-demand ratio and charging station utilization balancing, while minimizing the worst-case expected cost considering both passenger mobility demand uncertainties and EV supply uncertainties. We then derive an equivalent computationally tractable form for solving the distributionally robust problem in a computationally efficient way under ellipsoid uncertainty sets constructed from data. Based on E-taxi system data of Shenzhen city, we show that the average total balancing cost is reduced by 14.49%, the average unfairness of supply-demand ratio and utilization is reduced by 15.78% and 34.51% respectively with the distributionally robust vehicle balancing method, compared with solutions which do not consider model uncertainties.
Alexa, Let's Work Together: Introducing the First Alexa Prize TaskBot Challenge on Conversational Task Assistance
Sep 13, 2022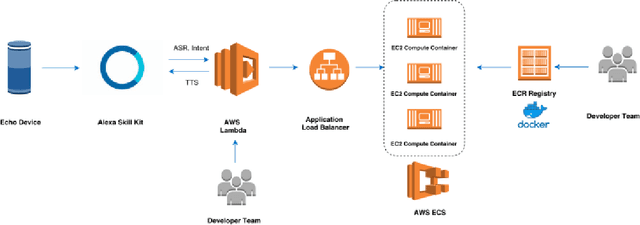
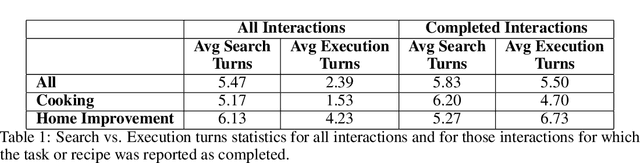
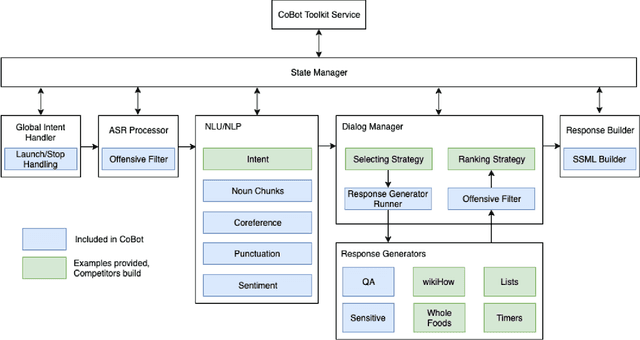

Since its inception in 2016, the Alexa Prize program has enabled hundreds of university students to explore and compete to develop conversational agents through the SocialBot Grand Challenge. The goal of the challenge is to build agents capable of conversing coherently and engagingly with humans on popular topics for 20 minutes, while achieving an average rating of at least 4.0/5.0. However, as conversational agents attempt to assist users with increasingly complex tasks, new conversational AI techniques and evaluation platforms are needed. The Alexa Prize TaskBot challenge, established in 2021, builds on the success of the SocialBot challenge by introducing the requirements of interactively assisting humans with real-world Cooking and Do-It-Yourself tasks, while making use of both voice and visual modalities. This challenge requires the TaskBots to identify and understand the user's need, identify and integrate task and domain knowledge into the interaction, and develop new ways of engaging the user without distracting them from the task at hand, among other challenges. This paper provides an overview of the TaskBot challenge, describes the infrastructure support provided to the teams with the CoBot Toolkit, and summarizes the approaches the participating teams took to overcome the research challenges. Finally, it analyzes the performance of the competing TaskBots during the first year of the competition.