 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Adaptation for Critic Learning in Off-Policy Reinforcement Learning
Apr 21, 2026Scaling critic capacity is a promising direction for enhancing off-policy reinforcement learning (RL). However, larger critics are prone to overfitting and unstable in replay-buffer-based bootstrap training. This paper leverages Low-Rank Adaptation (LoRA) as a structural-sparsity regularizer for off-policy critics. Our approach freezes randomly initialized base matrices and solely optimizes low-rank adapters, thereby constraining critic updates to a low-dimensional subspace. Built on top of SimbaV2, we further develop a LoRA formulation, compatible with SimbaV2, that preserves its hyperspherical normalization geometry under frozen-backbone training. We evaluate our method with SAC and FastTD3 on DeepMind Control locomotion and IsaacLab robotics benchmarks. LoRA consistently achieves lower critic loss during training and stronger policy performance. Extensive experiments demonstrate that adaptive low-rank updates provide a simple, scalable, and effective structural regularization for critic learning in off-policy RL.
Pessimism Principle Can Be Effective: Towards a Framework for Zero-Shot Transfer Reinforcement Learning
May 24, 2025Transfer reinforcement learning aims to derive a near-optimal policy for a target environment with limited data by leveraging abundant data from related source domains. However, it faces two key challenges: the lack of performance guarantees for the transferred policy, which can lead to undesired actions, and the risk of negative transfer when multiple source domains are involved. We propose a novel framework based on the pessimism principle, which constructs and optimizes a conservative estimation of the target domain's performance. Our framework effectively addresses the two challenges by providing an optimized lower bound on target performance, ensuring safe and reliable decisions, and by exhibiting monotonic improvement with respect to the quality of the source domains, thereby avoiding negative transfer. We construct two types of conservative estimations, rigorously characterize their effectiveness, and develop efficient distributed algorithms with convergence guarantees. Our framework provides a theoretically sound and practically robust solution for transfer learning in reinforcement learning.
Adaptive Uncertainty Quantification for Trajectory Prediction Under Distributional Shift
Jun 17, 2024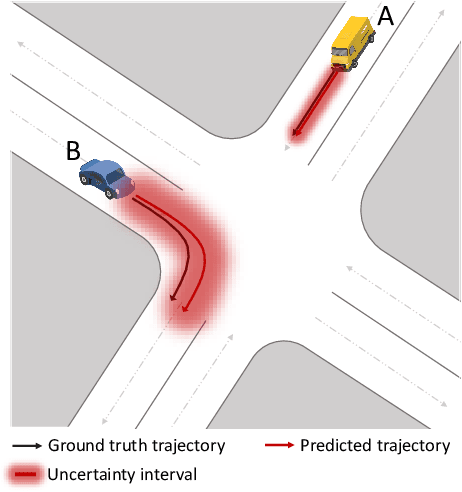

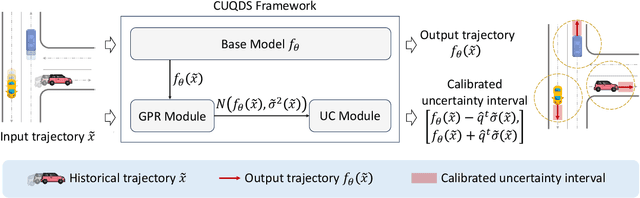

Trajectory prediction models that can infer both finite future trajectories and their associated uncertainties of the target vehicles in an online setting (e.g., real-world application scenarios) is crucial for ensuring the safe and robust navigation and path planning of autonomous vehicle motion. However, the majority of existing trajectory prediction models have neither considered reducing the uncertainty as one objective during the training stage nor provided reliable uncertainty quantification during inference stage under potential distribution shift. Therefore, in this paper, we propose the Conformal Uncertainty Quantification under Distribution Shift framework, CUQDS, to quantify the uncertainty of the predicted trajectories of existing trajectory prediction models under potential data distribution shift, while considering improving the prediction accuracy of the models and reducing the estimated uncertainty during the training stage. Specifically, CUQDS includes 1) a learning-based Gaussian process regression module that models the output distribution of the base model (any existing trajectory prediction or time series forecasting neural networks) and reduces the estimated uncertainty by additional loss term, and 2) a statistical-based Conformal P control module to calibrate the estimated uncertainty from the Gaussian process regression module in an online setting under potential distribution shift between training and testing data.
Deconstructing The Ethics of Large Language Models from Long-standing Issues to New-emerging Dilemmas
Jun 08, 2024


Large Language Models (LLMs) have achieved unparalleled success across diverse language modeling tasks in recent years. However, this progress has also intensified ethical concerns, impacting the deployment of LLMs in everyday contexts. This paper provides a comprehensive survey of ethical challenges associated with LLMs, from longstanding issues such as copyright infringement, systematic bias, and data privacy, to emerging problems like truthfulness and social norms. We critically analyze existing research aimed at understanding, examining, and mitigating these ethical risks. Our survey underscores integrating ethical standards and societal values into the development of LLMs, thereby guiding the development of responsible and ethically aligned language models.
Are Large Language Models Chameleons?
May 29, 2024


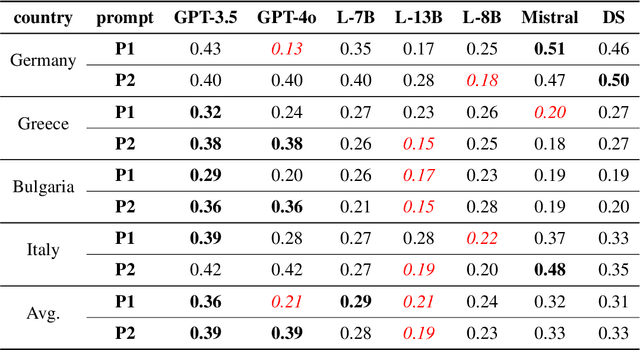
Do large language models (LLMs) have their own worldviews and personality tendencies? Simulations in which an LLM was asked to answer subjective questions were conducted more than 1 million times. Comparison of the responses from different LLMs with real data from the European Social Survey (ESS) suggests that the effect of prompts on bias and variability is fundamental, highlighting major cultural, age, and gender biases. Methods for measuring the difference between LLMs and survey data are discussed, such as calculating weighted means and a new proposed measure inspired by Jaccard similarity. We conclude that it is important to analyze the robustness and variability of prompts before using LLMs to model individual decisions or collective behavior, as their imitation abilities are approximate at best.
Momentum for the Win: Collaborative Federated Reinforcement Learning across Heterogeneous Environments
May 29, 2024



We explore a Federated Reinforcement Learning (FRL) problem where $N$ agents collaboratively learn a common policy without sharing their trajectory data. To date, existing FRL work has primarily focused on agents operating in the same or ``similar" environments. In contrast, our problem setup allows for arbitrarily large levels of environment heterogeneity. To obtain the optimal policy which maximizes the average performance across all potentially completely different environments, we propose two algorithms: FedSVRPG-M and FedHAPG-M. In contrast to existing results, we demonstrate that both FedSVRPG-M and FedHAPG-M, both of which leverage momentum mechanisms, can exactly converge to a stationary point of the average performance function, regardless of the magnitude of environment heterogeneity. Furthermore, by incorporating the benefits of variance-reduction techniques or Hessian approximation, both algorithms achieve state-of-the-art convergence results, characterized by a sample complexity of $\mathcal{O}\left(\epsilon^{-\frac{3}{2}}/N\right)$. Notably, our algorithms enjoy linear convergence speedups with respect to the number of agents, highlighting the benefit of collaboration among agents in finding a common policy.
Constrained Reinforcement Learning Under Model Mismatch
May 02, 2024



Existing studies on constrained reinforcement learning (RL) may obtain a well-performing policy in the training environment. However, when deployed in a real environment, it may easily violate constraints that were originally satisfied during training because there might be model mismatch between the training and real environments. To address the above challenge, we formulate the problem as constrained RL under model uncertainty, where the goal is to learn a good policy that optimizes the reward and at the same time satisfy the constraint under model mismatch. We develop a Robust Constrained Policy Optimization (RCPO) algorithm, which is the first algorithm that applies to large/continuous state space and has theoretical guarantees on worst-case reward improvement and constraint violation at each iteration during the training. We demonstrate the effectiveness of our algorithm on a set of RL tasks with constraints.
Robust Multi-Agent Reinforcement Learning with State Uncertainty
Jul 30, 2023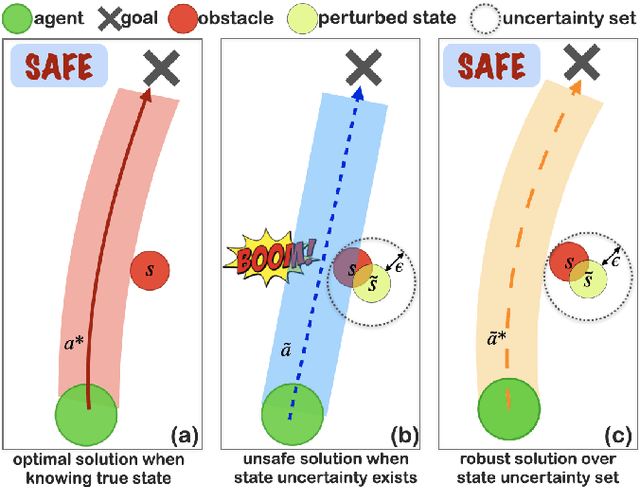

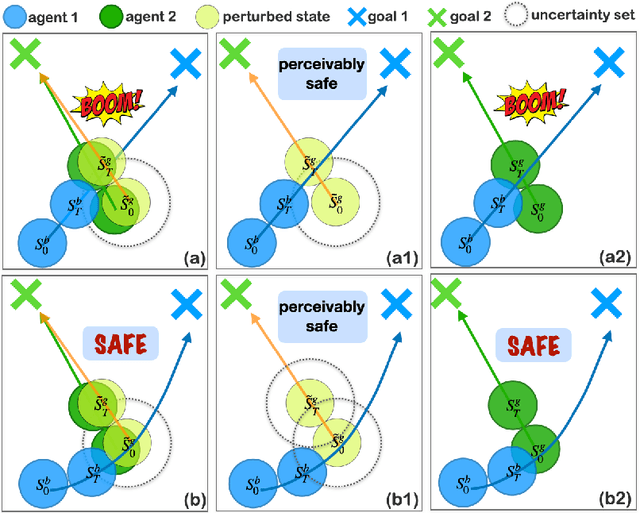

In real-world multi-agent reinforcement learning (MARL) applications, agents may not have perfect state information (e.g., due to inaccurate measurement or malicious attacks), which challenges the robustness of agents' policies. Though robustness is getting important in MARL deployment, little prior work has studied state uncertainties in MARL, neither in problem formulation nor algorithm design. Motivated by this robustness issue and the lack of corresponding studies, we study the problem of MARL with state uncertainty in this work. We provide the first attempt to the theoretical and empirical analysis of this challenging problem. We first model the problem as a Markov Game with state perturbation adversaries (MG-SPA) by introducing a set of state perturbation adversaries into a Markov Game. We then introduce robust equilibrium (RE) as the solution concept of an MG-SPA. We conduct a fundamental analysis regarding MG-SPA such as giving conditions under which such a robust equilibrium exists. Then we propose a robust multi-agent Q-learning (RMAQ) algorithm to find such an equilibrium, with convergence guarantees. To handle high-dimensional state-action space, we design a robust multi-agent actor-critic (RMAAC) algorithm based on an analytical expression of the policy gradient derived in the paper. Our experiments show that the proposed RMAQ algorithm converges to the optimal value function; our RMAAC algorithm outperforms several MARL and robust MARL methods in multiple multi-agent environments when state uncertainty is present. The source code is public on \url{https://github.com/sihongho/robust_marl_with_state_uncertainty}.
Robust Electric Vehicle Balancing of Autonomous Mobility-On-Demand System: A Multi-Agent Reinforcement Learning Approach
Jul 30, 2023



Electric autonomous vehicles (EAVs) are getting attention in future autonomous mobility-on-demand (AMoD) systems due to their economic and societal benefits. However, EAVs' unique charging patterns (long charging time, high charging frequency, unpredictable charging behaviors, etc.) make it challenging to accurately predict the EAVs supply in E-AMoD systems. Furthermore, the mobility demand's prediction uncertainty makes it an urgent and challenging task to design an integrated vehicle balancing solution under supply and demand uncertainties. Despite the success of reinforcement learning-based E-AMoD balancing algorithms, state uncertainties under the EV supply or mobility demand remain unexplored. In this work, we design a multi-agent reinforcement learning (MARL)-based framework for EAVs balancing in E-AMoD systems, with adversarial agents to model both the EAVs supply and mobility demand uncertainties that may undermine the vehicle balancing solutions. We then propose a robust E-AMoD Balancing MARL (REBAMA) algorithm to train a robust EAVs balancing policy to balance both the supply-demand ratio and charging utilization rate across the whole city. Experiments show that our proposed robust method performs better compared with a non-robust MARL method that does not consider state uncertainties; it improves the reward, charging utilization fairness, and supply-demand fairness by 19.28%, 28.18%, and 3.97%, respectively. Compared with a robust optimization-based method, the proposed MARL algorithm can improve the reward, charging utilization fairness, and supply-demand fairness by 8.21%, 8.29%, and 9.42%, respectively.
What is the Solution for State-Adversarial Multi-Agent Reinforcement Learning?
Dec 07, 2022



Various types of Multi-Agent Reinforcement Learning (MARL) methods have been developed, assuming that agents' policies are based on true states. Recent works have improved the robustness of MARL under uncertainties from the reward, transition probability, or other partners' policies. However, in real-world multi-agent systems, state estimations may be perturbed by sensor measurement noise or even adversaries. Agents' policies trained with only true state information will deviate from optimal solutions when facing adversarial state perturbations during execution. MARL under adversarial state perturbations has limited study. Hence, in this work, we propose a State-Adversarial Markov Game (SAMG) and make the first attempt to study the fundamental properties of MARL under state uncertainties. We prove that the optimal agent policy and the robust Nash equilibrium do not always exist for an SAMG. Instead, we define the solution concept, robust agent policy, of the proposed SAMG under adversarial state perturbations, where agents want to maximize the worst-case expected state value. We then design a gradient descent ascent-based robust MARL algorithm to learn the robust policies for the MARL agents. Our experiments show that adversarial state perturbations decrease agents' rewards for several baselines from the existing literature, while our algorithm outperforms baselines with state perturbations and significantly improves the robustness of the MARL policies under state uncertainties.