 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-dDrive: Efficient Block-Diffusion VLM for Autonomous Driving
May 25, 2026End-to-end autonomous driving via Vision-Language-Action (VLA) models demands a precarious balance between high-fidelity trajectory planning and efficient inference. Existing paradigms typically fall short: autoregressive (AR) VLAs are memory-bandwidth-bound on edge hardware and prone to exposure-bias drift, while full-sequence diffusion models preclude KV-cache reuse and suffer from "logical leakage" that violates the fundamental perceive-then-plan causality. We present Fast-dDrive, a block-diffusion VLA that performs bidirectional refinement within semantic units while enforcing strict causal ordering across them. Leveraging the observation that driving VLAs often emit structured JSON-like outputs, Fast-dDrive freezes structural tokens into a section scaffold and employs a section-aware training recipe that prioritizes safety-critical planning. We further introduce Scaffold Speculative Decoding to achieve AR-equivalent quality at significantly higher throughput. Finally, we propose a low-overhead test-time scaling scheme: by forking $N$ stochastic trajectory rollouts from a single shared-prefix KV cache and averaging them, we effectively suppress prediction variance at a fractional computational cost. Empirical results demonstrate that Fast-dDrive redefines the speed-accuracy frontier for driving agents. On the WOD-E2E test set, Fast-dDrive achieves SOTA ADE@3s and ADE@5s, alongside the highest RFS among diffusion-based VLAs; on nuScenes, it reduces average L2 error to $0.32$m (a $22\%$ improvement). When integrated with SGLang, our framework delivers $12\times$ throughput speedup over the AR baseline, narrowing the gap between high-capacity VLAs and the efficiency demands of real-time on-vehicle deployment.
Low-Rank Adaptation for Critic Learning in Off-Policy Reinforcement Learning
Apr 21, 2026Scaling critic capacity is a promising direction for enhancing off-policy reinforcement learning (RL). However, larger critics are prone to overfitting and unstable in replay-buffer-based bootstrap training. This paper leverages Low-Rank Adaptation (LoRA) as a structural-sparsity regularizer for off-policy critics. Our approach freezes randomly initialized base matrices and solely optimizes low-rank adapters, thereby constraining critic updates to a low-dimensional subspace. Built on top of SimbaV2, we further develop a LoRA formulation, compatible with SimbaV2, that preserves its hyperspherical normalization geometry under frozen-backbone training. We evaluate our method with SAC and FastTD3 on DeepMind Control locomotion and IsaacLab robotics benchmarks. LoRA consistently achieves lower critic loss during training and stronger policy performance. Extensive experiments demonstrate that adaptive low-rank updates provide a simple, scalable, and effective structural regularization for critic learning in off-policy RL.
ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents
Mar 19, 2026Multi-turn LLM agents are increasingly important for solving complex, interactive tasks, and reinforcement learning (RL) is a key ingredient for improving their long-horizon behavior. However, RL training requires generating large numbers of sandboxed rollout trajectories, and existing infrastructures often couple rollout orchestration with the training loop, making systems hard to migrate and maintain. Under the rollout-as-a-service philosophy, we present ProRL Agent , a scalable infrastructure that serves the full agentic rollout lifecycle through an API service. ProRL Agent also provides standardized and extensible sandbox environments that support diverse agentic tasks in rootless HPC settings. We validate ProRL Agent through RL training on software engineering, math, STEM, and coding tasks. ProRL Agent is open-sourced and integrated as part of NVIDIA NeMo Gym.
Empowering Multi-Turn Tool-Integrated Reasoning with Group Turn Policy Optimization
Nov 18, 2025
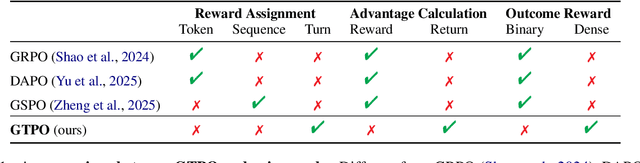
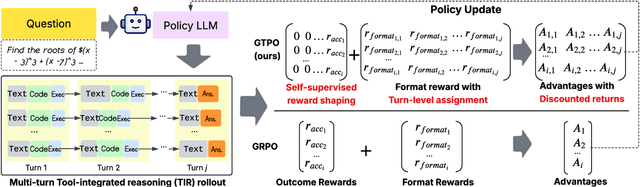
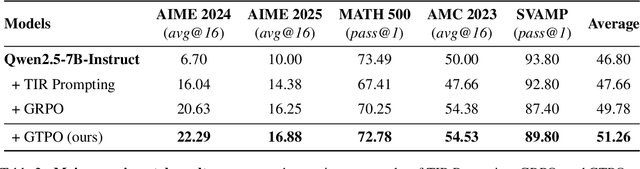
Training Large Language Models (LLMs) for multi-turn Tool-Integrated Reasoning (TIR) - where models iteratively reason, generate code, and verify through execution - remains challenging for existing reinforcement learning (RL) approaches. Current RL methods, exemplified by Group Relative Policy Optimization (GRPO), suffer from coarse-grained, trajectory-level rewards that provide insufficient learning signals for complex multi-turn interactions, leading to training stagnation. To address this issue, we propose Group Turn Policy Optimization (GTPO), a novel RL algorithm specifically designed for training LLMs on multi-turn TIR tasks. GTPO introduces three key innovations: (1) turn-level reward assignment that provides fine-grained feedback for individual turns, (2) return-based advantage estimation where normalized discounted returns are calculated as advantages, and (3) self-supervised reward shaping that exploits self-supervision signals from generated code to densify sparse binary outcome-based rewards. Our comprehensive evaluation demonstrates that GTPO outperforms GRPO by 3.0% on average across diverse reasoning benchmarks, establishing its effectiveness for advancing complex mathematical reasoning in the real world.
Robust Multi-Agent Reinforcement Learning with State Uncertainty
Jul 30, 2023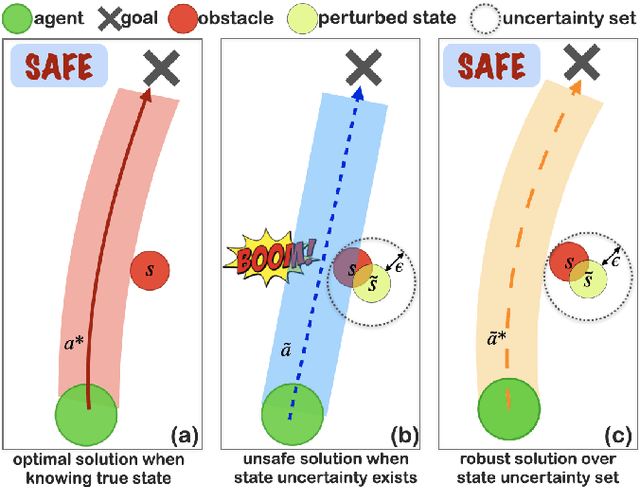


In real-world multi-agent reinforcement learning (MARL) applications, agents may not have perfect state information (e.g., due to inaccurate measurement or malicious attacks), which challenges the robustness of agents' policies. Though robustness is getting important in MARL deployment, little prior work has studied state uncertainties in MARL, neither in problem formulation nor algorithm design. Motivated by this robustness issue and the lack of corresponding studies, we study the problem of MARL with state uncertainty in this work. We provide the first attempt to the theoretical and empirical analysis of this challenging problem. We first model the problem as a Markov Game with state perturbation adversaries (MG-SPA) by introducing a set of state perturbation adversaries into a Markov Game. We then introduce robust equilibrium (RE) as the solution concept of an MG-SPA. We conduct a fundamental analysis regarding MG-SPA such as giving conditions under which such a robust equilibrium exists. Then we propose a robust multi-agent Q-learning (RMAQ) algorithm to find such an equilibrium, with convergence guarantees. To handle high-dimensional state-action space, we design a robust multi-agent actor-critic (RMAAC) algorithm based on an analytical expression of the policy gradient derived in the paper. Our experiments show that the proposed RMAQ algorithm converges to the optimal value function; our RMAAC algorithm outperforms several MARL and robust MARL methods in multiple multi-agent environments when state uncertainty is present. The source code is public on \url{https://github.com/sihongho/robust_marl_with_state_uncertainty}.
Multi-Agent Reinforcement Learning Guided by Signal Temporal Logic Specifications
Jun 11, 2023
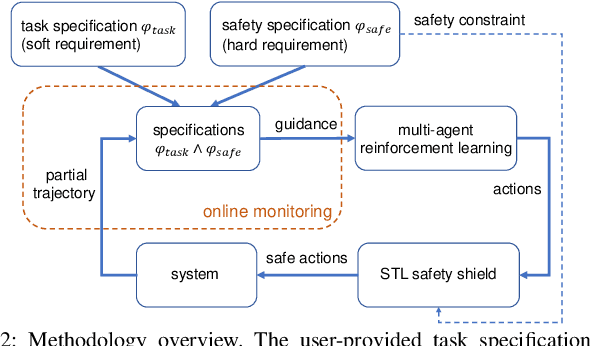
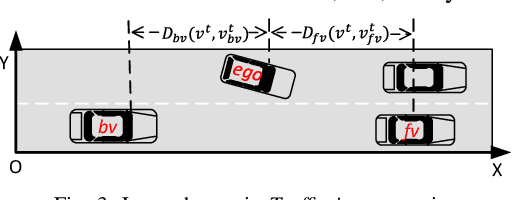
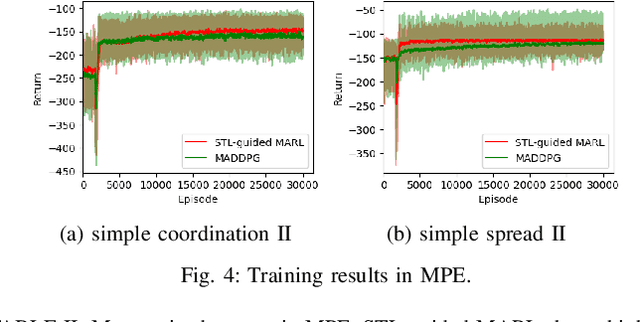
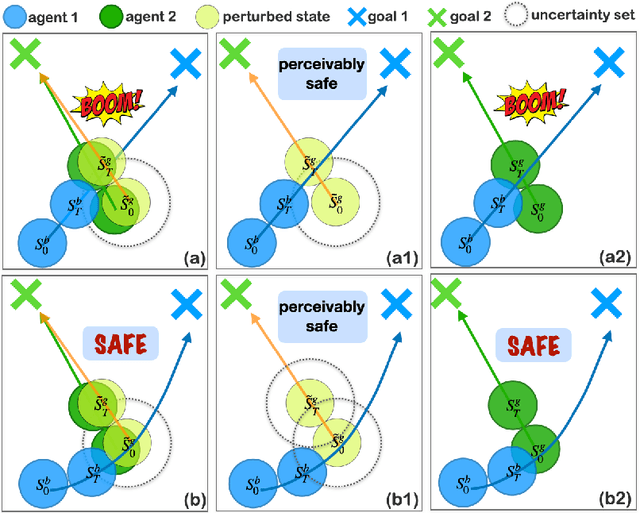
There has been growing interest in deep reinforcement learning (DRL) algorithm design, and reward design is one key component of DRL. Among the various techniques, formal methods integrated with DRL have garnered considerable attention due to their expressiveness and ability to define the requirements for the states and actions of the agent. However, the literature of Signal Temporal Logic (STL) in guiding multi-agent reinforcement learning (MARL) reward design remains limited. In this paper, we propose a novel STL-guided multi-agent reinforcement learning algorithm. The STL specifications are designed to include both task specifications according to the objective of each agent and safety specifications, and the robustness values of the STL specifications are leveraged to generate rewards. We validate the advantages of our method through empirical studies. The experimental results demonstrate significant performance improvements compared to MARL without STL guidance, along with a remarkable increase in the overall safety rate of the multi-agent systems.
Collaborative Multi-Object Tracking with Conformal Uncertainty Propagation
Mar 25, 2023



Object detection and multiple object tracking (MOT) are essential components of self-driving systems. Accurate detection and uncertainty quantification are both critical for onboard modules, such as perception, prediction, and planning, to improve the safety and robustness of autonomous vehicles. Collaborative object detection (COD) has been proposed to improve detection accuracy and reduce uncertainty by leveraging the viewpoints of multiple agents. However, little attention has been paid on how to leverage the uncertainty quantification from COD to enhance MOT performance. In this paper, as the first attempt, we design the uncertainty propagation framework to address this challenge, called MOT-CUP. Our framework first quantifies the uncertainty of COD through direct modeling and conformal prediction, and propogates this uncertainty information during the motion prediction and association steps. MOT-CUP is designed to work with different collaborative object detectors and baseline MOT algorithms. We evaluate MOT-CUP on V2X-Sim, a comprehensive collaborative perception dataset, and demonstrate a 2% improvement in accuracy and a 2.67X reduction in uncertainty compared to the baselines, e.g., SORT and ByteTrack. MOT-CUP demonstrates the importance of uncertainty quantification in both COD and MOT, and provides the first attempt to improve the accuracy and reduce the uncertainty in MOT based on COD through uncertainty propogation.
Shared Information-Based Safe And Efficient Behavior Planning For Connected Autonomous Vehicles
Feb 15, 2023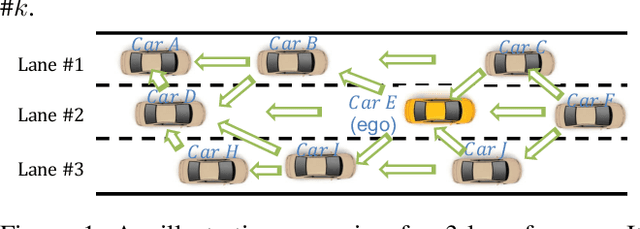

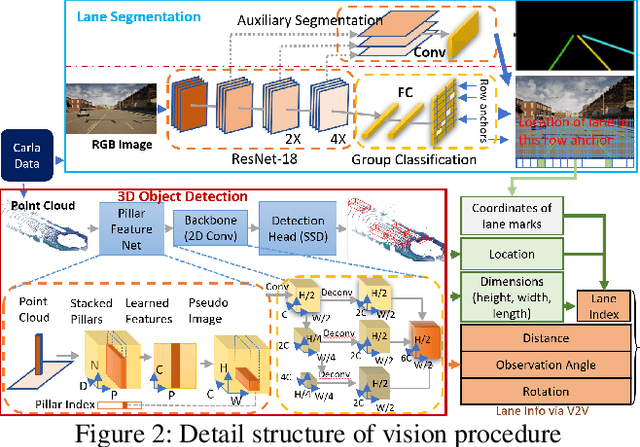
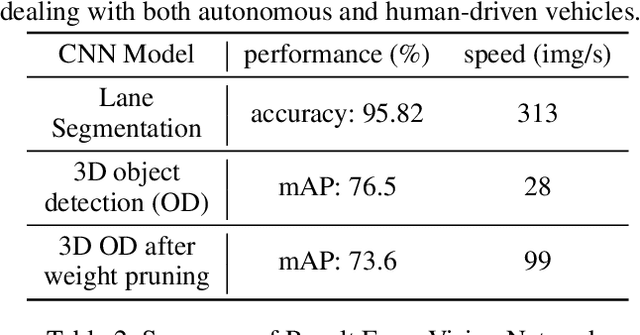
The recent advancements in wireless technology enable connected autonomous vehicles (CAVs) to gather data via vehicle-to-vehicle (V2V) communication, such as processed LIDAR and camera data from other vehicles. In this work, we design an integrated information sharing and safe multi-agent reinforcement learning (MARL) framework for CAVs, to take advantage of the extra information when making decisions to improve traffic efficiency and safety. We first use weight pruned convolutional neural networks (CNN) to process the raw image and point cloud LIDAR data locally at each autonomous vehicle, and share CNN-output data with neighboring CAVs. We then design a safe actor-critic algorithm that utilizes both a vehicle's local observation and the information received via V2V communication to explore an efficient behavior planning policy with safety guarantees. Using the CARLA simulator for experiments, we show that our approach improves the CAV system's efficiency in terms of average velocity and comfort under different CAV ratios and different traffic densities. We also show that our approach avoids the execution of unsafe actions and always maintains a safe distance from other vehicles. We construct an obstacle-at-corner scenario to show that the shared vision can help CAVs to observe obstacles earlier and take action to avoid traffic jams.
What is the Solution for State-Adversarial Multi-Agent Reinforcement Learning?
Dec 07, 2022



Various types of Multi-Agent Reinforcement Learning (MARL) methods have been developed, assuming that agents' policies are based on true states. Recent works have improved the robustness of MARL under uncertainties from the reward, transition probability, or other partners' policies. However, in real-world multi-agent systems, state estimations may be perturbed by sensor measurement noise or even adversaries. Agents' policies trained with only true state information will deviate from optimal solutions when facing adversarial state perturbations during execution. MARL under adversarial state perturbations has limited study. Hence, in this work, we propose a State-Adversarial Markov Game (SAMG) and make the first attempt to study the fundamental properties of MARL under state uncertainties. We prove that the optimal agent policy and the robust Nash equilibrium do not always exist for an SAMG. Instead, we define the solution concept, robust agent policy, of the proposed SAMG under adversarial state perturbations, where agents want to maximize the worst-case expected state value. We then design a gradient descent ascent-based robust MARL algorithm to learn the robust policies for the MARL agents. Our experiments show that adversarial state perturbations decrease agents' rewards for several baselines from the existing literature, while our algorithm outperforms baselines with state perturbations and significantly improves the robustness of the MARL policies under state uncertainties.
Spatial-Temporal-Aware Safe Multi-Agent Reinforcement Learning of Connected Autonomous Vehicles in Challenging Scenarios
Oct 05, 2022
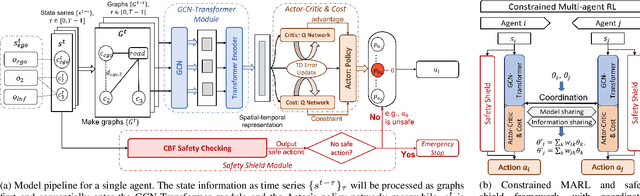
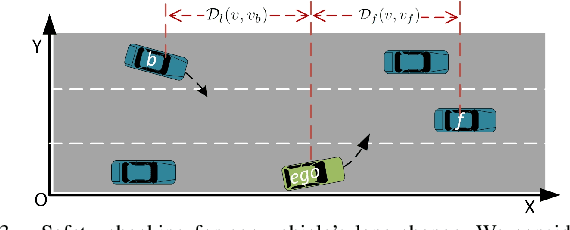

Communication technologies enable coordination among connected and autonomous vehicles (CAVs). However, it remains unclear how to utilize shared information to improve the safety and efficiency of the CAV system. In this work, we propose a framework of constrained multi-agent reinforcement learning (MARL) with a parallel safety shield for CAVs in challenging driving scenarios. The coordination mechanisms of the proposed MARL include information sharing and cooperative policy learning, with Graph Convolutional Network (GCN)-Transformer as a spatial-temporal encoder that enhances the agent's environment awareness. The safety shield module with Control Barrier Functions (CBF)-based safety checking protects the agents from taking unsafe actions. We design a constrained multi-agent advantage actor-critic (CMAA2C) algorithm to train safe and cooperative policies for CAVs. With the experiment deployed in the CARLA simulator, we verify the effectiveness of the safety checking, spatial-temporal encoder, and coordination mechanisms designed in our method by comparative experiments in several challenging scenarios with the defined hazard vehicles (HAZV). Results show that our proposed methodology significantly increases system safety and efficiency in challenging scenarios.