 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIT-LMPC: Safe Information-Theoretic Learning Model Predictive Control for Iterative Tasks
Feb 18, 2026Robots executing iterative tasks in complex, uncertain environments require control strategies that balance robustness, safety, and high performance. This paper introduces a safe information-theoretic learning model predictive control (SIT-LMPC) algorithm for iterative tasks. Specifically, we design an iterative control framework based on an information-theoretic model predictive control algorithm to address a constrained infinite-horizon optimal control problem for discrete-time nonlinear stochastic systems. An adaptive penalty method is developed to ensure safety while balancing optimality. Trajectories from previous iterations are utilized to learn a value function using normalizing flows, which enables richer uncertainty modeling compared to Gaussian priors. SIT-LMPC is designed for highly parallel execution on graphics processing units, allowing efficient real-time optimization. Benchmark simulations and hardware experiments demonstrate that SIT-LMPC iteratively improves system performance while robustly satisfying system constraints.
* 8 pages, 5 figures. Published in IEEE RA-L, vol. 11, no. 1, Jan. 2026. Presented at ICRA 2026
Nonplanar Model Predictive Control for Autonomous Vehicles with Recursive Sparse Gaussian Process Dynamics
Feb 18, 2026This paper proposes a nonplanar model predictive control (MPC) framework for autonomous vehicles operating on nonplanar terrain. To approximate complex vehicle dynamics in such environments, we develop a geometry-aware modeling approach that learns a residual Gaussian Process (GP). By utilizing a recursive sparse GP, the framework enables real-time adaptation to varying terrain geometry. The effectiveness of the learned model is demonstrated in a reference-tracking task using a Model Predictive Path Integral (MPPI) controller. Validation within a custom Isaac Sim environment confirms the framework's capability to maintain high tracking accuracy on challenging 3D surfaces.
AdaptNC: Adaptive Nonconformity Scores for Uncertainty-Aware Autonomous Systems in Dynamic Environments
Feb 02, 2026Rigorous uncertainty quantification is essential for the safe deployment of autonomous systems in unconstrained environments. Conformal Prediction (CP) provides a distribution-free framework for this task, yet its standard formulations rely on exchangeability assumptions that are violated by the distribution shifts inherent in real-world robotics. Existing online CP methods maintain target coverage by adaptively scaling the conformal threshold, but typically employ a static nonconformity score function. We show that this fixed geometry leads to highly conservative, volume-inefficient prediction regions when environments undergo structural shifts. To address this, we propose \textbf{AdaptNC}, a framework for the joint online adaptation of both the nonconformity score parameters and the conformal threshold. AdaptNC leverages an adaptive reweighting scheme to optimize score functions, and introduces a replay buffer mechanism to mitigate the coverage instability that occurs during score transitions. We evaluate AdaptNC on diverse robotic benchmarks involving multi-agent policy changes, environmental changes and sensor degradation. Our results demonstrate that AdaptNC significantly reduces prediction region volume compared to state-of-the-art threshold-only baselines while maintaining target coverage levels.
Small-Scale Testbeds for Connected and Automated Vehicles and Robot Swarms: Challenges and a Roadmap
Mar 07, 2025This article proposes a roadmap to address the current challenges in small-scale testbeds for Connected and Automated Vehicles (CAVs) and robot swarms. The roadmap is a joint effort of participants in the workshop "1st Workshop on Small-Scale Testbeds for Connected and Automated Vehicles and Robot Swarms," held on June 2 at the IEEE Intelligent Vehicles Symposium (IV) 2024 in Jeju, South Korea. The roadmap contains three parts: 1) enhancing accessibility and diversity, especially for underrepresented communities, 2) sharing best practices for the development and maintenance of testbeds, and 3) connecting testbeds through an abstraction layer to support collaboration. The workshop features eight invited speakers, four contributed papers [1]-[4], and a presentation of a survey paper on testbeds [5]. The survey paper provides an online comparative table of more than 25 testbeds, available at https://bassamlab.github.io/testbeds-survey. The workshop's own website is available at https://cpm-remote.lrt.unibwmuenchen.de/iv24-workshop.
Opportunistic Routing in Wireless Communications via Learnable State-Augmented Policies
Mar 05, 2025This paper addresses the challenge of packet-based information routing in large-scale wireless communication networks. The problem is framed as a constrained statistical learning task, where each network node operates using only local information. Opportunistic routing exploits the broadcast nature of wireless communication to dynamically select optimal forwarding nodes, enabling the information to reach the destination through multiple relay nodes simultaneously. To solve this, we propose a State-Augmentation (SA) based distributed optimization approach aimed at maximizing the total information handled by the source nodes in the network. The problem formulation leverages Graph Neural Networks (GNNs), which perform graph convolutions based on the topological connections between network nodes. Using an unsupervised learning paradigm, we extract routing policies from the GNN architecture, enabling optimal decisions for source nodes across various flows. Numerical experiments demonstrate that the proposed method achieves superior performance when training a GNN-parameterized model, particularly when compared to baseline algorithms. Additionally, applying the method to real-world network topologies and wireless ad-hoc network test beds validates its effectiveness, highlighting the robustness and transferability of GNNs.
STLGame: Signal Temporal Logic Games in Adversarial Multi-Agent Systems
Dec 02, 2024We study how to synthesize a robust and safe policy for autonomous systems under signal temporal logic (STL) tasks in adversarial settings against unknown dynamic agents. To ensure the worst-case STL satisfaction, we propose STLGame, a framework that models the multi-agent system as a two-player zero-sum game, where the ego agents try to maximize the STL satisfaction and other agents minimize it. STLGame aims to find a Nash equilibrium policy profile, which is the best case in terms of robustness against unseen opponent policies, by using the fictitious self-play (FSP) framework. FSP iteratively converges to a Nash profile, even in games set in continuous state-action spaces. We propose a gradient-based method with differentiable STL formulas, which is crucial in continuous settings to approximate the best responses at each iteration of FSP. We show this key aspect experimentally by comparing with reinforcement learning-based methods to find the best response. Experiments on two standard dynamical system benchmarks, Ackermann steering vehicles and autonomous drones, demonstrate that our converged policy is almost unexploitable and robust to various unseen opponents' policies. All code and additional experimental results can be found on our project website: https://sites.google.com/view/stlgame
PoseINN: Realtime Visual-based Pose Regression and Localization with Invertible Neural Networks
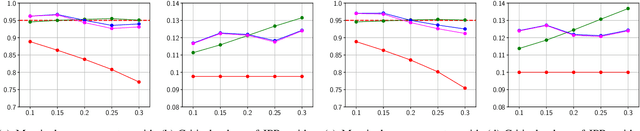
Apr 20, 2024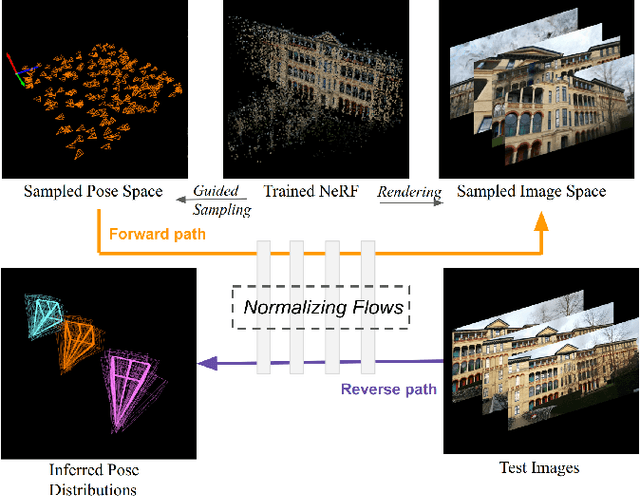
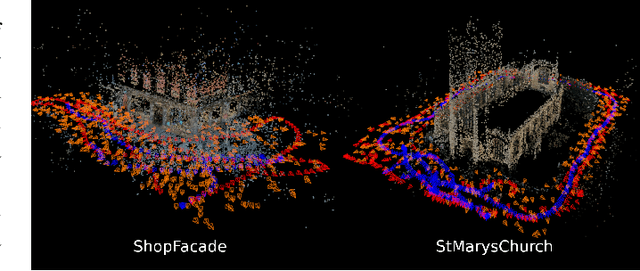
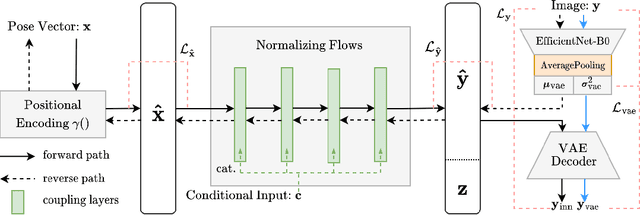

Estimating ego-pose from cameras is an important problem in robotics with applications ranging from mobile robotics to augmented reality. While SOTA models are becoming increasingly accurate, they can still be unwieldy due to high computational costs. In this paper, we propose to solve the problem by using invertible neural networks (INN) to find the mapping between the latent space of images and poses for a given scene. Our model achieves similar performance to the SOTA while being faster to train and only requiring offline rendering of low-resolution synthetic data. By using normalizing flows, the proposed method also provides uncertainty estimation for the output. We also demonstrated the efficiency of this method by deploying the model on a mobile robot.
Conformal Off-Policy Prediction for Multi-Agent Systems
Mar 25, 2024

Off-Policy Prediction (OPP), i.e., predicting the outcomes of a target policy using only data collected under a nominal (behavioural) policy, is a paramount problem in data-driven analysis of safety-critical systems where the deployment of a new policy may be unsafe. To achieve dependable off-policy predictions, recent work on Conformal Off-Policy Prediction (COPP) leverage the conformal prediction framework to derive prediction regions with probabilistic guarantees under the target process. Existing COPP methods can account for the distribution shifts induced by policy switching, but are limited to single-agent systems and scalar outcomes (e.g., rewards). In this work, we introduce MA-COPP, the first conformal prediction method to solve OPP problems involving multi-agent systems, deriving joint prediction regions for all agents' trajectories when one or more "ego" agents change their policies. Unlike the single-agent scenario, this setting introduces higher complexity as the distribution shifts affect predictions for all agents, not just the ego agents, and the prediction task involves full multi-dimensional trajectories, not just reward values. A key contribution of MA-COPP is to avoid enumeration or exhaustive search of the output space of agent trajectories, which is instead required by existing COPP methods to construct the prediction region. We achieve this by showing that an over-approximation of the true JPR can be constructed, without enumeration, from the maximum density ratio of the JPR trajectories. We evaluate the effectiveness of MA-COPP in multi-agent systems from the PettingZoo library and the F1TENTH autonomous racing environment, achieving nominal coverage in higher dimensions and various shift settings.
Bridging the Gap between Discrete Agent Strategies in Game Theory and Continuous Motion Planning in Dynamic Environments
Mar 17, 2024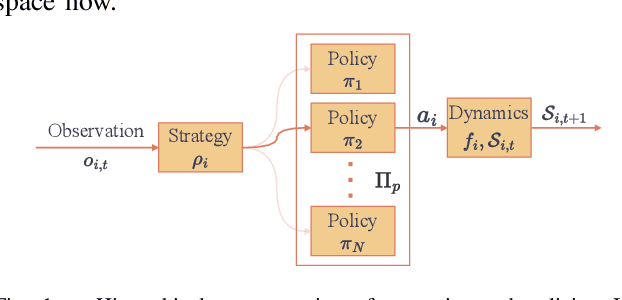


Generating competitive strategies and performing continuous motion planning simultaneously in an adversarial setting is a challenging problem. In addition, understanding the intent of other agents is crucial to deploying autonomous systems in adversarial multi-agent environments. Existing approaches either discretize agent action by grouping similar control inputs, sacrificing performance in motion planning, or plan in uninterpretable latent spaces, producing hard-to-understand agent behaviors. This paper proposes an agent strategy representation via Policy Characteristic Space that maps the agent policies to a pre-specified low-dimensional space. Policy Characteristic Space enables the discretization of agent policy switchings while preserving continuity in control. Also, it provides intepretability of agent policies and clear intentions of policy switchings. Then, regret-based game-theoretic approaches can be applied in the Policy Characteristic Space to obtain high performance in adversarial environments. Our proposed method is assessed by conducting experiments in an autonomous racing scenario using scaled vehicles. Statistical evidence shows that our method significantly improves the win rate of ego agent and the method also generalizes well to unseen environments.
Learning Local Control Barrier Functions for Safety Control of Hybrid Systems
Jan 26, 2024
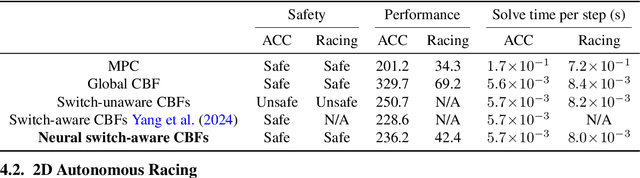
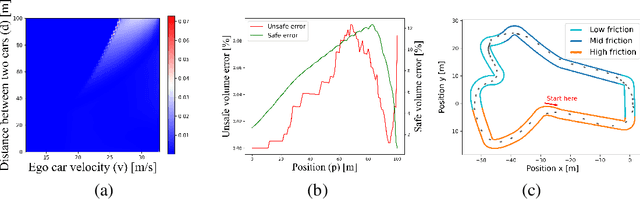
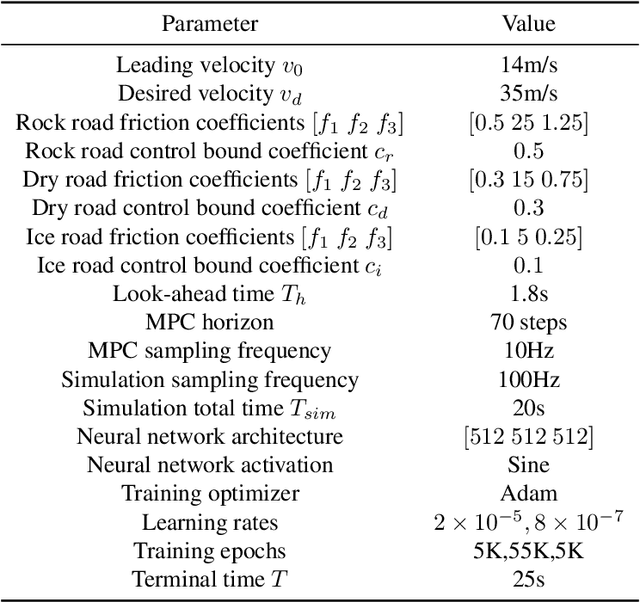
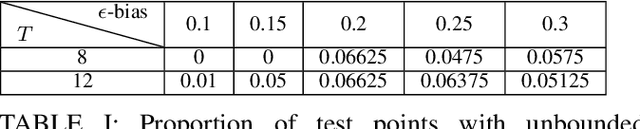
Hybrid dynamical systems are ubiquitous as practical robotic applications often involve both continuous states and discrete switchings. Safety is a primary concern for hybrid robotic systems. Existing safety-critical control approaches for hybrid systems are either computationally inefficient, detrimental to system performance, or limited to small-scale systems. To amend these drawbacks, in this paper, we propose a learningenabled approach to construct local Control Barrier Functions (CBFs) to guarantee the safety of a wide class of nonlinear hybrid dynamical systems. The end result is a safe neural CBFbased switching controller. Our approach is computationally efficient, minimally invasive to any reference controller, and applicable to large-scale systems. We empirically evaluate our framework and demonstrate its efficacy and flexibility through two robotic examples including a high-dimensional autonomous racing case, against other CBF-based approaches and model predictive control.