 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot MARL Benchmark in the Cyber-Physical Mobility Lab
Jan 23, 2026We present a reproducible benchmark for evaluating sim-to-real transfer of Multi-Agent Reinforcement Learning (MARL) policies for Connected and Automated Vehicles (CAVs). The platform, based on the Cyber-Physical Mobility Lab (CPM Lab) [1], integrates simulation, a high-fidelity digital twin, and a physical testbed, enabling structured zero-shot evaluation of MARL motion-planning policies. We demonstrate its use by deploying a SigmaRL-trained policy [2] across all three domains, revealing two complementary sources of performance degradation: architectural differences between simulation and hardware control stacks, and the sim-to-real gap induced by increasing environmental realism. The open-source setup enables systematic analysis of sim-to-real challenges in MARL under realistic, reproducible conditions.
Integrated Wheel Sensor Communication using ESP32 -- A Contribution towards a Digital Twin of the Road System
Sep 04, 2025While current onboard state estimation methods are adequate for most driving and safety-related applications, they do not provide insights into the interaction between tires and road surfaces. This paper explores a novel communication concept for efficiently transmitting integrated wheel sensor data from an ESP32 microcontroller. Our proposed approach utilizes a publish-subscribe system, surpassing comparable solutions in the literature regarding data transmission volume. We tested this approach on a drum tire test rig with our prototype sensors system utilizing a diverse selection of sample frequencies between 1 Hz and 32 000 Hz to demonstrate the efficacy of our communication concept. The implemented prototype sensor showcases minimal data loss, approximately 0.1 % of the sampled data, validating the reliability of our developed communication system. This work contributes to advancing real-time data acquisition, providing insights into optimizing integrated wheel sensor communication.
Foundation Models in Autonomous Driving: A Survey on Scenario Generation and Scenario Analysis
Jun 13, 2025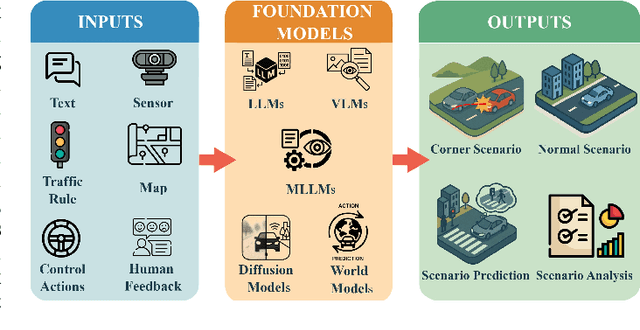
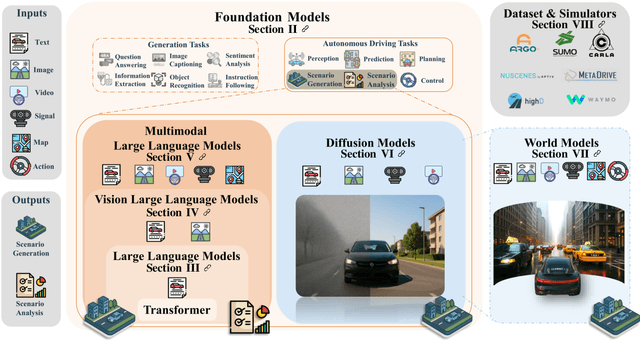

For autonomous vehicles, safe navigation in complex environments depends on handling a broad range of diverse and rare driving scenarios. Simulation- and scenario-based testing have emerged as key approaches to development and validation of autonomous driving systems. Traditional scenario generation relies on rule-based systems, knowledge-driven models, and data-driven synthesis, often producing limited diversity and unrealistic safety-critical cases. With the emergence of foundation models, which represent a new generation of pre-trained, general-purpose AI models, developers can process heterogeneous inputs (e.g., natural language, sensor data, HD maps, and control actions), enabling the synthesis and interpretation of complex driving scenarios. In this paper, we conduct a survey about the application of foundation models for scenario generation and scenario analysis in autonomous driving (as of May 2025). Our survey presents a unified taxonomy that includes large language models, vision-language models, multimodal large language models, diffusion models, and world models for the generation and analysis of autonomous driving scenarios. In addition, we review the methodologies, open-source datasets, simulation platforms, and benchmark challenges, and we examine the evaluation metrics tailored explicitly to scenario generation and analysis. Finally, the survey concludes by highlighting the open challenges and research questions, and outlining promising future research directions. All reviewed papers are listed in a continuously maintained repository, which contains supplementary materials and is available at https://github.com/TUM-AVS/FM-for-Scenario-Generation-Analysis.
A Real-Time Control Barrier Function-Based Safety Filter for Motion Planning with Arbitrary Road Boundary Constraints
May 05, 2025We present a real-time safety filter for motion planning, such as learning-based methods, using Control Barrier Functions (CBFs), which provides formal guarantees for collision avoidance with road boundaries. A key feature of our approach is its ability to directly incorporate road geometries of arbitrary shape without resorting to conservative overapproximations. We formulate the safety filter as a constrained optimization problem in the form of a Quadratic Program (QP). It achieves safety by making minimal, necessary adjustments to the control actions issued by the nominal motion planner. We validate our safety filter through extensive numerical experiments across a variety of traffic scenarios featuring complex roads. The results confirm its reliable safety and high computational efficiency (execution frequency up to 40 Hz). Code & Video Demo: github.com/bassamlab/SigmaRL
Less is More: Contextual Sampling for Nonlinear Data-Enabled Predictive Control
Mar 31, 2025Data-enabled Predictive Control (DeePC) is a powerful data-driven approach for predictive control without requiring an explicit system model. However, its high computational cost limits its applicability to real-time robotic systems. For robotic applications such as motion planning and trajectory tracking, real-time control is crucial. Nonlinear DeePC either relies on large datasets or learning the nonlinearities to ensure predictive accuracy, leading to high computational complexity. This work introduces contextual sampling, a novel data selection strategy to handle nonlinearities for DeePC by dynamically selecting the most relevant data at each time step. By reducing the dataset size while preserving prediction accuracy, our method improves computational efficiency, of DeePC for real-time robotic applications. We validate our approach for autonomous vehicle motion planning. For a dataset size of 100 sub-trajectories, Contextual sampling DeePC reduces tracking error by 53.2 % compared to Leverage Score sampling. Additionally, Contextual sampling reduces max computation time by 87.2 % compared to using the full dataset of 491 sub-trajectories while achieving comparable tracking performance. These results highlight the potential of Contextual sampling to enable real-time, data-driven control for robotic systems.
High-Order Control Barrier Functions: Insights and a Truncated Taylor-Based Formulation
Mar 19, 2025



We examine the complexity of the standard High-Order Control Barrier Function (HOCBF) approach and propose a truncated Taylor-based approach that reduces design parameters. First, we derive the explicit inequality condition for the HOCBF approach and show that the corresponding equality condition sets a lower bound on the barrier function value that regulates its decay rate. Next, we present our Truncated Taylor CBF (TTCBF), which uses a truncated Taylor series to approximate the discrete-time CBF condition. While the standard HOCBF approach requires multiple class K functions, leading to more design parameters as the constraint's relative degree increases, our TTCBF approach requires only one. We support our theoretical findings in numerical collision-avoidance experiments and show that our approach ensures safety while reducing design complexity.
Small-Scale Testbeds for Connected and Automated Vehicles and Robot Swarms: Challenges and a Roadmap
Mar 07, 2025This article proposes a roadmap to address the current challenges in small-scale testbeds for Connected and Automated Vehicles (CAVs) and robot swarms. The roadmap is a joint effort of participants in the workshop "1st Workshop on Small-Scale Testbeds for Connected and Automated Vehicles and Robot Swarms," held on June 2 at the IEEE Intelligent Vehicles Symposium (IV) 2024 in Jeju, South Korea. The roadmap contains three parts: 1) enhancing accessibility and diversity, especially for underrepresented communities, 2) sharing best practices for the development and maintenance of testbeds, and 3) connecting testbeds through an abstraction layer to support collaboration. The workshop features eight invited speakers, four contributed papers [1]-[4], and a presentation of a survey paper on testbeds [5]. The survey paper provides an online comparative table of more than 25 testbeds, available at https://bassamlab.github.io/testbeds-survey. The workshop's own website is available at https://cpm-remote.lrt.unibwmuenchen.de/iv24-workshop.
Simultaneous Computation with Multiple Prioritizations in Multi-Agent Motion Planning
Jan 18, 2025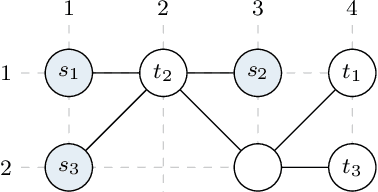

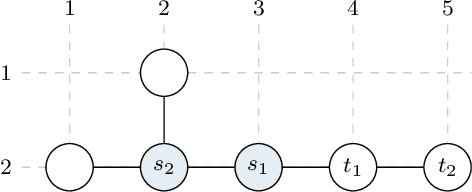
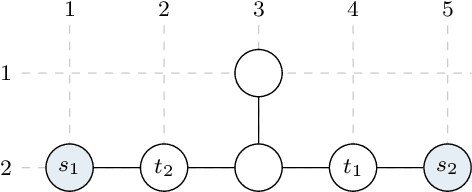
Multi-agent path finding (MAPF) in large networks is computationally challenging. An approach for MAPF is prioritized planning (PP), in which agents plan sequentially according to their priority. Albeit a computationally efficient approach for MAPF, the solution quality strongly depends on the prioritization. Most prioritizations rely either on heuristics, which do not generalize well, or iterate to find adequate priorities, which costs computational effort. In this work, we show how agents can compute with multiple prioritizations simultaneously. Our approach is general as it does not rely on domain-specific knowledge. The context of this work is multi-agent motion planning (MAMP) with a receding horizon subject to computation time constraints. MAMP considers the system dynamics in more detail compared to MAPF. In numerical experiments on MAMP, we demonstrate that our approach to prioritization comes close to optimal prioritization and outperforms state-of-the-art methods with only a minor increase in computation time. We show real-time capability in an experiment on a road network with ten vehicles in our Cyber-Physical Mobility Lab.
Graph Coloring to Reduce Computation Time in Prioritized Planning
Jan 18, 2025



Distributing computations among agents in large networks reduces computational effort in multi-agent path finding (MAPF). One distribution strategy is prioritized planning (PP). In PP, we couple and prioritize interacting agents to achieve a desired behavior across all agents in the network. We characterize the interaction with a directed acyclic graph (DAG). The computation time for solving MAPF problem using PP is mainly determined through the longest path in this DAG. The longest path depends on the fixed undirected coupling graph and the variable prioritization. The approaches from literature to prioritize agents are numerous and pursue various goals. This article presents an approach for prioritization in PP to reduce the longest path length in the coupling DAG and thus the computation time for MAPF using PP. We prove that this problem can be mapped to a graph-coloring problem, in which the number of colors required corresponds to the longest path length in the coupling DAG. We propose a decentralized graph-coloring algorithm to determine priorities for the agents. We evaluate the approach by applying it to multi-agent motion planning (MAMP) for connected and automated vehicles (CAVs) on roads using, a variant of MAPF.
Modern Middlewares for Automated Vehicles: A Tutorial
Dec 10, 2024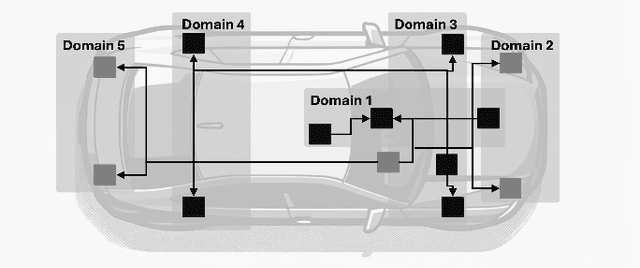
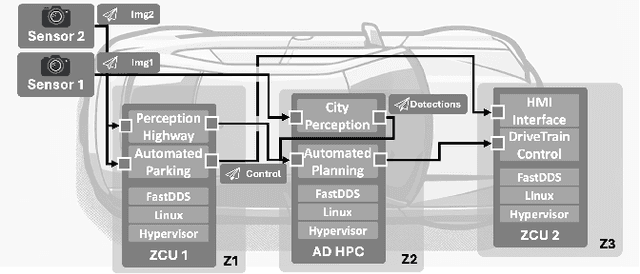
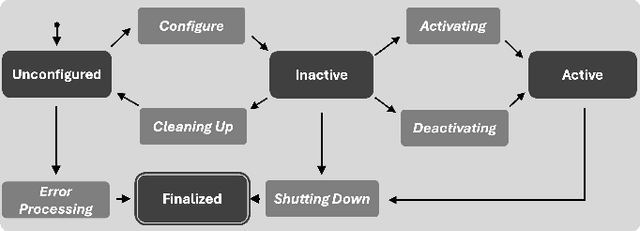
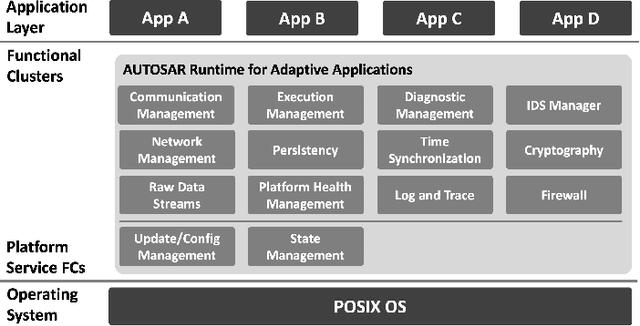
This paper offers a tutorial on current middlewares in automated vehicles. Our aim is to provide the reader with an overview of current middlewares and to identify open challenges in this field. We start by explaining the fundamentals of software architecture in distributed systems and the distinguishing requirements of Automated Vehicles. We then distinguish between communication middlewares and architecture platforms and highlight their key principles and differences. Next, we present five state-of-the-art middlewares as well as their capabilities and functions. We explore how these middlewares could be applied in the design of future vehicle software and their role in the automotive domain. Finally, we compare the five middlewares presented and discuss open research challenges.