 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Physical Consistency in Lightweight World Models
Sep 15, 2025A major challenge in deploying world models is the trade-off between size and performance. Large world models can capture rich physical dynamics but require massive computing resources, making them impractical for edge devices. Small world models are easier to deploy but often struggle to learn accurate physics, leading to poor predictions. We propose the Physics-Informed BEV World Model (PIWM), a compact model designed to efficiently capture physical interactions in bird's-eye-view (BEV) representations. PIWM uses Soft Mask during training to improve dynamic object modeling and future prediction. We also introduce a simple yet effective technique, Warm Start, for inference to enhance prediction quality with a zero-shot model. Experiments show that at the same parameter scale (400M), PIWM surpasses the baseline by 60.6% in weighted overall score. Moreover, even when compared with the largest baseline model (400M), the smallest PIWM (130M Soft Mask) achieves a 7.4% higher weighted overall score with a 28% faster inference speed.
Foundation Models in Autonomous Driving: A Survey on Scenario Generation and Scenario Analysis
Jun 13, 2025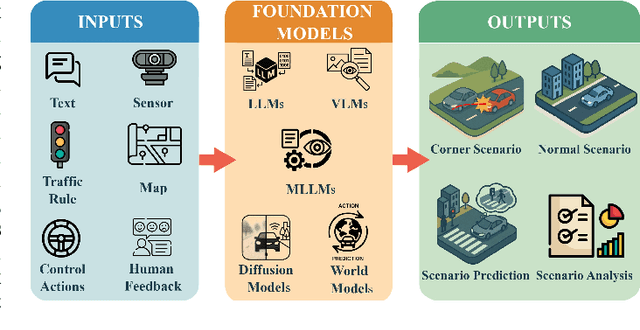
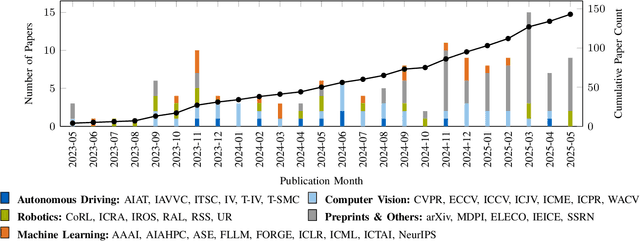
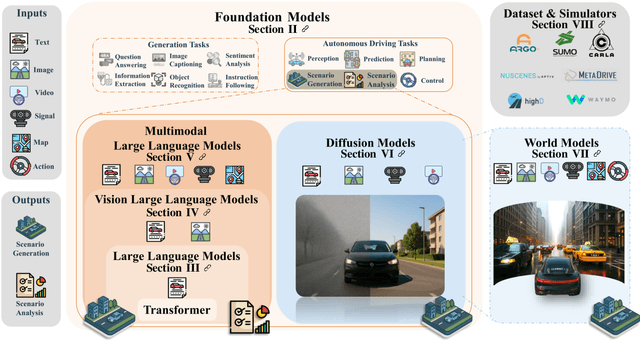

For autonomous vehicles, safe navigation in complex environments depends on handling a broad range of diverse and rare driving scenarios. Simulation- and scenario-based testing have emerged as key approaches to development and validation of autonomous driving systems. Traditional scenario generation relies on rule-based systems, knowledge-driven models, and data-driven synthesis, often producing limited diversity and unrealistic safety-critical cases. With the emergence of foundation models, which represent a new generation of pre-trained, general-purpose AI models, developers can process heterogeneous inputs (e.g., natural language, sensor data, HD maps, and control actions), enabling the synthesis and interpretation of complex driving scenarios. In this paper, we conduct a survey about the application of foundation models for scenario generation and scenario analysis in autonomous driving (as of May 2025). Our survey presents a unified taxonomy that includes large language models, vision-language models, multimodal large language models, diffusion models, and world models for the generation and analysis of autonomous driving scenarios. In addition, we review the methodologies, open-source datasets, simulation platforms, and benchmark challenges, and we examine the evaluation metrics tailored explicitly to scenario generation and analysis. Finally, the survey concludes by highlighting the open challenges and research questions, and outlining promising future research directions. All reviewed papers are listed in a continuously maintained repository, which contains supplementary materials and is available at https://github.com/TUM-AVS/FM-for-Scenario-Generation-Analysis.
A Safe Reinforcement Learning driven Weights-varying Model Predictive Control for Autonomous Vehicle Motion Control
Feb 04, 2024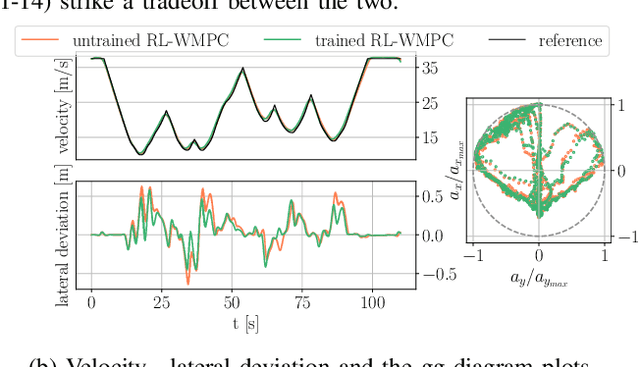
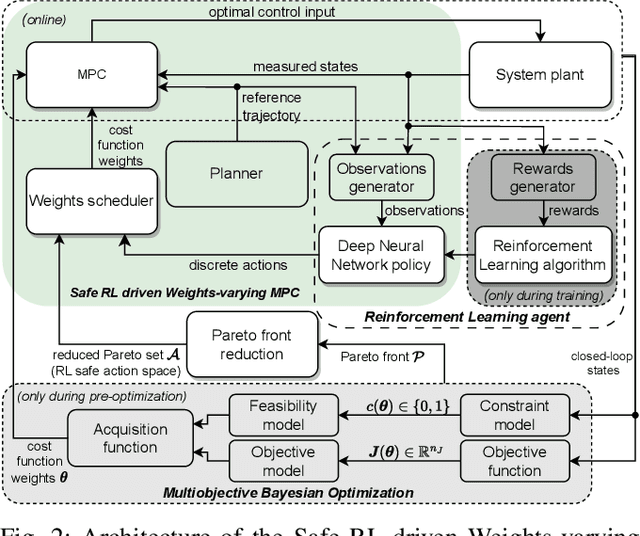
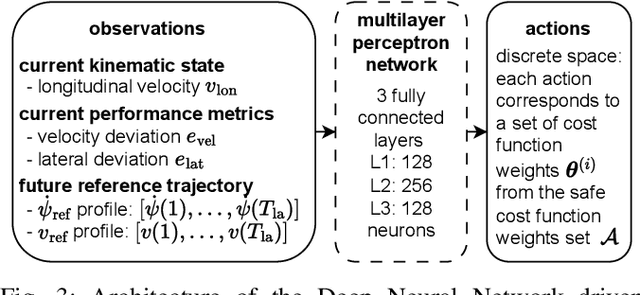
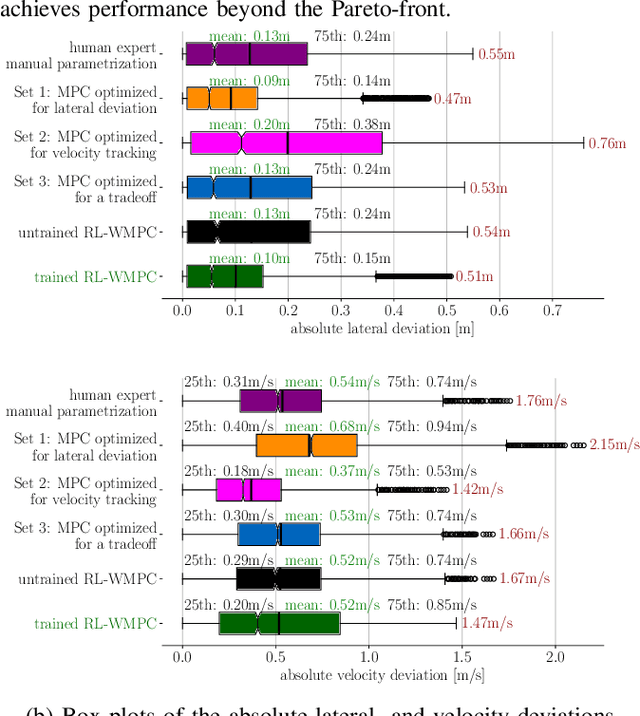
Determining the optimal cost function parameters of Model Predictive Control (MPC) to optimize multiple control objectives is a challenging and time-consuming task. Multiobjective Bayesian Optimization (BO) techniques solve this problem by determining a Pareto optimal parameter set for an MPC with static weights. However, a single parameter set may not deliver the most optimal closed-loop control performance when the context of the MPC operating conditions changes during its operation, urging the need to adapt the cost function weights at runtime. Deep Reinforcement Learning (RL) algorithms can automatically learn context-dependent optimal parameter sets and dynamically adapt for a Weightsvarying MPC (WMPC). However, learning cost function weights from scratch in a continuous action space may lead to unsafe operating states. To solve this, we propose a novel approach limiting the RL actions within a safe learning space representing a catalog of pre-optimized BO Pareto-optimal weight sets. We conceive a RL agent not to learn in a continuous space but to proactively anticipate upcoming control tasks and to choose the most optimal discrete actions, each corresponding to a single set of Pareto optimal weights, context-dependent. Hence, even an untrained RL agent guarantees a safe and optimal performance. Experimental results demonstrate that an untrained RL-WMPC shows Pareto-optimal closed-loop behavior and training the RL-WMPC helps exhibit a performance beyond the Pareto-front.
R$^2$NMPC: A Real-Time Reduced Robustified Nonlinear Model Predictive Control with Ellipsoidal Uncertainty Sets for Autonomous Vehicle Motion Control
Nov 10, 2023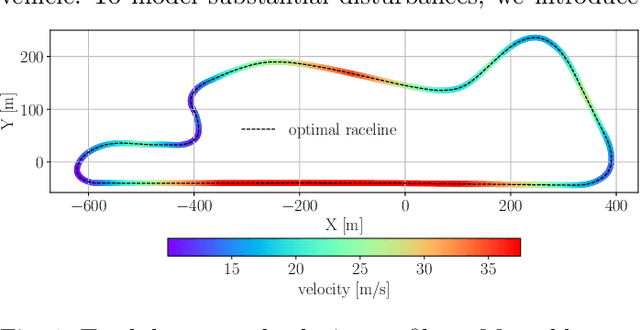
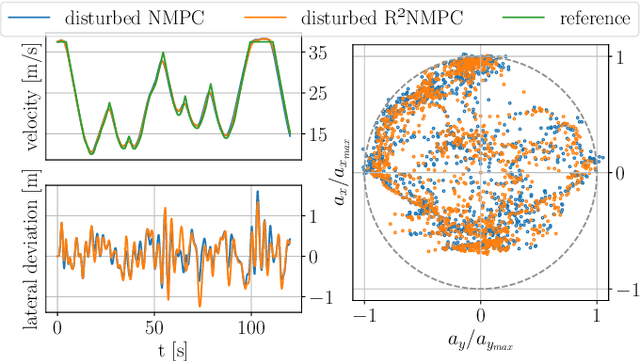
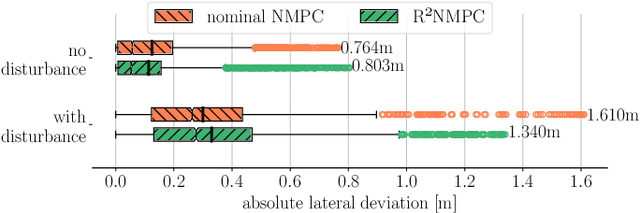
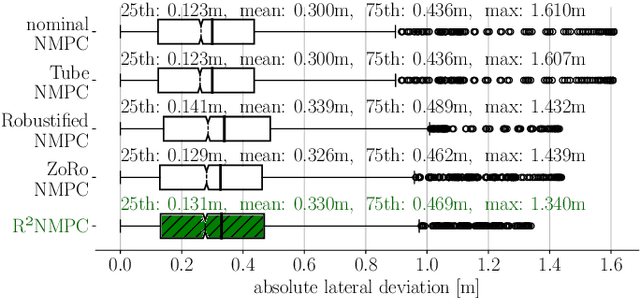
In this paper, we present a novel Reduced Robustified NMPC (R$^2$NMPC) algorithm that has the same complexity as an equivalent nominal NMPC while enhancing it with robustified constraints based on the dynamics of ellipsoidal uncertainty sets. This promises both a closed-loop- and constraint satisfaction performance equivalent to common Robustified NMPC approaches, while drastically reducing the computational complexity. The main idea lies in approximating the ellipsoidal uncertainty sets propagation over the prediction horizon with the system dynamics' sensitivities inferred from the last optimal control problem (OCP) solution, and similarly for the gradients to robustify the constraints. Thus, we do not require the decision variables related to the uncertainty propagation within the OCP, rendering it computationally tractable. Next, we illustrate the real-time control capabilities of our algorithm in handling a complex, high-dimensional, and highly nonlinear system, namely the trajectory following of an autonomous passenger vehicle modeled with a dynamic nonlinear single-track model. Our experimental findings, alongside a comparative assessment against other Robust NMPC approaches, affirm the robustness of our method in effectively tracking an optimal racetrack trajectory while satisfying the nonlinear constraints. This performance is achieved while fully utilizing the vehicle's interface limits, even at high speeds of up to 37.5m/s, and successfully managing state estimation disturbances. Remarkably, our approach maintains a mean solving frequency of 144Hz.
Adaptive Stochastic Nonlinear Model Predictive Control with Look-ahead Deep Reinforcement Learning for Autonomous Vehicle Motion Control
Nov 07, 2023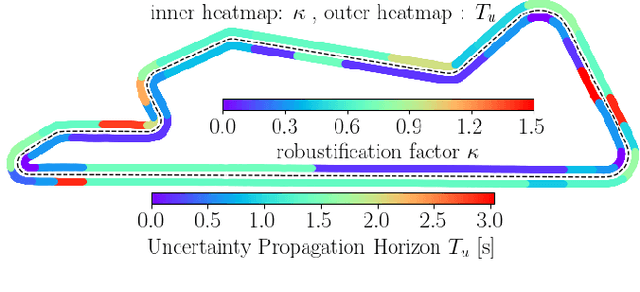
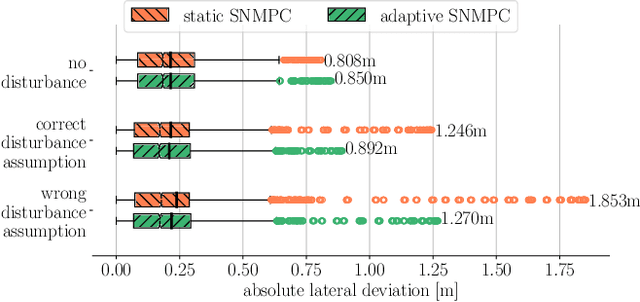
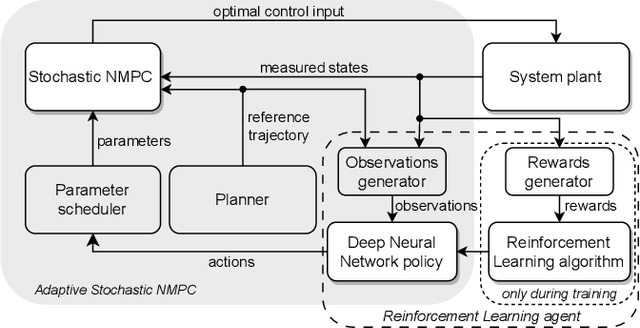
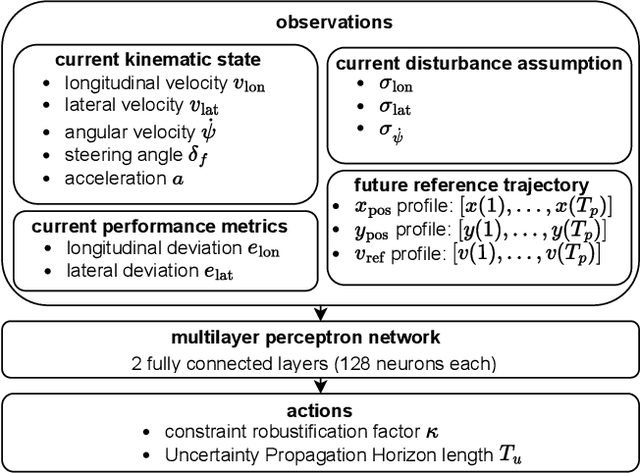
In this paper, we present a Deep Reinforcement Learning (RL)-driven Adaptive Stochastic Nonlinear Model Predictive Control (SNMPC) to optimize uncertainty handling, constraints robustification, feasibility, and closed-loop performance. To this end, we conceive an RL agent to proactively anticipate upcoming control tasks and to dynamically determine the most suitable combination of key SNMPC parameters - foremost the robustification factor $\kappa$ and the Uncertainty Propagation Horizon (UPH) $T_u$. We analyze the trained RL agent's decision-making process and highlight its ability to learn context-dependent optimal parameters. One key finding is that adapting the constraints robustification factor with the learned policy reduces conservatism and improves closed-loop performance while adapting UPH renders previously infeasible SNMPC problems feasible when faced with severe disturbances. We showcase the enhanced robustness and feasibility of our Adaptive SNMPC (aSNMPC) through the real-time motion control task of an autonomous passenger vehicle to follow an optimal race line when confronted with significant time-variant disturbances. Experimental findings demonstrate that our look-ahead RL-driven aSNMPC outperforms its Static SNMPC (sSNMPC) counterpart in minimizing the lateral deviation both with accurate and inaccurate disturbance assumptions and even when driving in previously unexplored environments.
A Stochastic Nonlinear Model Predictive Control with an Uncertainty Propagation Horizon for Autonomous Vehicle Motion Control
Oct 28, 2023Employing Stochastic Nonlinear Model Predictive Control (SNMPC) for real-time applications is challenging due to the complex task of propagating uncertainties through nonlinear systems. This difficulty becomes more pronounced in high-dimensional systems with extended prediction horizons, such as autonomous vehicles. To enhance closed-loop performance in and feasibility in SNMPCs, we introduce the concept of the Uncertainty Propagation Horizon (UPH). The UPH limits the time for uncertainty propagation through system dynamics, preventing trajectory divergence, optimizing feedback loop advantages, and reducing computational overhead. Our SNMPC approach utilizes Polynomial Chaos Expansion (PCE) to propagate uncertainties and incorporates nonlinear hard constraints on state expectations and nonlinear probabilistic constraints. We transform the probabilistic constraints into deterministic constraints by estimating the nonlinear constraints' expectation and variance. We then showcase our algorithm's effectiveness in real-time control of a high-dimensional, highly nonlinear system-the trajectory following of an autonomous passenger vehicle, modeled with a dynamic nonlinear single-track model. Experimental results demonstrate our approach's robust capability to follow an optimal racetrack trajectory at speeds of up to 37.5m/s while dealing with state estimation disturbances, achieving a minimum solving frequency of 97Hz. Additionally, our experiments illustrate that limiting the UPH renders previously infeasible SNMPC problems feasible, even when incorrect uncertainty assumptions or strong disturbances are present.
EDGAR: An Autonomous Driving Research Platform -- From Feature Development to Real-World Application
Sep 27, 2023



While current research and development of autonomous driving primarily focuses on developing new features and algorithms, the transfer from isolated software components into an entire software stack has been covered sparsely. Besides that, due to the complexity of autonomous software stacks and public road traffic, the optimal validation of entire stacks is an open research problem. Our paper targets these two aspects. We present our autonomous research vehicle EDGAR and its digital twin, a detailed virtual duplication of the vehicle. While the vehicle's setup is closely related to the state of the art, its virtual duplication is a valuable contribution as it is crucial for a consistent validation process from simulation to real-world tests. In addition, different development teams can work with the same model, making integration and testing of the software stacks much easier, significantly accelerating the development process. The real and virtual vehicles are embedded in a comprehensive development environment, which is also introduced. All parameters of the digital twin are provided open-source at https://github.com/TUMFTM/edgar_digital_twin.