 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Safe Reinforcement Learning driven Weights-varying Model Predictive Control for Autonomous Vehicle Motion Control
Paper and Code
Feb 04, 2024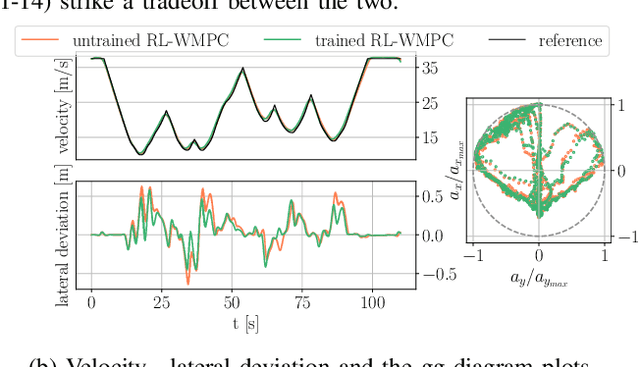
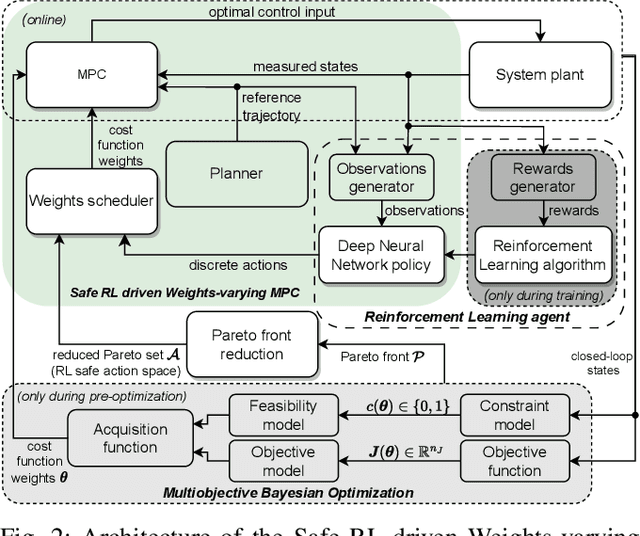
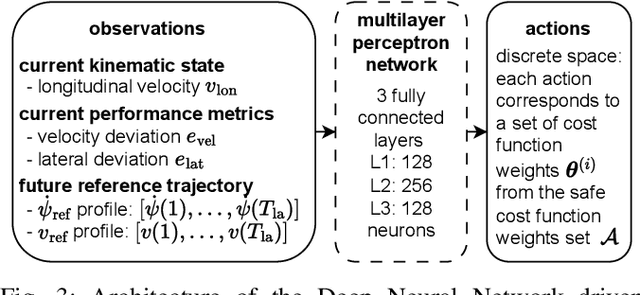
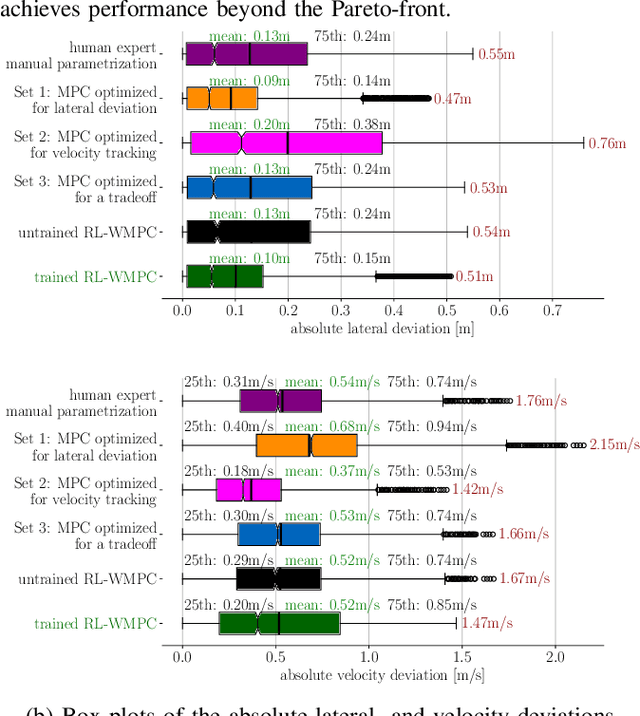
Determining the optimal cost function parameters of Model Predictive Control (MPC) to optimize multiple control objectives is a challenging and time-consuming task. Multiobjective Bayesian Optimization (BO) techniques solve this problem by determining a Pareto optimal parameter set for an MPC with static weights. However, a single parameter set may not deliver the most optimal closed-loop control performance when the context of the MPC operating conditions changes during its operation, urging the need to adapt the cost function weights at runtime. Deep Reinforcement Learning (RL) algorithms can automatically learn context-dependent optimal parameter sets and dynamically adapt for a Weightsvarying MPC (WMPC). However, learning cost function weights from scratch in a continuous action space may lead to unsafe operating states. To solve this, we propose a novel approach limiting the RL actions within a safe learning space representing a catalog of pre-optimized BO Pareto-optimal weight sets. We conceive a RL agent not to learn in a continuous space but to proactively anticipate upcoming control tasks and to choose the most optimal discrete actions, each corresponding to a single set of Pareto optimal weights, context-dependent. Hence, even an untrained RL agent guarantees a safe and optimal performance. Experimental results demonstrate that an untrained RL-WMPC shows Pareto-optimal closed-loop behavior and training the RL-WMPC helps exhibit a performance beyond the Pareto-front.