 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Physical Consistency in Lightweight World Models
Sep 15, 2025A major challenge in deploying world models is the trade-off between size and performance. Large world models can capture rich physical dynamics but require massive computing resources, making them impractical for edge devices. Small world models are easier to deploy but often struggle to learn accurate physics, leading to poor predictions. We propose the Physics-Informed BEV World Model (PIWM), a compact model designed to efficiently capture physical interactions in bird's-eye-view (BEV) representations. PIWM uses Soft Mask during training to improve dynamic object modeling and future prediction. We also introduce a simple yet effective technique, Warm Start, for inference to enhance prediction quality with a zero-shot model. Experiments show that at the same parameter scale (400M), PIWM surpasses the baseline by 60.6% in weighted overall score. Moreover, even when compared with the largest baseline model (400M), the smallest PIWM (130M Soft Mask) achieves a 7.4% higher weighted overall score with a 28% faster inference speed.
A Survey: Learning Embodied Intelligence from Physical Simulators and World Models
Jul 01, 2025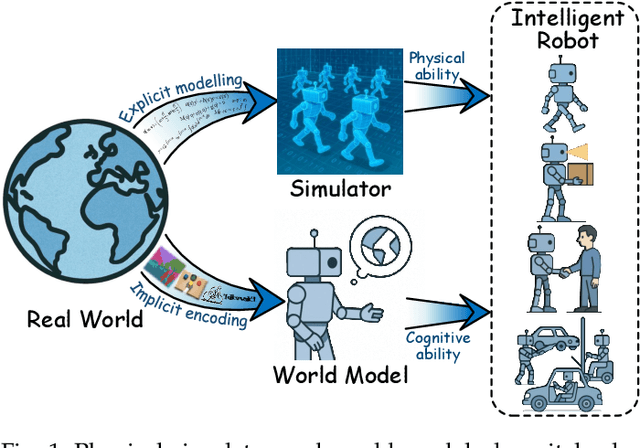
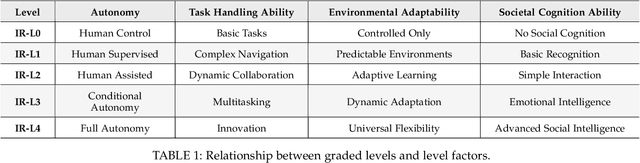
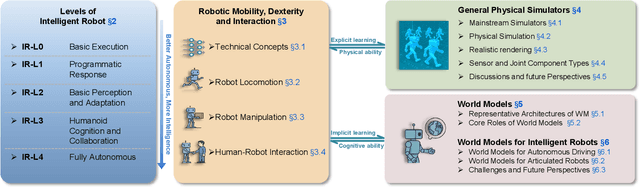

The pursuit of artificial general intelligence (AGI) has placed embodied intelligence at the forefront of robotics research. Embodied intelligence focuses on agents capable of perceiving, reasoning, and acting within the physical world. Achieving robust embodied intelligence requires not only advanced perception and control, but also the ability to ground abstract cognition in real-world interactions. Two foundational technologies, physical simulators and world models, have emerged as critical enablers in this quest. Physical simulators provide controlled, high-fidelity environments for training and evaluating robotic agents, allowing safe and efficient development of complex behaviors. In contrast, world models empower robots with internal representations of their surroundings, enabling predictive planning and adaptive decision-making beyond direct sensory input. This survey systematically reviews recent advances in learning embodied AI through the integration of physical simulators and world models. We analyze their complementary roles in enhancing autonomy, adaptability, and generalization in intelligent robots, and discuss the interplay between external simulation and internal modeling in bridging the gap between simulated training and real-world deployment. By synthesizing current progress and identifying open challenges, this survey aims to provide a comprehensive perspective on the path toward more capable and generalizable embodied AI systems. We also maintain an active repository that contains up-to-date literature and open-source projects at https://github.com/NJU3DV-LoongGroup/Embodied-World-Models-Survey.
Foundation Models in Autonomous Driving: A Survey on Scenario Generation and Scenario Analysis
Jun 13, 2025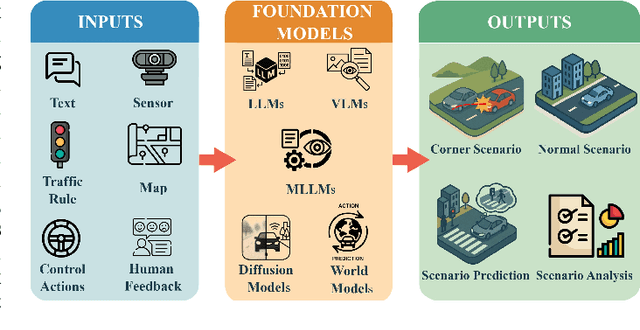
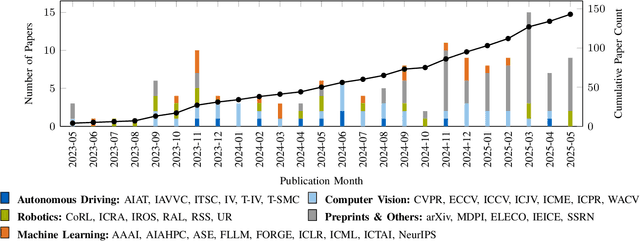
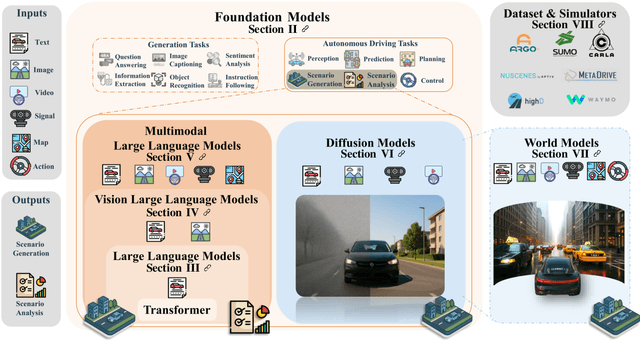

For autonomous vehicles, safe navigation in complex environments depends on handling a broad range of diverse and rare driving scenarios. Simulation- and scenario-based testing have emerged as key approaches to development and validation of autonomous driving systems. Traditional scenario generation relies on rule-based systems, knowledge-driven models, and data-driven synthesis, often producing limited diversity and unrealistic safety-critical cases. With the emergence of foundation models, which represent a new generation of pre-trained, general-purpose AI models, developers can process heterogeneous inputs (e.g., natural language, sensor data, HD maps, and control actions), enabling the synthesis and interpretation of complex driving scenarios. In this paper, we conduct a survey about the application of foundation models for scenario generation and scenario analysis in autonomous driving (as of May 2025). Our survey presents a unified taxonomy that includes large language models, vision-language models, multimodal large language models, diffusion models, and world models for the generation and analysis of autonomous driving scenarios. In addition, we review the methodologies, open-source datasets, simulation platforms, and benchmark challenges, and we examine the evaluation metrics tailored explicitly to scenario generation and analysis. Finally, the survey concludes by highlighting the open challenges and research questions, and outlining promising future research directions. All reviewed papers are listed in a continuously maintained repository, which contains supplementary materials and is available at https://github.com/TUM-AVS/FM-for-Scenario-Generation-Analysis.
DualAD: Dual-Layer Planning for Reasoning in Autonomous Driving
Sep 26, 2024



We present a novel autonomous driving framework, DualAD, designed to imitate human reasoning during driving. DualAD comprises two layers: a rule-based motion planner at the bottom layer that handles routine driving tasks requiring minimal reasoning, and an upper layer featuring a rule-based text encoder that converts driving scenarios from absolute states into text description. This text is then processed by a large language model (LLM) to make driving decisions. The upper layer intervenes in the bottom layer's decisions when potential danger is detected, mimicking human reasoning in critical situations. Closed-loop experiments demonstrate that DualAD, using a zero-shot pre-trained model, significantly outperforms rule-based motion planners that lack reasoning abilities. Our experiments also highlight the effectiveness of the text encoder, which considerably enhances the model's scenario understanding. Additionally, the integrated DualAD model improves with stronger LLMs, indicating the framework's potential for further enhancement. We make code and benchmarks publicly available.
ESP: Extro-Spective Prediction for Long-term Behavior Reasoning in Emergency Scenarios
May 07, 2024



Emergent-scene safety is the key milestone for fully autonomous driving, and reliable on-time prediction is essential to maintain safety in emergency scenarios. However, these emergency scenarios are long-tailed and hard to collect, which restricts the system from getting reliable predictions. In this paper, we build a new dataset, which aims at the long-term prediction with the inconspicuous state variation in history for the emergency event, named the Extro-Spective Prediction (ESP) problem. Based on the proposed dataset, a flexible feature encoder for ESP is introduced to various prediction methods as a seamless plug-in, and its consistent performance improvement underscores its efficacy. Furthermore, a new metric named clamped temporal error (CTE) is proposed to give a more comprehensive evaluation of prediction performance, especially in time-sensitive emergency events of subseconds. Interestingly, as our ESP features can be described in human-readable language naturally, the application of integrating into ChatGPT also shows huge potential. The ESP-dataset and all benchmarks are released at https://dingrui-wang.github.io/ESP-Dataset/.