 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthSim: Towards Authentic and Effective Safety-critical Scenario Generation for Autonomous Driving Tests
Feb 28, 2025Generating adversarial safety-critical scenarios is a pivotal method for testing autonomous driving systems, as it identifies potential weaknesses and enhances system robustness and reliability. However, existing approaches predominantly emphasize unrestricted collision scenarios, prompting non-player character (NPC) vehicles to attack the ego vehicle indiscriminately. These works overlook these scenarios' authenticity, rationality, and relevance, resulting in numerous extreme, contrived, and largely unrealistic collision events involving aggressive NPC vehicles. To rectify this issue, we propose a three-layer relative safety region model, which partitions the area based on danger levels and increases the likelihood of NPC vehicles entering relative boundary regions. This model directs NPC vehicles to engage in adversarial actions within relatively safe boundary regions, thereby augmenting the scenarios' authenticity. We introduce AuthSim, a comprehensive platform for generating authentic and effective safety-critical scenarios by integrating the three-layer relative safety region model with reinforcement learning. To our knowledge, this is the first attempt to address the authenticity and effectiveness of autonomous driving system test scenarios comprehensively. Extensive experiments demonstrate that AuthSim outperforms existing methods in generating effective safety-critical scenarios. Notably, AuthSim achieves a 5.25% improvement in average cut-in distance and a 27.12% enhancement in average collision interval time, while maintaining higher efficiency in generating effective safety-critical scenarios compared to existing methods. This underscores its significant advantage in producing authentic scenarios over current methodologies.
SLCGC: A lightweight Self-supervised Low-pass Contrastive Graph Clustering Network for Hyperspectral Images
Feb 05, 2025Self-supervised hyperspectral image (HSI) clustering remains a fundamental yet challenging task due to the absence of labeled data and the inherent complexity of spatial-spectral interactions. While recent advancements have explored innovative approaches, existing methods face critical limitations in clustering accuracy, feature discriminability, computational efficiency, and robustness to noise, hindering their practical deployment. In this paper, a self-supervised efficient low-pass contrastive graph clustering (SLCGC) is introduced for HSIs. Our approach begins with homogeneous region generation, which aggregates pixels into spectrally consistent regions to preserve local spatial-spectral coherence while drastically reducing graph complexity. We then construct a structural graph using an adjacency matrix A and introduce a low-pass graph denoising mechanism to suppress high-frequency noise in the graph topology, ensuring stable feature propagation. A dual-branch graph contrastive learning module is developed, where Gaussian noise perturbations generate augmented views through two multilayer perceptrons (MLPs), and a cross-view contrastive loss enforces structural consistency between views to learn noise-invariant representations. Finally, latent embeddings optimized by this process are clustered via K-means. Extensive experiments and repeated comparative analysis have verified that our SLCGC contains high clustering accuracy, low computational complexity, and strong robustness. The code source will be available at https://github.com/DY-HYX.
Adaptive Homophily Clustering: Structure Homophily Graph Learning with Adaptive Filter for Hyperspectral Image
Jan 07, 2025



Hyperspectral image (HSI) clustering has been a fundamental but challenging task with zero training labels. Currently, some deep graph clustering methods have been successfully explored for HSI due to their outstanding performance in effective spatial structural information encoding. Nevertheless, insufficient structural information utilization, poor feature presentation ability, and weak graph update capability limit their performance. Thus, in this paper, a homophily structure graph learning with an adaptive filter clustering method (AHSGC) for HSI is proposed. Specifically, homogeneous region generation is first developed for HSI processing and constructing the original graph. Afterward, an adaptive filter graph encoder is designed to adaptively capture the high and low frequency features on the graph for subsequence processing. Then, a graph embedding clustering self-training decoder is developed with KL Divergence, with which the pseudo-label is generated for network training. Meanwhile, homophily-enhanced structure learning is introduced to update the graph according to the clustering task, in which the orient correlation estimation is adopted to estimate the node connection, and graph edge sparsification is designed to adjust the edges in the graph dynamically. Finally, a joint network optimization is introduced to achieve network self-training and update the graph. The K-means is adopted to express the latent features. Extensive experiments and repeated comparative analysis have verified that our AHSGC contains high clustering accuracy, low computational complexity, and strong robustness. The code source will be available at https://github.com/DY-HYX.
Momentum for the Win: Collaborative Federated Reinforcement Learning across Heterogeneous Environments
May 29, 2024



We explore a Federated Reinforcement Learning (FRL) problem where $N$ agents collaboratively learn a common policy without sharing their trajectory data. To date, existing FRL work has primarily focused on agents operating in the same or ``similar" environments. In contrast, our problem setup allows for arbitrarily large levels of environment heterogeneity. To obtain the optimal policy which maximizes the average performance across all potentially completely different environments, we propose two algorithms: FedSVRPG-M and FedHAPG-M. In contrast to existing results, we demonstrate that both FedSVRPG-M and FedHAPG-M, both of which leverage momentum mechanisms, can exactly converge to a stationary point of the average performance function, regardless of the magnitude of environment heterogeneity. Furthermore, by incorporating the benefits of variance-reduction techniques or Hessian approximation, both algorithms achieve state-of-the-art convergence results, characterized by a sample complexity of $\mathcal{O}\left(\epsilon^{-\frac{3}{2}}/N\right)$. Notably, our algorithms enjoy linear convergence speedups with respect to the number of agents, highlighting the benefit of collaboration among agents in finding a common policy.
Enhanced Automated Quality Assessment Network for Interactive Building Segmentation in High-Resolution Remote Sensing Imagery
Jan 18, 2024In this research, we introduce the enhanced automated quality assessment network (IBS-AQSNet), an innovative solution for assessing the quality of interactive building segmentation within high-resolution remote sensing imagery. This is a new challenge in segmentation quality assessment, and our proposed IBS-AQSNet allievate this by identifying missed and mistaken segment areas. First of all, to acquire robust image features, our method combines a robust, pre-trained backbone with a lightweight counterpart for comprehensive feature extraction from imagery and segmentation results. These features are then fused through a simple combination of concatenation, convolution layers, and residual connections. Additionally, ISR-AQSNet incorporates a multi-scale differential quality assessment decoder, proficient in pinpointing areas where segmentation result is either missed or mistaken. Experiments on a newly-built EVLab-BGZ dataset, which includes over 39,198 buildings, demonstrate the superiority of the proposed method in automating segmentation quality assessment, thereby setting a new benchmark in the field.
Safe and Robust Multi-Agent Reinforcement Learning for Connected Autonomous Vehicles under State Perturbations
Sep 20, 2023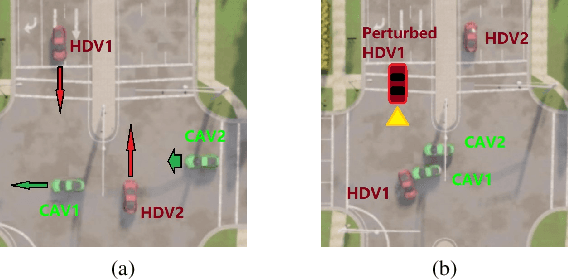

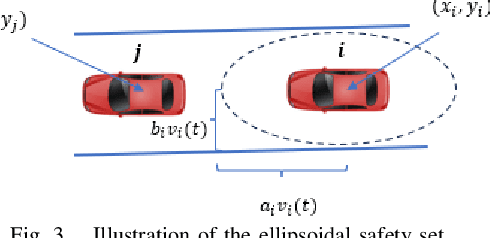

Sensing and communication technologies have enhanced learning-based decision making methodologies for multi-agent systems such as connected autonomous vehicles (CAV). However, most existing safe reinforcement learning based methods assume accurate state information. It remains challenging to achieve safety requirement under state uncertainties for CAVs, considering the noisy sensor measurements and the vulnerability of communication channels. In this work, we propose a Robust Multi-Agent Proximal Policy Optimization with robust Safety Shield (SR-MAPPO) for CAVs in various driving scenarios. Both robust MARL algorithm and control barrier function (CBF)-based safety shield are used in our approach to cope with the perturbed or uncertain state inputs. The robust policy is trained with a worst-case Q function regularization module that pursues higher lower-bounded reward in the former, whereas the latter, i.e., the robust CBF safety shield accounts for CAVs' collision-free constraints in complicated driving scenarios with even perturbed vehicle state information. We validate the advantages of SR-MAPPO in robustness and safety and compare it with baselines under different driving and state perturbation scenarios in CARLA simulator. The SR-MAPPO policy is verified to maintain higher safety rates and efficiency (reward) when threatened by both state perturbations and unconnected vehicles' dangerous behaviors.
Multi-Agent Reinforcement Learning Guided by Signal Temporal Logic Specifications
Jun 11, 2023
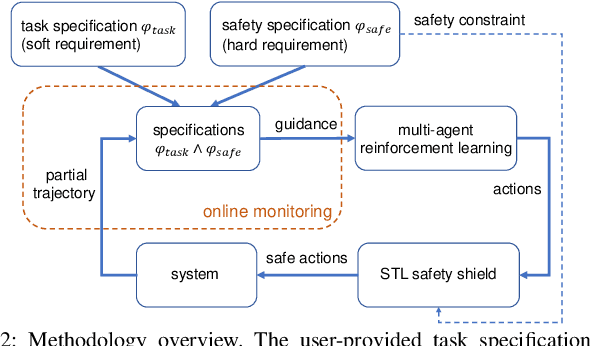
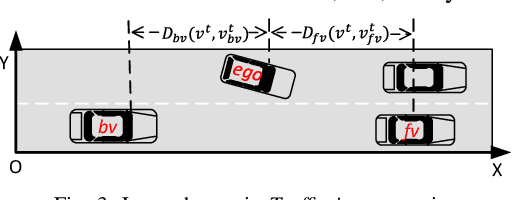
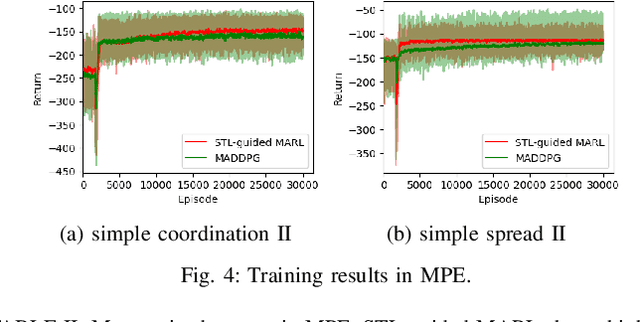
There has been growing interest in deep reinforcement learning (DRL) algorithm design, and reward design is one key component of DRL. Among the various techniques, formal methods integrated with DRL have garnered considerable attention due to their expressiveness and ability to define the requirements for the states and actions of the agent. However, the literature of Signal Temporal Logic (STL) in guiding multi-agent reinforcement learning (MARL) reward design remains limited. In this paper, we propose a novel STL-guided multi-agent reinforcement learning algorithm. The STL specifications are designed to include both task specifications according to the objective of each agent and safety specifications, and the robustness values of the STL specifications are leveraged to generate rewards. We validate the advantages of our method through empirical studies. The experimental results demonstrate significant performance improvements compared to MARL without STL guidance, along with a remarkable increase in the overall safety rate of the multi-agent systems.
Collaborative Multi-Object Tracking with Conformal Uncertainty Propagation
Mar 25, 2023



Object detection and multiple object tracking (MOT) are essential components of self-driving systems. Accurate detection and uncertainty quantification are both critical for onboard modules, such as perception, prediction, and planning, to improve the safety and robustness of autonomous vehicles. Collaborative object detection (COD) has been proposed to improve detection accuracy and reduce uncertainty by leveraging the viewpoints of multiple agents. However, little attention has been paid on how to leverage the uncertainty quantification from COD to enhance MOT performance. In this paper, as the first attempt, we design the uncertainty propagation framework to address this challenge, called MOT-CUP. Our framework first quantifies the uncertainty of COD through direct modeling and conformal prediction, and propogates this uncertainty information during the motion prediction and association steps. MOT-CUP is designed to work with different collaborative object detectors and baseline MOT algorithms. We evaluate MOT-CUP on V2X-Sim, a comprehensive collaborative perception dataset, and demonstrate a 2% improvement in accuracy and a 2.67X reduction in uncertainty compared to the baselines, e.g., SORT and ByteTrack. MOT-CUP demonstrates the importance of uncertainty quantification in both COD and MOT, and provides the first attempt to improve the accuracy and reduce the uncertainty in MOT based on COD through uncertainty propogation.
Data-Driven Distributionally Robust Electric Vehicle Balancing for Autonomous Mobility-on-Demand Systems under Demand and Supply Uncertainties
Nov 24, 2022
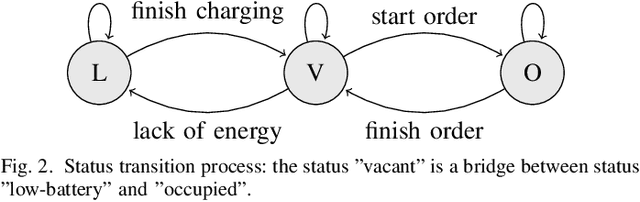
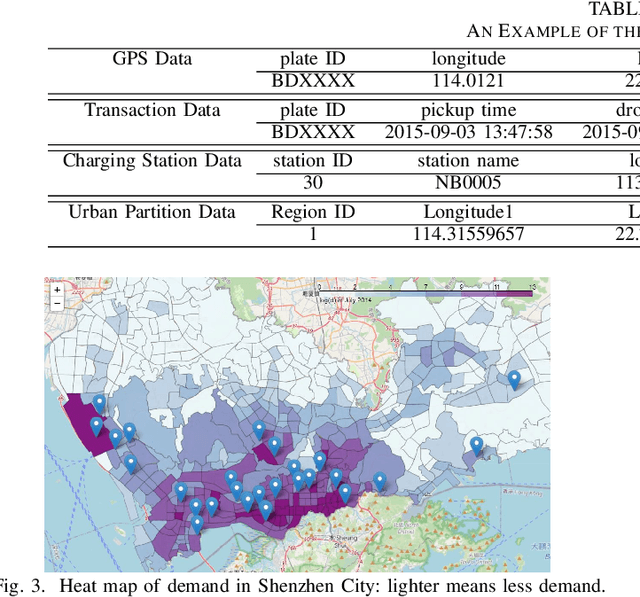
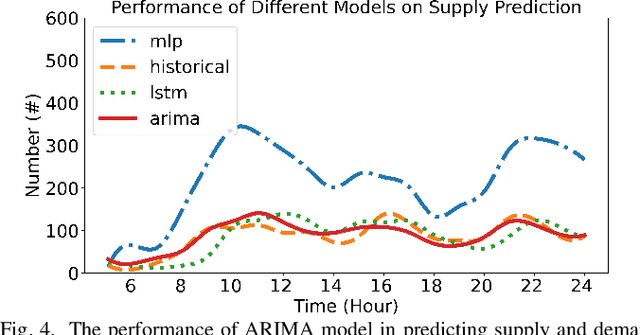
Electric vehicles (EVs) are being rapidly adopted due to their economic and societal benefits. Autonomous mobility-on-demand (AMoD) systems also embrace this trend. However, the long charging time and high recharging frequency of EVs pose challenges to efficiently managing EV AMoD systems. The complicated dynamic charging and mobility process of EV AMoD systems makes the demand and supply uncertainties significant when designing vehicle balancing algorithms. In this work, we design a data-driven distributionally robust optimization (DRO) approach to balance EVs for both the mobility service and the charging process. The optimization goal is to minimize the worst-case expected cost under both passenger mobility demand uncertainties and EV supply uncertainties. We then propose a novel distributional uncertainty sets construction algorithm that guarantees the produced parameters are contained in desired confidence regions with a given probability. To solve the proposed DRO AMoD EV balancing problem, we derive an equivalent computationally tractable convex optimization problem. Based on real-world EV data of a taxi system, we show that with our solution the average total balancing cost is reduced by 14.49%, and the average mobility fairness and charging fairness are improved by 15.78% and 34.51%, respectively, compared to solutions that do not consider uncertainties.
Spatial-Temporal-Aware Safe Multi-Agent Reinforcement Learning of Connected Autonomous Vehicles in Challenging Scenarios
Oct 05, 2022
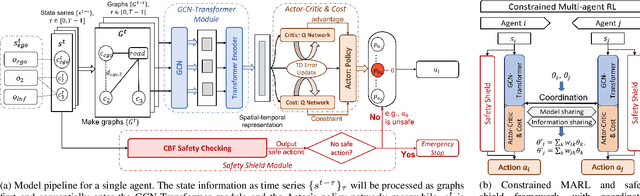
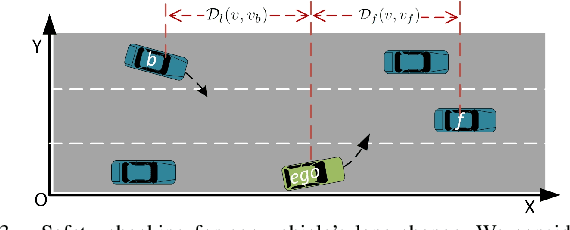

Communication technologies enable coordination among connected and autonomous vehicles (CAVs). However, it remains unclear how to utilize shared information to improve the safety and efficiency of the CAV system. In this work, we propose a framework of constrained multi-agent reinforcement learning (MARL) with a parallel safety shield for CAVs in challenging driving scenarios. The coordination mechanisms of the proposed MARL include information sharing and cooperative policy learning, with Graph Convolutional Network (GCN)-Transformer as a spatial-temporal encoder that enhances the agent's environment awareness. The safety shield module with Control Barrier Functions (CBF)-based safety checking protects the agents from taking unsafe actions. We design a constrained multi-agent advantage actor-critic (CMAA2C) algorithm to train safe and cooperative policies for CAVs. With the experiment deployed in the CARLA simulator, we verify the effectiveness of the safety checking, spatial-temporal encoder, and coordination mechanisms designed in our method by comparative experiments in several challenging scenarios with the defined hazard vehicles (HAZV). Results show that our proposed methodology significantly increases system safety and efficiency in challenging scenarios.