 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmo-FOLD: Fast generation and upscaling of field-level cosmological maps with overlap latent diffusion
Jan 20, 2026We demonstrate the capabilities of probabilistic diffusion models to reduce dramatically the computational cost of expensive hydrodynamical simulations to study the relationship between observable baryonic cosmological probes and dark matter at field level and well into the non-linear regime. We introduce a novel technique, Cosmo-FOLD (Cosmological Fields via Overlap Latent Diffusion) to rapidly generate accurate and arbitrarily large cosmological and astrophysical 3-dimensional fields, conditioned on a given input field. We are able to generate TNG300-2 dark matter density and gas temperature fields from a model trained only on ~1% of the volume (a process we refer to as `upscaling'), reproducing both large scale coherent dark matter filaments and power spectra to within 10% for wavenumbers k <= 5 h Mpc^-1. These results are obtained within a small fraction of the original simulation cost and produced on a single GPU. Beyond one and two points statistics, the bispectrum is also faithfully reproduced through the inclusion of positional encodings. Finally, we demonstrate Cosmo-FOLD's generalisation capabilities by upscaling a CAMELS volume of 25 (Mpc h^-1)^3 to a full TNG300-2 volume of 205 (Mpc h^-1)^3$ with no fine-tuning. Cosmo-FOLD opens the door to full field-level simulation-based inference on cosmological scale.
Opportunities in AI/ML for the Rubin LSST Dark Energy Science Collaboration
Jan 20, 2026The Vera C. Rubin Observatory's Legacy Survey of Space and Time (LSST) will produce unprecedented volumes of heterogeneous astronomical data (images, catalogs, and alerts) that challenge traditional analysis pipelines. The LSST Dark Energy Science Collaboration (DESC) aims to derive robust constraints on dark energy and dark matter from these data, requiring methods that are statistically powerful, scalable, and operationally reliable. Artificial intelligence and machine learning (AI/ML) are already embedded across DESC science workflows, from photometric redshifts and transient classification to weak lensing inference and cosmological simulations. Yet their utility for precision cosmology hinges on trustworthy uncertainty quantification, robustness to covariate shift and model misspecification, and reproducible integration within scientific pipelines. This white paper surveys the current landscape of AI/ML across DESC's primary cosmological probes and cross-cutting analyses, revealing that the same core methodologies and fundamental challenges recur across disparate science cases. Since progress on these cross-cutting challenges would benefit multiple probes simultaneously, we identify key methodological research priorities, including Bayesian inference at scale, physics-informed methods, validation frameworks, and active learning for discovery. With an eye on emerging techniques, we also explore the potential of the latest foundation model methodologies and LLM-driven agentic AI systems to reshape DESC workflows, provided their deployment is coupled with rigorous evaluation and governance. Finally, we discuss critical software, computing, data infrastructure, and human capital requirements for the successful deployment of these new methodologies, and consider associated risks and opportunities for broader coordination with external actors.
Rotary Masked Autoencoders are Versatile Learners
May 26, 2025Applying Transformers to irregular time-series typically requires specializations to their baseline architecture, which can result in additional computational overhead and increased method complexity. We present the Rotary Masked Autoencoder (RoMAE), which utilizes the popular Rotary Positional Embedding (RoPE) method for continuous positions. RoMAE is an extension to the Masked Autoencoder (MAE) that enables representation learning with multidimensional continuous positional information while avoiding any time-series-specific architectural specializations. We showcase RoMAE's performance on a variety of modalities including irregular and multivariate time-series, images, and audio, demonstrating that RoMAE surpasses specialized time-series architectures on difficult datasets such as the DESC ELAsTiCC Challenge while maintaining MAE's usual performance across other modalities. In addition, we investigate RoMAE's ability to reconstruct the embedded continuous positions, demonstrating that including learned embeddings in the input sequence breaks RoPE's relative position property.
Detecting Localized Density Anomalies in Multivariate Data via Coin-Flip Statistics
Mar 31, 2025



Detecting localized density differences in multivariate data is a crucial task in computational science. Such anomalies can indicate a critical system failure, lead to a groundbreaking scientific discovery, or reveal unexpected changes in data distribution. We introduce EagleEye, an anomaly detection method to compare two multivariate datasets with the aim of identifying local density anomalies, namely over- or under-densities affecting only localised regions of the feature space. Anomalies are detected by modelling, for each point, the ordered sequence of its neighbours' membership label as a coin-flipping process and monitoring deviations from the expected behaviour of such process. A unique advantage of our method is its ability to provide an accurate, entirely unsupervised estimate of the local signal purity. We demonstrate its effectiveness through experiments on both synthetic and real-world datasets. In synthetic data, EagleEye accurately detects anomalies in multiple dimensions even when they affect a tiny fraction of the data. When applied to a challenging resonant anomaly detection benchmark task in simulated Large Hadron Collider data, EagleEye successfully identifies particle decay events present in just 0.3% of the dataset. In global temperature data, EagleEye uncovers previously unidentified, geographically localised changes in temperature fields that occurred in the most recent years. Thanks to its key advantages of conceptual simplicity, computational efficiency, trivial parallelisation, and scalability, EagleEye is widely applicable across many fields.
Human-LLM Coevolution: Evidence from Academic Writing
Feb 13, 2025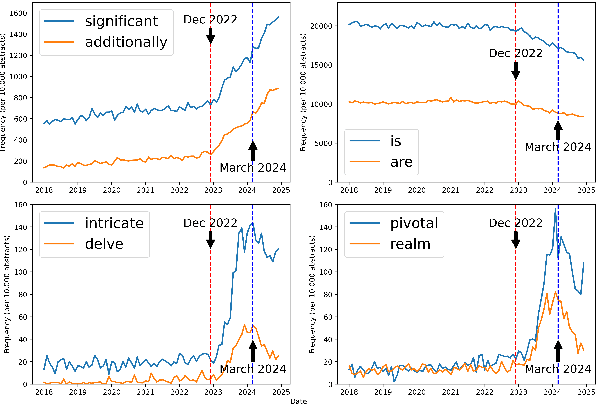

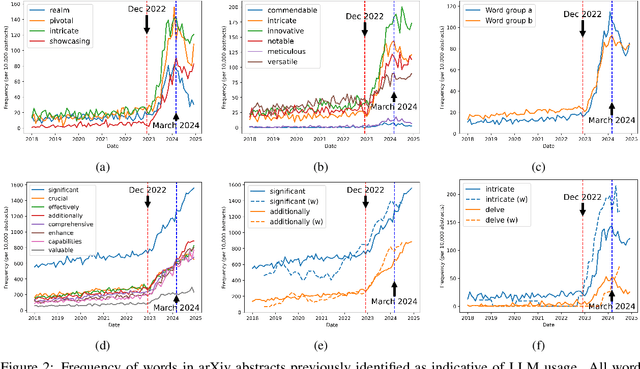
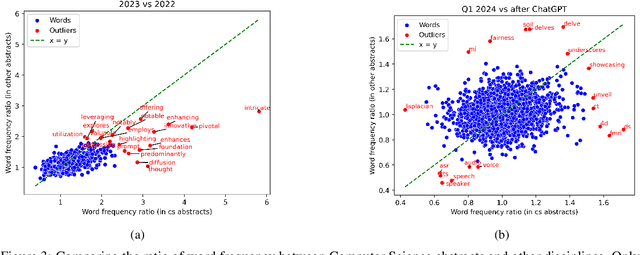
With a statistical analysis of arXiv paper abstracts, we report a marked drop in the frequency of several words previously identified as overused by ChatGPT, such as "delve", starting soon after they were pointed out in early 2024. The frequency of certain other words favored by ChatGPT, such as "significant", has instead kept increasing. These phenomena suggest that some authors of academic papers have adapted their use of large language models (LLMs), for example, by selecting outputs or applying modifications to the LLM-generated content. Such coevolution and cooperation of humans and LLMs thus introduce additional challenges to the detection of machine-generated text in real-world scenarios. Estimating the impact of LLMs on academic writing by examining word frequency remains feasible, and more attention should be paid to words that were already frequently employed, including those that have decreased in frequency.
Are Large Language Models Chameleons?
May 29, 2024


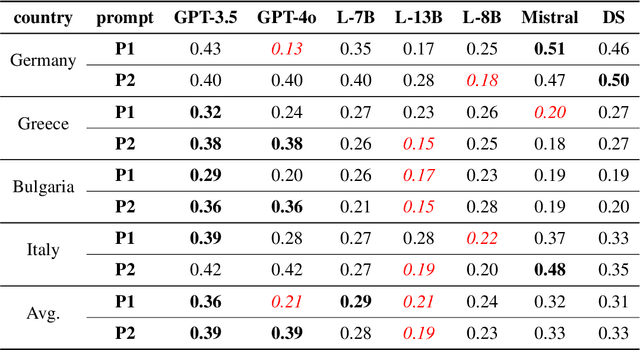
Do large language models (LLMs) have their own worldviews and personality tendencies? Simulations in which an LLM was asked to answer subjective questions were conducted more than 1 million times. Comparison of the responses from different LLMs with real data from the European Social Survey (ESS) suggests that the effect of prompts on bias and variability is fundamental, highlighting major cultural, age, and gender biases. Methods for measuring the difference between LLMs and survey data are discussed, such as calculating weighted means and a new proposed measure inspired by Jaccard similarity. We conclude that it is important to analyze the robustness and variability of prompts before using LLMs to model individual decisions or collective behavior, as their imitation abilities are approximate at best.
floZ: Evidence estimation from posterior samples with normalizing flows
Apr 18, 2024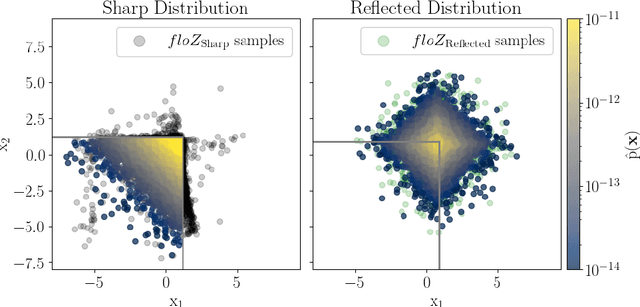
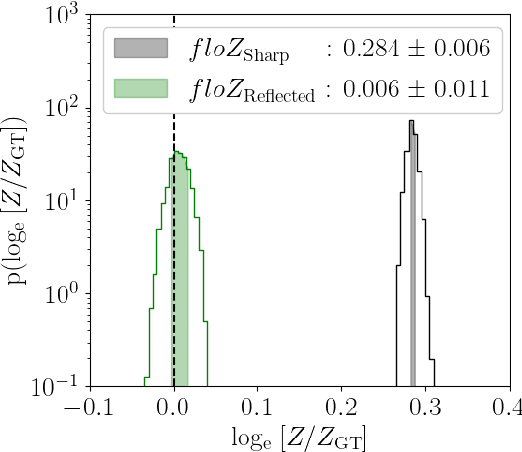
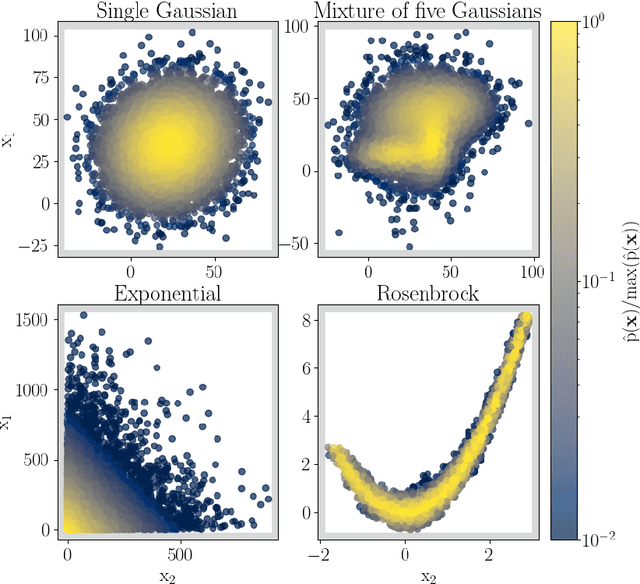
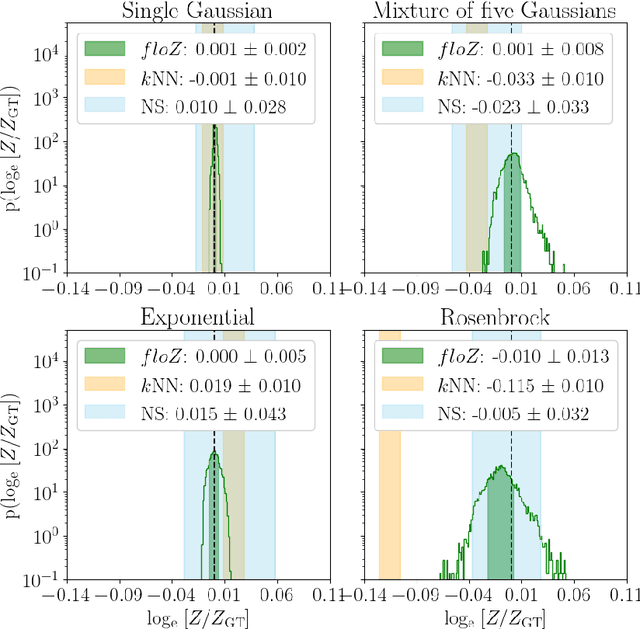
We propose a novel method (floZ), based on normalizing flows, for estimating the Bayesian evidence (and its numerical uncertainty) from a set of samples drawn from the unnormalized posterior distribution. We validate it on distributions whose evidence is known analytically, up to 15 parameter space dimensions, and compare with two state-of-the-art techniques for estimating the evidence: nested sampling (which computes the evidence as its main target) and a k-nearest-neighbors technique that produces evidence estimates from posterior samples. Provided representative samples from the target posterior are available, our method is more robust to posterior distributions with sharp features, especially in higher dimensions. It has wide applicability, e.g., to estimate the evidence from variational inference, Markov-chain Monte Carlo samples, or any other method that delivers samples from the unnormalized posterior density.
Is ChatGPT Transforming Academics' Writing Style?
Apr 12, 2024



Based on one million arXiv papers submitted from May 2018 to January 2024, we assess the textual density of ChatGPT's writing style in their abstracts by means of a statistical analysis of word frequency changes. Our model is calibrated and validated on a mixture of real abstracts and ChatGPT-modified abstracts (simulated data) after a careful noise analysis. We find that ChatGPT is having an increasing impact on arXiv abstracts, especially in the field of computer science, where the fraction of ChatGPT-revised abstracts is estimated to be approximately 35%, if we take the output of one of the simplest prompts, "revise the following sentences", as a baseline. We conclude with an analysis of both positive and negative aspects of the penetration of ChatGPT into academics' writing style.
Stratified Learning: a general-purpose statistical method for improved learning under Covariate Shift
Jun 21, 2021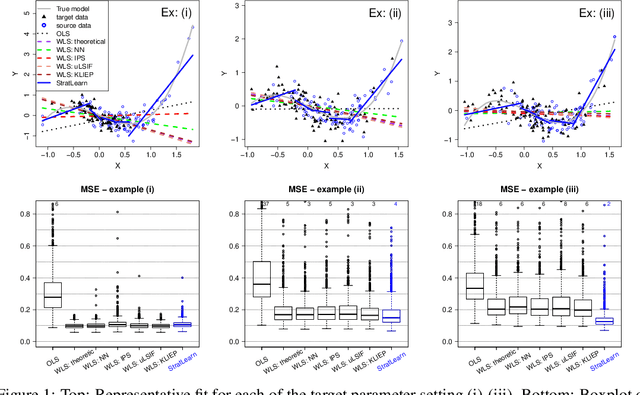
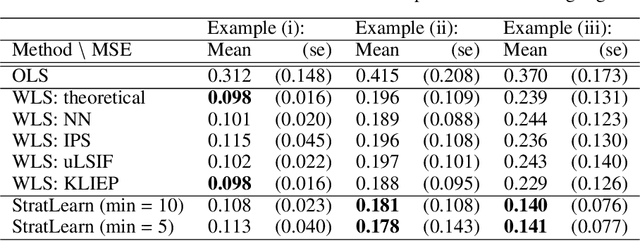
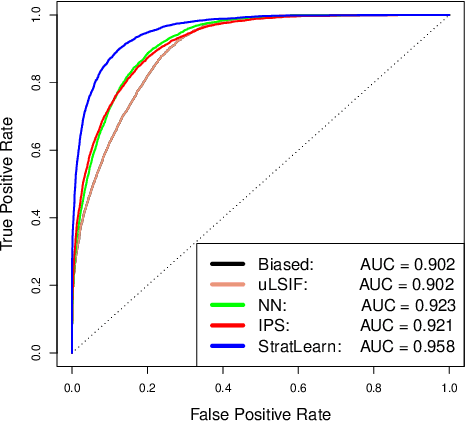
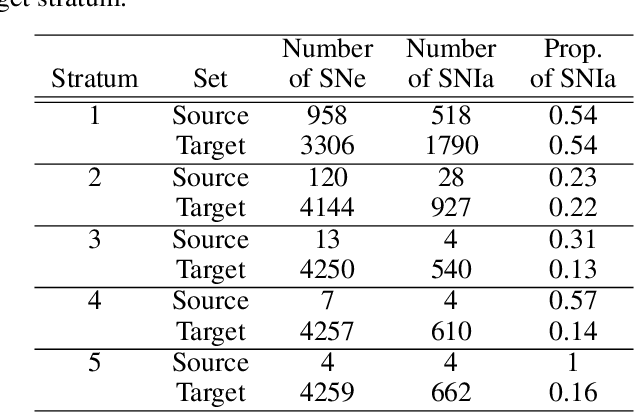
Covariate shift arises when the labelled training (source) data is not representative of the unlabelled (target) data due to systematic differences in the covariate distributions. A supervised model trained on the source data subject to covariate shift may suffer from poor generalization on the target data. We propose a novel, statistically principled and theoretically justified method to improve learning under covariate shift conditions, based on propensity score stratification, a well-established methodology in causal inference. We show that the effects of covariate shift can be reduced or altogether eliminated by conditioning on propensity scores. In practice, this is achieved by fitting learners on subgroups ("strata") constructed by partitioning the data based on the estimated propensity scores, leading to balanced covariates and much-improved target prediction. We demonstrate the effectiveness of our general-purpose method on contemporary research questions in observational cosmology, and on additional benchmark examples, matching or outperforming state-of-the-art importance weighting methods, widely studied in the covariate shift literature. We obtain the best reported AUC (0.958) on the updated "Supernovae photometric classification challenge" and improve upon existing conditional density estimation of galaxy redshift from Sloan Data Sky Survey (SDSS) data.