 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStratified Learning: a general-purpose statistical method for improved learning under Covariate Shift
Paper and Code
Jun 21, 2021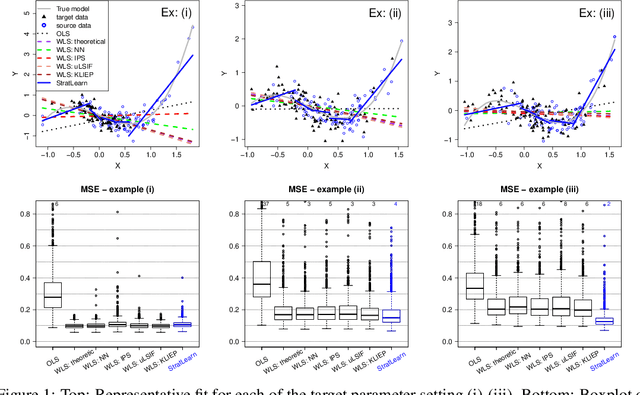
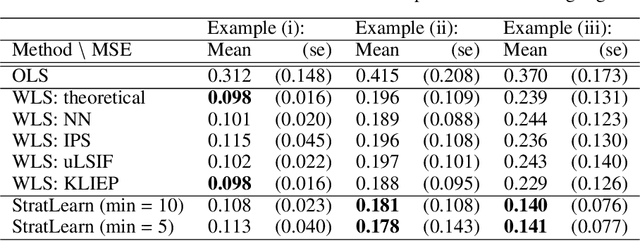
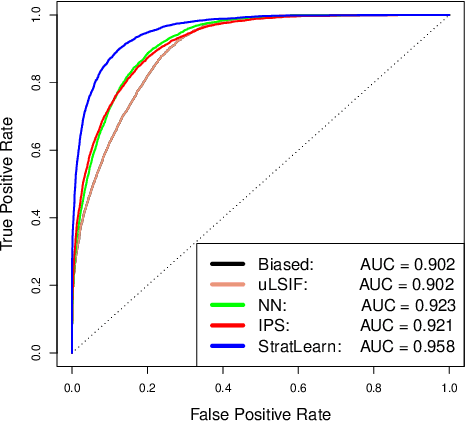
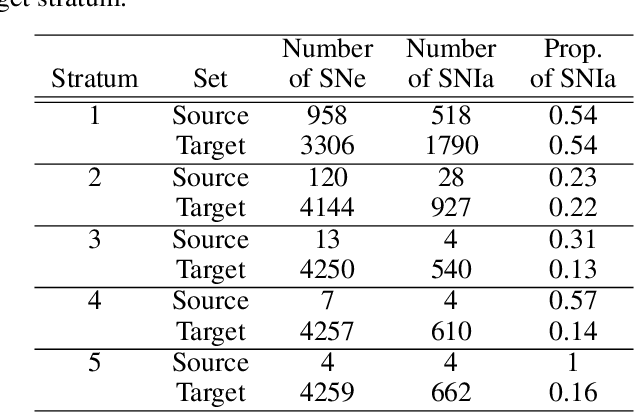
Covariate shift arises when the labelled training (source) data is not representative of the unlabelled (target) data due to systematic differences in the covariate distributions. A supervised model trained on the source data subject to covariate shift may suffer from poor generalization on the target data. We propose a novel, statistically principled and theoretically justified method to improve learning under covariate shift conditions, based on propensity score stratification, a well-established methodology in causal inference. We show that the effects of covariate shift can be reduced or altogether eliminated by conditioning on propensity scores. In practice, this is achieved by fitting learners on subgroups ("strata") constructed by partitioning the data based on the estimated propensity scores, leading to balanced covariates and much-improved target prediction. We demonstrate the effectiveness of our general-purpose method on contemporary research questions in observational cosmology, and on additional benchmark examples, matching or outperforming state-of-the-art importance weighting methods, widely studied in the covariate shift literature. We obtain the best reported AUC (0.958) on the updated "Supernovae photometric classification challenge" and improve upon existing conditional density estimation of galaxy redshift from Sloan Data Sky Survey (SDSS) data.