 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRogueMerge: Robust and Unified Attacks against LLM Model Merging
Jun 02, 2026Model merging composes specialized capabilities into a single LLM by aggregating task vectors sourced from unverified public platforms, exposing a critical supply-chain attack surface: Because any malicious behavior can be encoded into a task vector, and merging grants third-party vectors direct write access to model weights, an attacker-provided task vector can enable or amplify diverse downstream threats. Prior work studies only backdoor attacks against model merging for classifiers using static arithmetic heuristics, which fail to effectively handle diverse attacks on generative LLMs for three reasons. (i) LLMs rely on autoregressive decoding, where the minor parameter drift introduced by merging compounds across tokens and rapidly degrades the attack. (ii) Attackers have no knowledge of the victim's merging configurations, causing a static attack vector optimized in isolation to be easily diluted or destroyed. (iii) Practical threat induction must generalize to attack prompts unseen during optimization, which static vectors cannot adequately encode. We present RogueMerge, the first principled, unified framework that addresses all three challenges. To handle autoregressive generation, we replace static arithmetic with a joint optimization that explicitly enforces attack success after merging. To handle unknown merging settings, we formulate attack injection as a stochastic min-max problem and solve it via meta-learning-style simulation. To generalize across heterogeneous attack prompts, we employ distributionally robust optimization and derive a tractable first-order Taylor approximation at LLM scale, with a provable error bound. Across four threats, six merging algorithms, and over 170 merged LLMs, RogueMerge consistently outperforms existing attacks. It also remains stable across diverse merging settings and resists standard defenses.
Token Inflation: How Dishonest Providers Can Overcharge for Large Language Model Usage
May 28, 2026Per-token billing is now the standard pricing model for commercial large language models (LLMs), so the honesty of reported token counts directly affects what users pay. We show that this kind of billing is hard to audit by design: providers hide the model, the tokenizer, and the execution to protect their IP, mitigate jailbreaks, and preserve user privacy, which means an auditor can only inspect proofs the provider supplies. The audit therefore reduces to a consistency check on the provider's own reports. We call this a trust paradox: every audit must trust some artifact, but current frameworks trust exactly the ones a provider has the strongest reason to manipulate. We study three recent token auditing frameworks and show that a provider with ordinary commercial capabilities can systematically inflate billed token counts. In the most permissive setting, hidden reasoning usage can be inflated by 1,469% on average without detection. At current frontier reasoning prices, that turns a \$100 honest bill into roughly a \$1,569 bill on the same query. Even when the user can see the full reasoning string, tokenization ambiguity alone still allows 50.85% over-reporting below the detection threshold. These results suggest the problem is not in any specific auditor but in any audit whose evidence comes from the audited party. Restoring honest billing will require verification that ties reported token counts to evidence the provider does not control, such as trusted execution attestation, cryptographic proofs of inference, or third-party re-execution.
What-If World: A Causal Benchmark for General World Models in Embodied Scenarios
May 26, 2026Video generation models are increasingly used as world simulators for tasks like driving and robotic manipulation. What matters in these settings is not whether a single video looks right, but whether the model's output changes when its input changes. We test this by giving a model two prompts describing the same scene with one physical detail varied, and checking whether the two videos diverge the way physics predicts. The wording difference between the prompts is small by design, since only one variable is changed, but the correct physical difference is not. A model that misses this can still produce two videos that each look plausible individually, and existing benchmarks score videos one at a time and cannot detect this failure. We introduce What-If World, 319 such prompt pairs built on real frames from nuScenes and DROID, organized by a taxonomy of six physical variables shared across driving and manipulation. Each pair is scored with APEO, a four-part rubric checking whether each video follows its prompt (Adherence), is physically consistent (Physics), preserves the shared scene (Environment), and ends in the correct difference (Outcome). Across nine state-of-the-art models, no system exceeds 52% on the paired score, and open-source models cluster near 28%. Every model tested fails on a large fraction of causal interventions, indicating substantial room before these models can reliably support action-conditioned simulation or model-based planning. Where models do score well, performance appears to track the visual prominence of the intervention rather than the tractability of its underlying physics. Some visually subtle interventions score as low as 14.2%, while visually pronounced ones reach 40.4%.
HIDBench: Benchmarking Large Language Models for Host-Based Intrusion Detection
May 20, 2026Recent benchmark efforts have advanced the evaluation of large language models (LLMs) in cybersecurity, including tasks such as penetration testing and vulnerability identification. However, a critical cybersecurity task, namely intrusion detection from system logs, remains unexplored. In this work, we present a new benchmark to assess LLMs' capabilities in supporting host-based intrusion detection systems (HIDS). This task requires fine-grained reasoning over large-scale, noisy, and highly imbalanced system logs, where complex interactions between benign and malicious activities make reliable detection challenging. Our benchmark unifies three public system log datasets, DARPA-E3, DARPA-E5, and NodLink, and introduces a data construction pipeline that transforms raw host telemetry into LLM-compatible inputs, enabling systematic evaluation under realistic intrusion detection settings. Our evaluation of frontier LLMs reveals substantial performance gaps across datasets. While many models achieve high precision (often above 0.8) on simpler datasets, their performance degrades significantly as system logs become noisier and more complex, with MCC frequently dropping below 0.5 and false positive rates increasing sharply. We further analyze model behavior and identify distinct regimes, including conservative detectors with low false positive rates and over-sensitive models that generate excessive alerts. Overall, our results highlight that while LLMs show strong potential for HIDS, their effectiveness is highly sensitive to data complexity, and robust system design is essential for reliable deployment.
ACIArena: Toward Unified Evaluation for Agent Cascading Injection
Apr 09, 2026Collaboration and information sharing empower Multi-Agent Systems (MAS) but also introduce a critical security risk known as Agent Cascading Injection (ACI). In such attacks, a compromised agent exploits inter-agent trust to propagate malicious instructions, causing cascading failures across the system. However, existing studies consider only limited attack strategies and simplified MAS settings, limiting their generalizability and comprehensive evaluation. To bridge this gap, we introduce ACIArena, a unified framework for evaluating the robustness of MAS. ACIArena offers systematic evaluation suites spanning multiple attack surfaces (i.e., external inputs, agent profiles, inter-agent messages) and attack objectives (i.e., instruction hijacking, task disruption, information exfiltration). Specifically, ACIArena establishes a unified specification that jointly supports MAS construction and attack-defense modules. It covers six widely used MAS implementations and provides a benchmark of 1,356 test cases for systematically evaluating MAS robustness. Our benchmarking results show that evaluating MAS robustness solely through topology is insufficient; robust MAS require deliberate role design and controlled interaction patterns. Moreover, defenses developed in simplified environments often fail to transfer to real-world settings; narrowly scoped defenses may even introduce new vulnerabilities. ACIArena aims to provide a solid foundation for advancing deeper exploration of MAS design principles.
The Landscape of Prompt Injection Threats in LLM Agents: From Taxonomy to Analysis
Feb 11, 2026The evolution of Large Language Models (LLMs) has resulted in a paradigm shift towards autonomous agents, necessitating robust security against Prompt Injection (PI) vulnerabilities where untrusted inputs hijack agent behaviors. This SoK presents a comprehensive overview of the PI landscape, covering attacks, defenses, and their evaluation practices. Through a systematic literature review and quantitative analysis, we establish taxonomies that categorize PI attacks by payload generation strategies (heuristic vs. optimization) and defenses by intervention stages (text, model, and execution levels). Our analysis reveals a key limitation shared by many existing defenses and benchmarks: they largely overlook context-dependent tasks, in which agents are authorized to rely on runtime environmental observations to determine actions. To address this gap, we introduce AgentPI, a new benchmark designed to systematically evaluate agent behavior under context-dependent interaction settings. Using AgentPI, we empirically evaluate representative defenses and show that no single approach can simultaneously achieve high trustworthiness, high utility, and low latency. Moreover, we show that many defenses appear effective under existing benchmarks by suppressing contextual inputs, yet fail to generalize to realistic agent settings where context-dependent reasoning is essential. This SoK distills key takeaways and open research problems, offering structured guidance for future research and practical deployment of secure LLM agents.
When Agents "Misremember" Collectively: Exploring the Mandela Effect in LLM-based Multi-Agent Systems
Jan 31, 2026Recent advancements in large language models (LLMs) have significantly enhanced the capabilities of collaborative multi-agent systems, enabling them to address complex challenges. However, within these multi-agent systems, the susceptibility of agents to collective cognitive biases remains an underexplored issue. A compelling example is the Mandela effect, a phenomenon where groups collectively misremember past events as a result of false details reinforced through social influence and internalized misinformation. This vulnerability limits our understanding of memory bias in multi-agent systems and raises ethical concerns about the potential spread of misinformation. In this paper, we conduct a comprehensive study on the Mandela effect in LLM-based multi-agent systems, focusing on its existence, causing factors, and mitigation strategies. We propose MANBENCH, a novel benchmark designed to evaluate agent behaviors across four common task types that are susceptible to the Mandela effect, using five interaction protocols that vary in agent roles and memory timescales. We evaluate agents powered by several LLMs on MANBENCH to quantify the Mandela effect and analyze how different factors affect it. Moreover, we propose strategies to mitigate this effect, including prompt-level defenses (e.g., cognitive anchoring and source scrutiny) and model-level alignment-based defense, achieving an average 74.40% reduction in the Mandela effect compared to the baseline. Our findings provide valuable insights for developing more resilient and ethically aligned collaborative multi-agent systems.
FraudShield: Knowledge Graph Empowered Defense for LLMs against Fraud Attacks
Jan 30, 2026Large language models (LLMs) have been widely integrated into critical automated workflows, including contract review and job application processes. However, LLMs are susceptible to manipulation by fraudulent information, which can lead to harmful outcomes. Although advanced defense methods have been developed to address this issue, they often exhibit limitations in effectiveness, interpretability, and generalizability, particularly when applied to LLM-based applications. To address these challenges, we introduce FraudShield, a novel framework designed to protect LLMs from fraudulent content by leveraging a comprehensive analysis of fraud tactics. Specifically, FraudShield constructs and refines a fraud tactic-keyword knowledge graph to capture high-confidence associations between suspicious text and fraud techniques. The structured knowledge graph augments the original input by highlighting keywords and providing supporting evidence, guiding the LLM toward more secure responses. Extensive experiments show that FraudShield consistently outperforms state-of-the-art defenses across four mainstream LLMs and five representative fraud types, while also offering interpretable clues for the model's generations.
Bridging the Copyright Gap: Do Large Vision-Language Models Recognize and Respect Copyrighted Content?
Dec 26, 2025Large vision-language models (LVLMs) have achieved remarkable advancements in multimodal reasoning tasks. However, their widespread accessibility raises critical concerns about potential copyright infringement. Will LVLMs accurately recognize and comply with copyright regulations when encountering copyrighted content (i.e., user input, retrieved documents) in the context? Failure to comply with copyright regulations may lead to serious legal and ethical consequences, particularly when LVLMs generate responses based on copyrighted materials (e.g., retrieved book experts, news reports). In this paper, we present a comprehensive evaluation of various LVLMs, examining how they handle copyrighted content -- such as book excerpts, news articles, music lyrics, and code documentation when they are presented as visual inputs. To systematically measure copyright compliance, we introduce a large-scale benchmark dataset comprising 50,000 multimodal query-content pairs designed to evaluate how effectively LVLMs handle queries that could lead to copyright infringement. Given that real-world copyrighted content may or may not include a copyright notice, the dataset includes query-content pairs in two distinct scenarios: with and without a copyright notice. For the former, we extensively cover four types of copyright notices to account for different cases. Our evaluation reveals that even state-of-the-art closed-source LVLMs exhibit significant deficiencies in recognizing and respecting the copyrighted content, even when presented with the copyright notice. To solve this limitation, we introduce a novel tool-augmented defense framework for copyright compliance, which reduces infringement risks in all scenarios. Our findings underscore the importance of developing copyright-aware LVLMs to ensure the responsible and lawful use of copyrighted content.
CollabEdit: Towards Non-destructive Collaborative Knowledge Editing
Oct 12, 2024


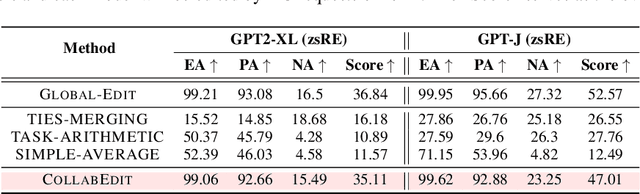
Collaborative learning of large language models (LLMs) has emerged as a new paradigm for utilizing private data from different parties to guarantee efficiency and privacy. Meanwhile, Knowledge Editing (KE) for LLMs has also garnered increased attention due to its ability to manipulate the behaviors of LLMs explicitly, yet leaves the collaborative KE case (in which knowledge edits of multiple parties are aggregated in a privacy-preserving and continual manner) unexamined. To this end, this manuscript dives into the first investigation of collaborative KE, in which we start by carefully identifying the unique three challenges therein, including knowledge overlap, knowledge conflict, and knowledge forgetting. We then propose a non-destructive collaborative KE framework, COLLABEDIT, which employs a novel model merging mechanism to mimic the global KE behavior while preventing the severe performance drop. Extensive experiments on two canonical datasets demonstrate the superiority of COLLABEDIT compared to other destructive baselines, and results shed light on addressing three collaborative KE challenges and future applications.