 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMarkBench: Benchmarking Robustness of Video Watermarking
May 27, 2025The rapid development of video generative models has led to a surge in highly realistic synthetic videos, raising ethical concerns related to disinformation and copyright infringement. Recently, video watermarking has been proposed as a mitigation strategy by embedding invisible marks into AI-generated videos to enable subsequent detection. However, the robustness of existing video watermarking methods against both common and adversarial perturbations remains underexplored. In this work, we introduce VideoMarkBench, the first systematic benchmark designed to evaluate the robustness of video watermarks under watermark removal and watermark forgery attacks. Our study encompasses a unified dataset generated by three state-of-the-art video generative models, across three video styles, incorporating four watermarking methods and seven aggregation strategies used during detection. We comprehensively evaluate 12 types of perturbations under white-box, black-box, and no-box threat models. Our findings reveal significant vulnerabilities in current watermarking approaches and highlight the urgent need for more robust solutions. Our code is available at https://github.com/zhengyuan-jiang/VideoMarkBench.
Jailbreaking Safeguarded Text-to-Image Models via Large Language Models
Mar 03, 2025



Text-to-Image models may generate harmful content, such as pornographic images, particularly when unsafe prompts are submitted. To address this issue, safety filters are often added on top of text-to-image models, or the models themselves are aligned to reduce harmful outputs. However, these defenses remain vulnerable when an attacker strategically designs adversarial prompts to bypass these safety guardrails. In this work, we propose PromptTune, a method to jailbreak text-to-image models with safety guardrails using a fine-tuned large language model. Unlike other query-based jailbreak attacks that require repeated queries to the target model, our attack generates adversarial prompts efficiently after fine-tuning our AttackLLM. We evaluate our method on three datasets of unsafe prompts and against five safety guardrails. Our results demonstrate that our approach effectively bypasses safety guardrails, outperforms existing no-box attacks, and also facilitates other query-based attacks.
SafeText: Safe Text-to-image Models via Aligning the Text Encoder
Feb 28, 2025Text-to-image models can generate harmful images when presented with unsafe prompts, posing significant safety and societal risks. Alignment methods aim to modify these models to ensure they generate only non-harmful images, even when exposed to unsafe prompts. A typical text-to-image model comprises two main components: 1) a text encoder and 2) a diffusion module. Existing alignment methods mainly focus on modifying the diffusion module to prevent harmful image generation. However, this often significantly impacts the model's behavior for safe prompts, causing substantial quality degradation of generated images. In this work, we propose SafeText, a novel alignment method that fine-tunes the text encoder rather than the diffusion module. By adjusting the text encoder, SafeText significantly alters the embedding vectors for unsafe prompts, while minimally affecting those for safe prompts. As a result, the diffusion module generates non-harmful images for unsafe prompts while preserving the quality of images for safe prompts. We evaluate SafeText on multiple datasets of safe and unsafe prompts, including those generated through jailbreak attacks. Our results show that SafeText effectively prevents harmful image generation with minor impact on the images for safe prompts, and SafeText outperforms six existing alignment methods. We will publish our code and data after paper acceptance.
AI-generated Image Detection: Passive or Watermark?
Nov 20, 2024


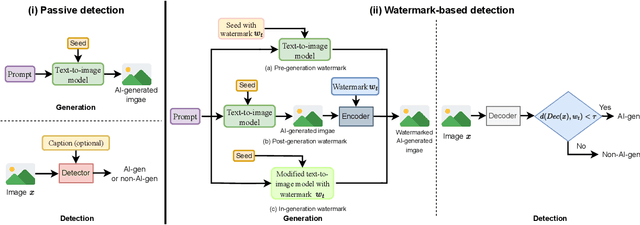
While text-to-image models offer numerous benefits, they also pose significant societal risks. Detecting AI-generated images is crucial for mitigating these risks. Detection methods can be broadly categorized into passive and watermark-based approaches: passive detectors rely on artifacts present in AI-generated images, whereas watermark-based detectors proactively embed watermarks into such images. A key question is which type of detector performs better in terms of effectiveness, robustness, and efficiency. However, the current literature lacks a comprehensive understanding of this issue. In this work, we aim to bridge that gap by developing ImageDetectBench, the first comprehensive benchmark to compare the effectiveness, robustness, and efficiency of passive and watermark-based detectors. Our benchmark includes four datasets, each containing a mix of AI-generated and non-AI-generated images. We evaluate five passive detectors and four watermark-based detectors against eight types of common perturbations and three types of adversarial perturbations. Our benchmark results reveal several interesting findings. For instance, watermark-based detectors consistently outperform passive detectors, both in the presence and absence of perturbations. Based on these insights, we provide recommendations for detecting AI-generated images, e.g., when both types of detectors are applicable, watermark-based detectors should be the preferred choice.
Certifiably Robust Image Watermark
Jul 04, 2024Generative AI raises many societal concerns such as boosting disinformation and propaganda campaigns. Watermarking AI-generated content is a key technology to address these concerns and has been widely deployed in industry. However, watermarking is vulnerable to removal attacks and forgery attacks. In this work, we propose the first image watermarks with certified robustness guarantees against removal and forgery attacks. Our method leverages randomized smoothing, a popular technique to build certifiably robust classifiers and regression models. Our major technical contributions include extending randomized smoothing to watermarking by considering its unique characteristics, deriving the certified robustness guarantees, and designing algorithms to estimate them. Moreover, we extensively evaluate our image watermarks in terms of both certified and empirical robustness. Our code is available at \url{https://github.com/zhengyuan-jiang/Watermark-Library}.
AudioMarkBench: Benchmarking Robustness of Audio Watermarking
Jun 11, 2024



The increasing realism of synthetic speech, driven by advancements in text-to-speech models, raises ethical concerns regarding impersonation and disinformation. Audio watermarking offers a promising solution via embedding human-imperceptible watermarks into AI-generated audios. However, the robustness of audio watermarking against common/adversarial perturbations remains understudied. We present AudioMarkBench, the first systematic benchmark for evaluating the robustness of audio watermarking against watermark removal and watermark forgery. AudioMarkBench includes a new dataset created from Common-Voice across languages, biological sexes, and ages, 3 state-of-the-art watermarking methods, and 15 types of perturbations. We benchmark the robustness of these methods against the perturbations in no-box, black-box, and white-box settings. Our findings highlight the vulnerabilities of current watermarking techniques and emphasize the need for more robust and fair audio watermarking solutions. Our dataset and code are publicly available at \url{https://github.com/moyangkuo/AudioMarkBench}.
Stable Signature is Unstable: Removing Image Watermark from Diffusion Models
May 12, 2024



Watermark has been widely deployed by industry to detect AI-generated images. A recent watermarking framework called \emph{Stable Signature} (proposed by Meta) roots watermark into the parameters of a diffusion model's decoder such that its generated images are inherently watermarked. Stable Signature makes it possible to watermark images generated by \emph{open-source} diffusion models and was claimed to be robust against removal attacks. In this work, we propose a new attack to remove the watermark from a diffusion model by fine-tuning it. Our results show that our attack can effectively remove the watermark from a diffusion model such that its generated images are non-watermarked, while maintaining the visual quality of the generated images. Our results highlight that Stable Signature is not as stable as previously thought.
Watermark-based Detection and Attribution of AI-Generated Content
Apr 05, 2024



Several companies--such as Google, Microsoft, and OpenAI--have deployed techniques to watermark AI-generated content to enable proactive detection. However, existing literature mainly focuses on user-agnostic detection. Attribution aims to further trace back the user of a generative-AI service who generated a given content detected as AI-generated. Despite its growing importance, attribution is largely unexplored. In this work, we aim to bridge this gap by providing the first systematic study on watermark-based, user-aware detection and attribution of AI-generated content. Specifically, we theoretically study the detection and attribution performance via rigorous probabilistic analysis. Moreover, we develop an efficient algorithm to select watermarks for the users to enhance attribution performance. Both our theoretical and empirical results show that watermark-based detection and attribution inherit the accuracy and (non-)robustness properties of the watermarking method.
A Transfer Attack to Image Watermarks
Mar 25, 2024



Watermark has been widely deployed by industry to detect AI-generated images. The robustness of such watermark-based detector against evasion attacks in the white-box and black-box settings is well understood in the literature. However, the robustness in the no-box setting is much less understood. In particular, multiple studies claimed that image watermark is robust in such setting. In this work, we propose a new transfer evasion attack to image watermark in the no-box setting. Our transfer attack adds a perturbation to a watermarked image to evade multiple surrogate watermarking models trained by the attacker itself, and the perturbed watermarked image also evades the target watermarking model. Our major contribution is to show that, both theoretically and empirically, watermark-based AI-generated image detector is not robust to evasion attacks even if the attacker does not have access to the watermarking model nor the detection API.
Evading Watermark based Detection of AI-Generated Content
May 05, 2023



A generative AI model -- such as DALL-E, Stable Diffusion, and ChatGPT -- can generate extremely realistic-looking content, posing growing challenges to the authenticity of information. To address the challenges, watermark has been leveraged to detect AI-generated content. Specifically, a watermark is embedded into an AI-generated content before it is released. A content is detected as AI-generated if a similar watermark can be decoded from it. In this work, we perform a systematic study on the robustness of such watermark-based AI-generated content detection. We focus on AI-generated images. Our work shows that an attacker can post-process an AI-generated watermarked image via adding a small, human-imperceptible perturbation to it, such that the post-processed AI-generated image evades detection while maintaining its visual quality. We demonstrate the effectiveness of our attack both theoretically and empirically. Moreover, to evade detection, our adversarial post-processing method adds much smaller perturbations to the AI-generated images and thus better maintain their visual quality than existing popular image post-processing methods such as JPEG compression, Gaussian blur, and Brightness/Contrast. Our work demonstrates the insufficiency of existing watermark-based detection of AI-generated content, highlighting the urgent needs of new detection methods.