 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen World Scene Graph Generation using Vision Language Models
Jun 09, 2025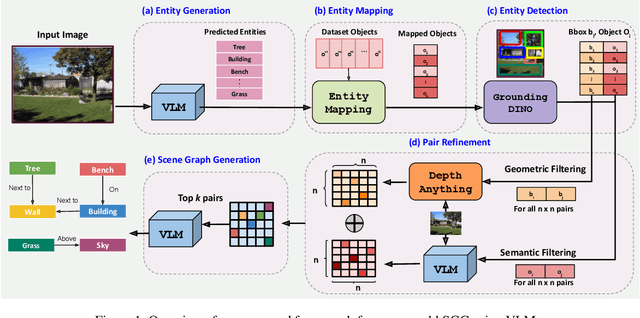
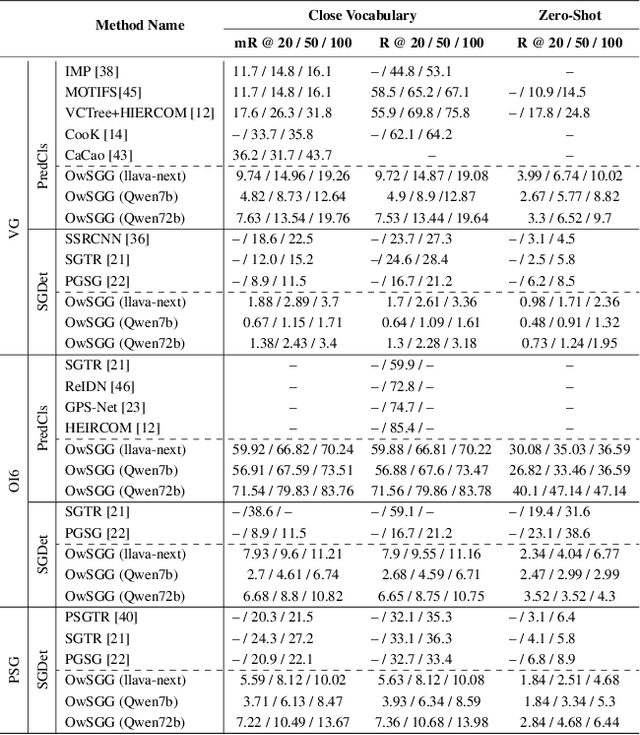
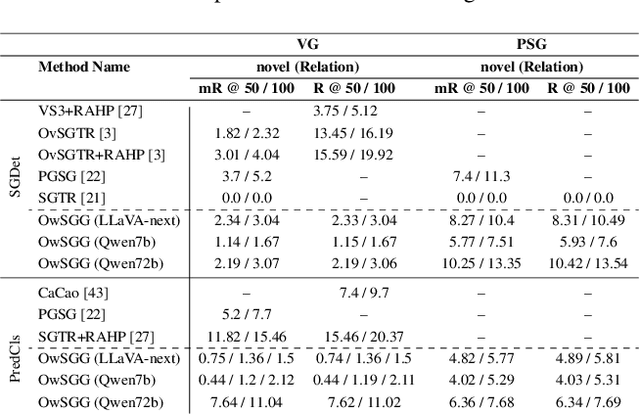
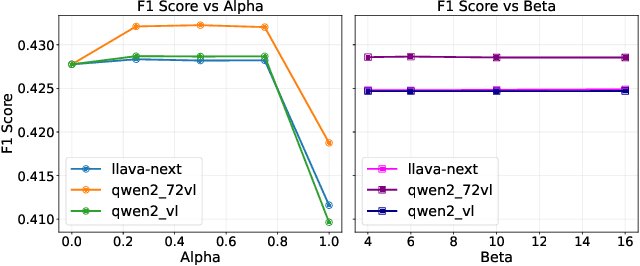
Scene-Graph Generation (SGG) seeks to recognize objects in an image and distill their salient pairwise relationships. Most methods depend on dataset-specific supervision to learn the variety of interactions, restricting their usefulness in open-world settings, involving novel objects and/or relations. Even methods that leverage large Vision Language Models (VLMs) typically require benchmark-specific fine-tuning. We introduce Open-World SGG, a training-free, efficient, model-agnostic framework that taps directly into the pretrained knowledge of VLMs to produce scene graphs with zero additional learning. Casting SGG as a zero-shot structured-reasoning problem, our method combines multimodal prompting, embedding alignment, and a lightweight pair-refinement strategy, enabling inference over unseen object vocabularies and relation sets. To assess this setting, we formalize an Open-World evaluation protocol that measures performance when no SGG-specific data have been observed either in terms of objects and relations. Experiments on Visual Genome, Open Images V6, and the Panoptic Scene Graph (PSG) dataset demonstrate the capacity of pretrained VLMs to perform relational understanding without task-level training.
AI-generated Image Detection: Passive or Watermark?
Nov 20, 2024


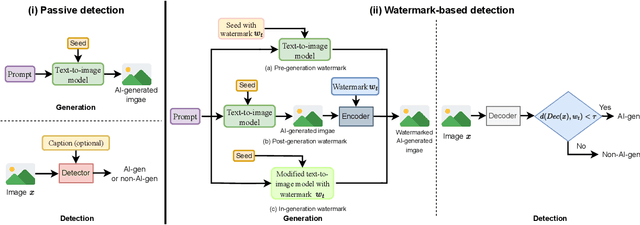
While text-to-image models offer numerous benefits, they also pose significant societal risks. Detecting AI-generated images is crucial for mitigating these risks. Detection methods can be broadly categorized into passive and watermark-based approaches: passive detectors rely on artifacts present in AI-generated images, whereas watermark-based detectors proactively embed watermarks into such images. A key question is which type of detector performs better in terms of effectiveness, robustness, and efficiency. However, the current literature lacks a comprehensive understanding of this issue. In this work, we aim to bridge that gap by developing ImageDetectBench, the first comprehensive benchmark to compare the effectiveness, robustness, and efficiency of passive and watermark-based detectors. Our benchmark includes four datasets, each containing a mix of AI-generated and non-AI-generated images. We evaluate five passive detectors and four watermark-based detectors against eight types of common perturbations and three types of adversarial perturbations. Our benchmark results reveal several interesting findings. For instance, watermark-based detectors consistently outperform passive detectors, both in the presence and absence of perturbations. Based on these insights, we provide recommendations for detecting AI-generated images, e.g., when both types of detectors are applicable, watermark-based detectors should be the preferred choice.
Hiding-in-Plain-Sight (HiPS) Attack on CLIP for Targetted Object Removal from Images
Oct 16, 2024
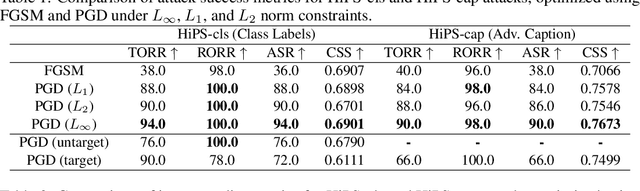


Machine learning models are known to be vulnerable to adversarial attacks, but traditional attacks have mostly focused on single-modalities. With the rise of large multi-modal models (LMMs) like CLIP, which combine vision and language capabilities, new vulnerabilities have emerged. However, prior work in multimodal targeted attacks aim to completely change the model's output to what the adversary wants. In many realistic scenarios, an adversary might seek to make only subtle modifications to the output, so that the changes go unnoticed by downstream models or even by humans. We introduce Hiding-in-Plain-Sight (HiPS) attacks, a novel class of adversarial attacks that subtly modifies model predictions by selectively concealing target object(s), as if the target object was absent from the scene. We propose two HiPS attack variants, HiPS-cls and HiPS-cap, and demonstrate their effectiveness in transferring to downstream image captioning models, such as CLIP-Cap, for targeted object removal from image captions.
A Unified Framework for Forward and Inverse Problems in Subsurface Imaging using Latent Space Translations
Oct 15, 2024In subsurface imaging, learning the mapping from velocity maps to seismic waveforms (forward problem) and waveforms to velocity (inverse problem) is important for several applications. While traditional techniques for solving forward and inverse problems are computationally prohibitive, there is a growing interest in leveraging recent advances in deep learning to learn the mapping between velocity maps and seismic waveform images directly from data. Despite the variety of architectures explored in previous works, several open questions still remain unanswered such as the effect of latent space sizes, the importance of manifold learning, the complexity of translation models, and the value of jointly solving forward and inverse problems. We propose a unified framework to systematically characterize prior research in this area termed the Generalized Forward-Inverse (GFI) framework, building on the assumption of manifolds and latent space translations. We show that GFI encompasses previous works in deep learning for subsurface imaging, which can be viewed as specific instantiations of GFI. We also propose two new model architectures within the framework of GFI: Latent U-Net and Invertible X-Net, leveraging the power of U-Nets for domain translation and the ability of IU-Nets to simultaneously learn forward and inverse translations, respectively. We show that our proposed models achieve state-of-the-art (SOTA) performance for forward and inverse problems on a wide range of synthetic datasets, and also investigate their zero-shot effectiveness on two real-world-like datasets.
What Do You See in Common? Learning Hierarchical Prototypes over Tree-of-Life to Discover Evolutionary Traits
Sep 03, 2024

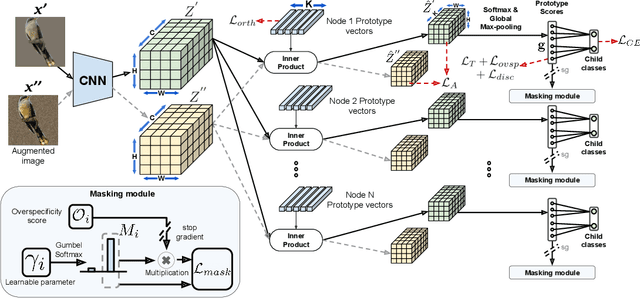

A grand challenge in biology is to discover evolutionary traits - features of organisms common to a group of species with a shared ancestor in the tree of life (also referred to as phylogenetic tree). With the growing availability of image repositories in biology, there is a tremendous opportunity to discover evolutionary traits directly from images in the form of a hierarchy of prototypes. However, current prototype-based methods are mostly designed to operate over a flat structure of classes and face several challenges in discovering hierarchical prototypes, including the issue of learning over-specific features at internal nodes. To overcome these challenges, we introduce the framework of Hierarchy aligned Commonality through Prototypical Networks (HComP-Net). We empirically show that HComP-Net learns prototypes that are accurate, semantically consistent, and generalizable to unseen species in comparison to baselines on birds, butterflies, and fishes datasets. The code and datasets are available at https://github.com/Imageomics/HComPNet.
VLM4Bio: A Benchmark Dataset to Evaluate Pretrained Vision-Language Models for Trait Discovery from Biological Images
Aug 28, 2024
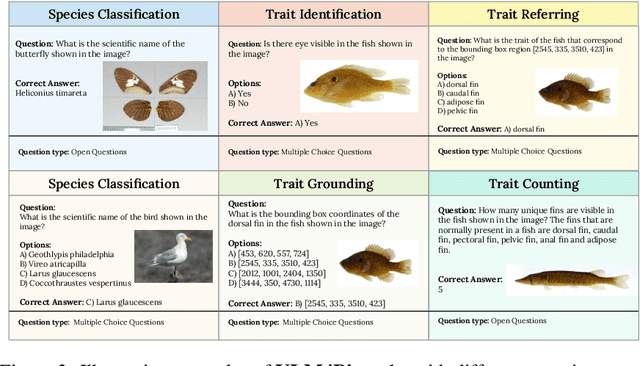


Images are increasingly becoming the currency for documenting biodiversity on the planet, providing novel opportunities for accelerating scientific discoveries in the field of organismal biology, especially with the advent of large vision-language models (VLMs). We ask if pre-trained VLMs can aid scientists in answering a range of biologically relevant questions without any additional fine-tuning. In this paper, we evaluate the effectiveness of 12 state-of-the-art (SOTA) VLMs in the field of organismal biology using a novel dataset, VLM4Bio, consisting of 469K question-answer pairs involving 30K images from three groups of organisms: fishes, birds, and butterflies, covering five biologically relevant tasks. We also explore the effects of applying prompting techniques and tests for reasoning hallucination on the performance of VLMs, shedding new light on the capabilities of current SOTA VLMs in answering biologically relevant questions using images. The code and datasets for running all the analyses reported in this paper can be found at https://github.com/sammarfy/VLM4Bio.
Hierarchical Conditioning of Diffusion Models Using Tree-of-Life for Studying Species Evolution
Jul 31, 2024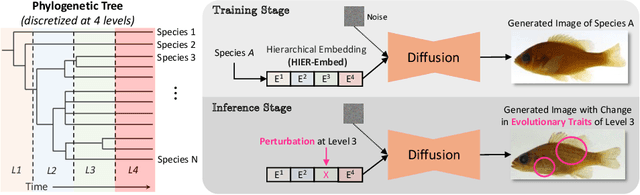
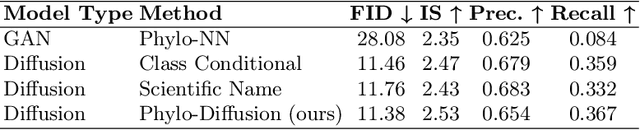
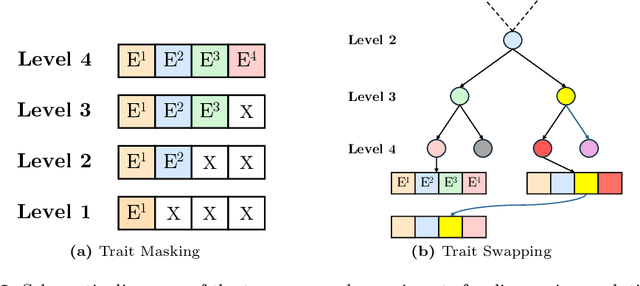

A central problem in biology is to understand how organisms evolve and adapt to their environment by acquiring variations in the observable characteristics or traits of species across the tree of life. With the growing availability of large-scale image repositories in biology and recent advances in generative modeling, there is an opportunity to accelerate the discovery of evolutionary traits automatically from images. Toward this goal, we introduce Phylo-Diffusion, a novel framework for conditioning diffusion models with phylogenetic knowledge represented in the form of HIERarchical Embeddings (HIER-Embeds). We also propose two new experiments for perturbing the embedding space of Phylo-Diffusion: trait masking and trait swapping, inspired by counterpart experiments of gene knockout and gene editing/swapping. Our work represents a novel methodological advance in generative modeling to structure the embedding space of diffusion models using tree-based knowledge. Our work also opens a new chapter of research in evolutionary biology by using generative models to visualize evolutionary changes directly from images. We empirically demonstrate the usefulness of Phylo-Diffusion in capturing meaningful trait variations for fishes and birds, revealing novel insights about the biological mechanisms of their evolution.
Fish-Vista: A Multi-Purpose Dataset for Understanding & Identification of Traits from Images
Jul 10, 2024



Fishes are integral to both ecological systems and economic sectors, and studying fish traits is crucial for understanding biodiversity patterns and macro-evolution trends. To enable the analysis of visual traits from fish images, we introduce the Fish-Visual Trait Analysis (Fish-Vista) dataset - a large, annotated collection of about 60K fish images spanning 1900 different species, supporting several challenging and biologically relevant tasks including species classification, trait identification, and trait segmentation. These images have been curated through a sophisticated data processing pipeline applied to a cumulative set of images obtained from various museum collections. Fish-Vista provides fine-grained labels of various visual traits present in each image. It also offers pixel-level annotations of 9 different traits for 2427 fish images, facilitating additional trait segmentation and localization tasks. The ultimate goal of Fish-Vista is to provide a clean, carefully curated, high-resolution dataset that can serve as a foundation for accelerating biological discoveries using advances in AI. Finally, we provide a comprehensive analysis of state-of-the-art deep learning techniques on Fish-Vista.
Learning the boundary-to-domain mapping using Lifting Product Fourier Neural Operators for partial differential equations
Jun 24, 2024Neural operators such as the Fourier Neural Operator (FNO) have been shown to provide resolution-independent deep learning models that can learn mappings between function spaces. For example, an initial condition can be mapped to the solution of a partial differential equation (PDE) at a future time-step using a neural operator. Despite the popularity of neural operators, their use to predict solution functions over a domain given only data over the boundary (such as a spatially varying Dirichlet boundary condition) remains unexplored. In this paper, we refer to such problems as boundary-to-domain problems; they have a wide range of applications in areas such as fluid mechanics, solid mechanics, heat transfer etc. We present a novel FNO-based architecture, named Lifting Product FNO (or LP-FNO) which can map arbitrary boundary functions defined on the lower-dimensional boundary to a solution in the entire domain. Specifically, two FNOs defined on the lower-dimensional boundary are lifted into the higher dimensional domain using our proposed lifting product layer. We demonstrate the efficacy and resolution independence of the proposed LP-FNO for the 2D Poisson equation.
MEMTRACK: A Deep Learning-Based Approach to Microrobot Tracking in Dense and Low-Contrast Environments
Oct 13, 2023



Tracking microrobots is challenging, considering their minute size and high speed. As the field progresses towards developing microrobots for biomedical applications and conducting mechanistic studies in physiologically relevant media (e.g., collagen), this challenge is exacerbated by the dense surrounding environments with feature size and shape comparable to microrobots. Herein, we report Motion Enhanced Multi-level Tracker (MEMTrack), a robust pipeline for detecting and tracking microrobots using synthetic motion features, deep learning-based object detection, and a modified Simple Online and Real-time Tracking (SORT) algorithm with interpolation for tracking. Our object detection approach combines different models based on the object's motion pattern. We trained and validated our model using bacterial micro-motors in collagen (tissue phantom) and tested it in collagen and aqueous media. We demonstrate that MEMTrack accurately tracks even the most challenging bacteria missed by skilled human annotators, achieving precision and recall of 77% and 48% in collagen and 94% and 35% in liquid media, respectively. Moreover, we show that MEMTrack can quantify average bacteria speed with no statistically significant difference from the laboriously-produced manual tracking data. MEMTrack represents a significant contribution to microrobot localization and tracking, and opens the potential for vision-based deep learning approaches to microrobot control in dense and low-contrast settings. All source code for training and testing MEMTrack and reproducing the results of the paper have been made publicly available https://github.com/sawhney-medha/MEMTrack.