 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioCLIP 2: Emergent Properties from Scaling Hierarchical Contrastive Learning
May 29, 2025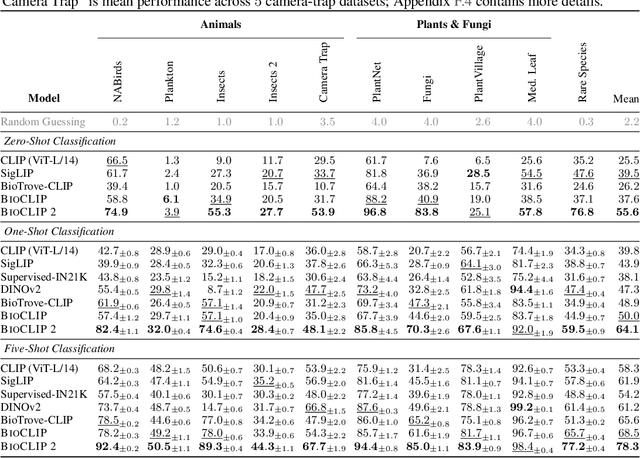
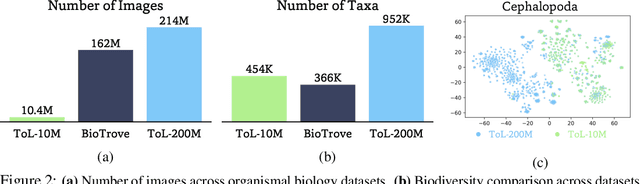
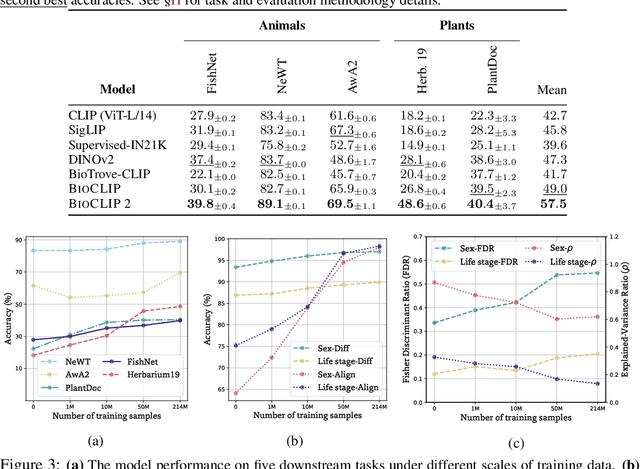
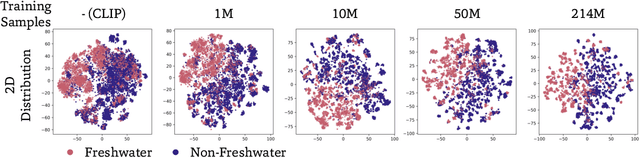
Foundation models trained at scale exhibit remarkable emergent behaviors, learning new capabilities beyond their initial training objectives. We find such emergent behaviors in biological vision models via large-scale contrastive vision-language training. To achieve this, we first curate TreeOfLife-200M, comprising 214 million images of living organisms, the largest and most diverse biological organism image dataset to date. We then train BioCLIP 2 on TreeOfLife-200M to distinguish different species. Despite the narrow training objective, BioCLIP 2 yields extraordinary accuracy when applied to various biological visual tasks such as habitat classification and trait prediction. We identify emergent properties in the learned embedding space of BioCLIP 2. At the inter-species level, the embedding distribution of different species aligns closely with functional and ecological meanings (e.g., beak sizes and habitats). At the intra-species level, instead of being diminished, the intra-species variations (e.g., life stages and sexes) are preserved and better separated in subspaces orthogonal to inter-species distinctions. We provide formal proof and analyses to explain why hierarchical supervision and contrastive objectives encourage these emergent properties. Crucially, our results reveal that these properties become increasingly significant with larger-scale training data, leading to a biologically meaningful embedding space.
What Do You See in Common? Learning Hierarchical Prototypes over Tree-of-Life to Discover Evolutionary Traits
Sep 03, 2024

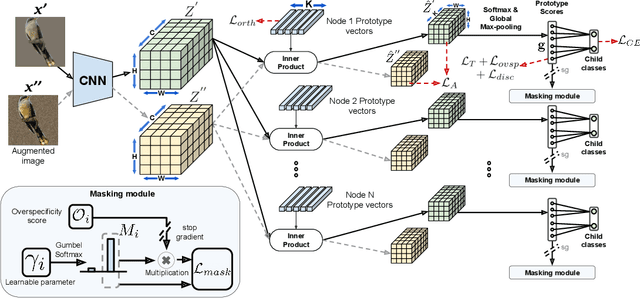

A grand challenge in biology is to discover evolutionary traits - features of organisms common to a group of species with a shared ancestor in the tree of life (also referred to as phylogenetic tree). With the growing availability of image repositories in biology, there is a tremendous opportunity to discover evolutionary traits directly from images in the form of a hierarchy of prototypes. However, current prototype-based methods are mostly designed to operate over a flat structure of classes and face several challenges in discovering hierarchical prototypes, including the issue of learning over-specific features at internal nodes. To overcome these challenges, we introduce the framework of Hierarchy aligned Commonality through Prototypical Networks (HComP-Net). We empirically show that HComP-Net learns prototypes that are accurate, semantically consistent, and generalizable to unseen species in comparison to baselines on birds, butterflies, and fishes datasets. The code and datasets are available at https://github.com/Imageomics/HComPNet.
Fish-Vista: A Multi-Purpose Dataset for Understanding & Identification of Traits from Images
Jul 10, 2024



Fishes are integral to both ecological systems and economic sectors, and studying fish traits is crucial for understanding biodiversity patterns and macro-evolution trends. To enable the analysis of visual traits from fish images, we introduce the Fish-Visual Trait Analysis (Fish-Vista) dataset - a large, annotated collection of about 60K fish images spanning 1900 different species, supporting several challenging and biologically relevant tasks including species classification, trait identification, and trait segmentation. These images have been curated through a sophisticated data processing pipeline applied to a cumulative set of images obtained from various museum collections. Fish-Vista provides fine-grained labels of various visual traits present in each image. It also offers pixel-level annotations of 9 different traits for 2427 fish images, facilitating additional trait segmentation and localization tasks. The ultimate goal of Fish-Vista is to provide a clean, carefully curated, high-resolution dataset that can serve as a foundation for accelerating biological discoveries using advances in AI. Finally, we provide a comprehensive analysis of state-of-the-art deep learning techniques on Fish-Vista.
BioCLIP: A Vision Foundation Model for the Tree of Life
Dec 04, 2023

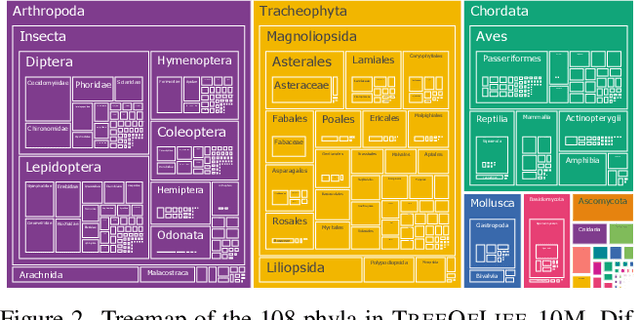

Images of the natural world, collected by a variety of cameras, from drones to individual phones, are increasingly abundant sources of biological information. There is an explosion of computational methods and tools, particularly computer vision, for extracting biologically relevant information from images for science and conservation. Yet most of these are bespoke approaches designed for a specific task and are not easily adaptable or extendable to new questions, contexts, and datasets. A vision model for general organismal biology questions on images is of timely need. To approach this, we curate and release TreeOfLife-10M, the largest and most diverse ML-ready dataset of biology images. We then develop BioCLIP, a foundation model for the tree of life, leveraging the unique properties of biology captured by TreeOfLife-10M, namely the abundance and variety of images of plants, animals, and fungi, together with the availability of rich structured biological knowledge. We rigorously benchmark our approach on diverse fine-grained biology classification tasks, and find that BioCLIP consistently and substantially outperforms existing baselines (by 17% to 20% absolute). Intrinsic evaluation reveals that BioCLIP has learned a hierarchical representation conforming to the tree of life, shedding light on its strong generalizability. Our code, models and data will be made available at https://github.com/Imageomics/bioclip.