 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame-Origin Policy for Agentic Browsers
Jun 12, 2026Agentic browsers integrate autonomous AI agents into web browsers, enabling users to accomplish web tasks through natural-language instructions. The same-origin policy (SOP) is a fundamental browser security mechanism that prevents unauthorized automated cross-origin data flows induced by scripts. However, whether SOP remains effective in agentic browsers is an open question that has not been systematically studied. In this work, we bridge this gap. We first observe that an agentic browser can itself serve as an automated channel for cross-origin data flows, potentially leading to SOP violations. To investigate this phenomenon, we construct SOPBench, a benchmark for evaluating SOP violations in agentic browsers. Our evaluation shows that existing agentic browsers frequently violate SOP, both in benign settings and under attacks. To address this problem, we propose SOPGuard, an SOP enforcement mechanism tailored to agentic browsers. We implement SOPGuard in BrowserOS, an open-source agentic browser. Extensive evaluations demonstrate that SOPGuard effectively enforces SOP while preserving utility and incurring only a small runtime overhead. Our code and data are available at https://github.com/wxl-lxw/BrowserOS-SOPGuard.
A Framework for Formalizing LLM Agent Security
Mar 19, 2026Security in LLM agents is inherently contextual. For example, the same action taken by an agent may represent legitimate behavior or a security violation depending on whose instruction led to the action, what objective is being pursued, and whether the action serves that objective. However, existing definitions of security attacks against LLM agents often fail to capture this contextual nature. As a result, defenses face a fundamental utility-security tradeoff: applying defenses uniformly across all contexts can lead to significant utility loss, while applying defenses in insufficient or inappropriate contexts can result in security vulnerabilities. In this work, we present a framework that systematizes existing attacks and defenses from the perspective of contextual security. To this end, we propose four security properties that capture contextual security for LLM agents: task alignment (pursuing authorized objectives), action alignment (individual actions serving those objectives), source authorization (executing commands from authenticated sources), and data isolation (ensuring information flows respect privilege boundaries). We further introduce a set of oracle functions that enable verification of whether these security properties are violated as an agent executes a user task. Using this framework, we reformalize existing attacks, such as indirect prompt injection, direct prompt injection, jailbreak, task drift, and memory poisoning, as violations of one or more security properties, thereby providing precise and contextual definitions of these attacks. Similarly, we reformalize defenses as mechanisms that strengthen oracle functions or perform security property checks. Finally, we discuss several important future research directions enabled by our framework.
Copyright Detective: A Forensic System to Evidence LLMs Flickering Copyright Leakage Risks
Feb 05, 2026We present Copyright Detective, the first interactive forensic system for detecting, analyzing, and visualizing potential copyright risks in LLM outputs. The system treats copyright infringement versus compliance as an evidence discovery process rather than a static classification task due to the complex nature of copyright law. It integrates multiple detection paradigms, including content recall testing, paraphrase-level similarity analysis, persuasive jailbreak probing, and unlearning verification, within a unified and extensible framework. Through interactive prompting, response collection, and iterative workflows, our system enables systematic auditing of verbatim memorization and paraphrase-level leakage, supporting responsible deployment and transparent evaluation of LLM copyright risks even with black-box access.
WebSentinel: Detecting and Localizing Prompt Injection Attacks for Web Agents
Feb 03, 2026Prompt injection attacks manipulate webpage content to cause web agents to execute attacker-specified tasks instead of the user's intended ones. Existing methods for detecting and localizing such attacks achieve limited effectiveness, as their underlying assumptions often do not hold in the web-agent setting. In this work, we propose WebSentinel, a two-step approach for detecting and localizing prompt injection attacks in webpages. Given a webpage, Step I extracts \emph{segments of interest} that may be contaminated, and Step II evaluates each segment by checking its consistency with the webpage content as context. We show that WebSentinel is highly effective, substantially outperforming baseline methods across multiple datasets of both contaminated and clean webpages that we collected. Our code is available at: https://github.com/wxl-lxw/WebSentinel.
Mitigating Watermark Stealing Attacks in Generative Models via Multi-Key Watermarking
Jul 10, 2025Watermarking offers a promising solution for GenAI providers to establish the provenance of their generated content. A watermark is a hidden signal embedded in the generated content, whose presence can later be verified using a secret watermarking key. A threat to GenAI providers are \emph{watermark stealing} attacks, where users forge a watermark into content that was \emph{not} generated by the provider's models without access to the secret key, e.g., to falsely accuse the provider. Stealing attacks collect \emph{harmless} watermarked samples from the provider's model and aim to maximize the expected success rate of generating \emph{harmful} watermarked samples. Our work focuses on mitigating stealing attacks while treating the underlying watermark as a black-box. Our contributions are: (i) Proposing a multi-key extension to mitigate stealing attacks that can be applied post-hoc to any watermarking method across any modality. (ii) We provide theoretical guarantees and demonstrate empirically that our method makes forging substantially less effective across multiple datasets, and (iii) we formally define the threat of watermark forging as the task of generating harmful, watermarked content and model this threat via security games.
GraphRAG under Fire
Jan 23, 2025GraphRAG advances retrieval-augmented generation (RAG) by structuring external knowledge as multi-scale knowledge graphs, enabling language models to integrate both broad context and granular details in their reasoning. While GraphRAG has demonstrated success across domains, its security implications remain largely unexplored. To bridge this gap, this work examines GraphRAG's vulnerability to poisoning attacks, uncovering an intriguing security paradox: compared to conventional RAG, GraphRAG's graph-based indexing and retrieval enhance resilience against simple poisoning attacks; meanwhile, the same features also create new attack surfaces. We present GRAGPoison, a novel attack that exploits shared relations in the knowledge graph to craft poisoning text capable of compromising multiple queries simultaneously. GRAGPoison employs three key strategies: i) relation injection to introduce false knowledge, ii) relation enhancement to amplify poisoning influence, and iii) narrative generation to embed malicious content within coherent text. Empirical evaluation across diverse datasets and models shows that GRAGPoison substantially outperforms existing attacks in terms of effectiveness (up to 98% success rate) and scalability (using less than 68% poisoning text). We also explore potential defensive measures and their limitations, identifying promising directions for future research.
GRID: Protecting Training Graph from Link Stealing Attacks on GNN Models
Jan 19, 2025



Graph neural networks (GNNs) have exhibited superior performance in various classification tasks on graph-structured data. However, they encounter the potential vulnerability from the link stealing attacks, which can infer the presence of a link between two nodes via measuring the similarity of its incident nodes' prediction vectors produced by a GNN model. Such attacks pose severe security and privacy threats to the training graph used in GNN models. In this work, we propose a novel solution, called Graph Link Disguise (GRID), to defend against link stealing attacks with the formal guarantee of GNN model utility for retaining prediction accuracy. The key idea of GRID is to add carefully crafted noises to the nodes' prediction vectors for disguising adjacent nodes as n-hop indirect neighboring nodes. We take into account the graph topology and select only a subset of nodes (called core nodes) covering all links for adding noises, which can avert the noises offset and have the further advantages of reducing both the distortion loss and the computation cost. Our crafted noises can ensure 1) the noisy prediction vectors of any two adjacent nodes have their similarity level like that of two non-adjacent nodes and 2) the model prediction is unchanged to ensure zero utility loss. Extensive experiments on five datasets are conducted to show the effectiveness of our proposed GRID solution against different representative link-stealing attacks under transductive settings and inductive settings respectively, as well as two influence-based attacks. Meanwhile, it achieves a much better privacy-utility trade-off than existing methods when extended to GNNs.
AI-generated Image Detection: Passive or Watermark?
Nov 20, 2024


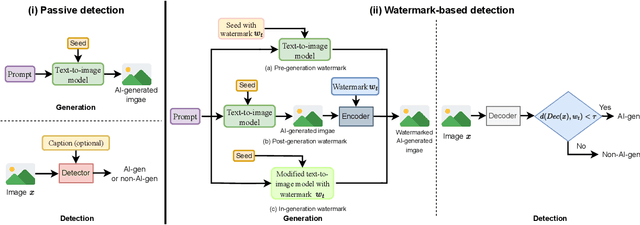
While text-to-image models offer numerous benefits, they also pose significant societal risks. Detecting AI-generated images is crucial for mitigating these risks. Detection methods can be broadly categorized into passive and watermark-based approaches: passive detectors rely on artifacts present in AI-generated images, whereas watermark-based detectors proactively embed watermarks into such images. A key question is which type of detector performs better in terms of effectiveness, robustness, and efficiency. However, the current literature lacks a comprehensive understanding of this issue. In this work, we aim to bridge that gap by developing ImageDetectBench, the first comprehensive benchmark to compare the effectiveness, robustness, and efficiency of passive and watermark-based detectors. Our benchmark includes four datasets, each containing a mix of AI-generated and non-AI-generated images. We evaluate five passive detectors and four watermark-based detectors against eight types of common perturbations and three types of adversarial perturbations. Our benchmark results reveal several interesting findings. For instance, watermark-based detectors consistently outperform passive detectors, both in the presence and absence of perturbations. Based on these insights, we provide recommendations for detecting AI-generated images, e.g., when both types of detectors are applicable, watermark-based detectors should be the preferred choice.
Byzantine-Robust Decentralized Federated Learning
Jun 18, 2024



Federated learning (FL) enables multiple clients to collaboratively train machine learning models without revealing their private training data. In conventional FL, the system follows the server-assisted architecture (server-assisted FL), where the training process is coordinated by a central server. However, the server-assisted FL framework suffers from poor scalability due to a communication bottleneck at the server, and trust dependency issues. To address challenges, decentralized federated learning (DFL) architecture has been proposed to allow clients to train models collaboratively in a serverless and peer-to-peer manner. However, due to its fully decentralized nature, DFL is highly vulnerable to poisoning attacks, where malicious clients could manipulate the system by sending carefully-crafted local models to their neighboring clients. To date, only a limited number of Byzantine-robust DFL methods have been proposed, most of which are either communication-inefficient or remain vulnerable to advanced poisoning attacks. In this paper, we propose a new algorithm called BALANCE (Byzantine-robust averaging through local similarity in decentralization) to defend against poisoning attacks in DFL. In BALANCE, each client leverages its own local model as a similarity reference to determine if the received model is malicious or benign. We establish the theoretical convergence guarantee for BALANCE under poisoning attacks in both strongly convex and non-convex settings. Furthermore, the convergence rate of BALANCE under poisoning attacks matches those of the state-of-the-art counterparts in Byzantine-free settings. Extensive experiments also demonstrate that BALANCE outperforms existing DFL methods and effectively defends against poisoning attacks.
PLeak: Prompt Leaking Attacks against Large Language Model Applications
May 14, 2024

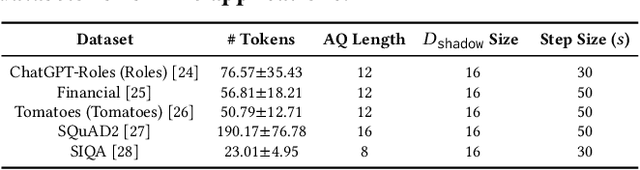
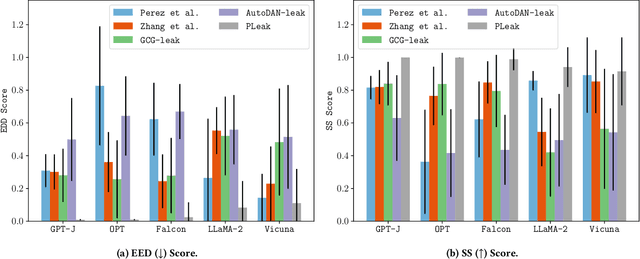
Large Language Models (LLMs) enable a new ecosystem with many downstream applications, called LLM applications, with different natural language processing tasks. The functionality and performance of an LLM application highly depend on its system prompt, which instructs the backend LLM on what task to perform. Therefore, an LLM application developer often keeps a system prompt confidential to protect its intellectual property. As a result, a natural attack, called prompt leaking, is to steal the system prompt from an LLM application, which compromises the developer's intellectual property. Existing prompt leaking attacks primarily rely on manually crafted queries, and thus achieve limited effectiveness. In this paper, we design a novel, closed-box prompt leaking attack framework, called PLeak, to optimize an adversarial query such that when the attacker sends it to a target LLM application, its response reveals its own system prompt. We formulate finding such an adversarial query as an optimization problem and solve it with a gradient-based method approximately. Our key idea is to break down the optimization goal by optimizing adversary queries for system prompts incrementally, i.e., starting from the first few tokens of each system prompt step by step until the entire length of the system prompt. We evaluate PLeak in both offline settings and for real-world LLM applications, e.g., those on Poe, a popular platform hosting such applications. Our results show that PLeak can effectively leak system prompts and significantly outperforms not only baselines that manually curate queries but also baselines with optimized queries that are modified and adapted from existing jailbreaking attacks. We responsibly reported the issues to Poe and are still waiting for their response. Our implementation is available at this repository: https://github.com/BHui97/PLeak.