 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLeak: Prompt Leaking Attacks against Large Language Model Applications
Paper and Code


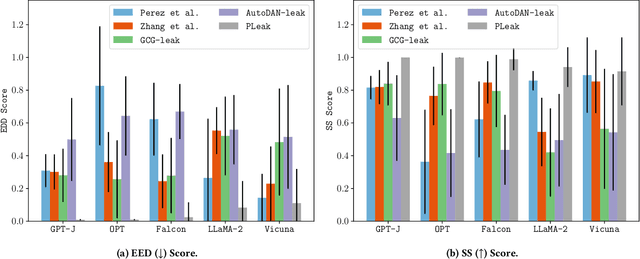
Large Language Models (LLMs) enable a new ecosystem with many downstream applications, called LLM applications, with different natural language processing tasks. The functionality and performance of an LLM application highly depend on its system prompt, which instructs the backend LLM on what task to perform. Therefore, an LLM application developer often keeps a system prompt confidential to protect its intellectual property. As a result, a natural attack, called prompt leaking, is to steal the system prompt from an LLM application, which compromises the developer's intellectual property. Existing prompt leaking attacks primarily rely on manually crafted queries, and thus achieve limited effectiveness. In this paper, we design a novel, closed-box prompt leaking attack framework, called PLeak, to optimize an adversarial query such that when the attacker sends it to a target LLM application, its response reveals its own system prompt. We formulate finding such an adversarial query as an optimization problem and solve it with a gradient-based method approximately. Our key idea is to break down the optimization goal by optimizing adversary queries for system prompts incrementally, i.e., starting from the first few tokens of each system prompt step by step until the entire length of the system prompt. We evaluate PLeak in both offline settings and for real-world LLM applications, e.g., those on Poe, a popular platform hosting such applications. Our results show that PLeak can effectively leak system prompts and significantly outperforms not only baselines that manually curate queries but also baselines with optimized queries that are modified and adapted from existing jailbreaking attacks. We responsibly reported the issues to Poe and are still waiting for their response. Our implementation is available at this repository: https://github.com/BHui97/PLeak.