 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLA: A Choice Leakage Attack Framework to Expose Privacy Risks in Subset Training
Apr 14, 2026Training models on a carefully chosen portion of data rather than the full dataset is now a standard preprocess for modern ML. From vision coreset selection to large-scale filtering in language models, it enables scalability with minimal utility loss. A common intuition is that training on fewer samples should also reduce privacy risks. In this paper, we challenge this assumption. We show that subset training is not privacy free: the very choices of which data are included or excluded can introduce new privacy surface and leak more sensitive information. Such information can be captured by adversaries either through side-channel metadata from the subset selection process or via the outputs of the target model. To systematically study this phenomenon, we propose CoLA (Choice Leakage Attack), a unified framework for analyzing privacy leakage in subset selection. In CoLA, depending on the adversary's knowledge of the side-channel information, we define two practical attack scenarios: Subset-aware Side-channel Attacks and Black-box Attacks. Under both scenarios, we investigate two privacy surfaces unique to subset training: (1) Training-membership MIA (TM-MIA), which concerns only the privacy of training data membership, and (2) Selection-participation MIA (SP-MIA), which concerns the privacy of all samples that participated in the subset selection process. Notably, SP-MIA enlarges the notion of membership from model training to the entire data-model supply chain. Experiments on vision and language models show that existing threat models underestimate subset-training privacy risks: the expanded privacy surface leaks both training and selection membership, extending risks from individual models to the broader ML ecosystem.
Beyond Crash: Hijacking Your Autonomous Vehicle for Fun and Profit
Feb 06, 2026Autonomous Vehicles (AVs), especially vision-based AVs, are rapidly being deployed without human operators. As AVs operate in safety-critical environments, understanding their robustness in an adversarial environment is an important research problem. Prior physical adversarial attacks on vision-based autonomous vehicles predominantly target immediate safety failures (e.g., a crash, a traffic-rule violation, or a transient lane departure) by inducing a short-lived perception or control error. This paper shows a qualitatively different risk: a long-horizon route integrity compromise, where an attacker gradually steers a victim AV away from its intended route and into an attacker-chosen destination while the victim continues to drive "normally." This will not pose a danger to the victim vehicle itself, but also to potential passengers sitting inside the vehicle. In this paper, we design and implement the first adversarial framework, called JackZebra, that performs route-level hijacking of a vision-based end-to-end driving stack using a physically plausible attacker vehicle with a reconfigurable display mounted on the rear. The central challenge is temporal persistence: adversarial influence must remain effective in changing viewpoints, lighting, weather, traffic, and the victim's continual replanning -- without triggering conspicuous failures. Our key insight is to treat route hijacking as a closed-loop control problem and to convert adversarial patches into steering primitives that can be selected online via an interactive adjustment loop. Our adversarial patches are also carefully designed against worst-case background and sensor variations so that the adversarial impacts on the victim. Our evaluation shows that JackZebra can successfully hijack victim vehicles to deviate from original routes and stop at adversarial destinations with a high success rate.
A Robust Certified Machine Unlearning Method Under Distribution Shift
Jan 11, 2026The Newton method has been widely adopted to achieve certified unlearning. A critical assumption in existing approaches is that the data requested for unlearning are selected i.i.d.(independent and identically distributed). However,the problem of certified unlearning under non-i.i.d. deletions remains largely unexplored. In practice, unlearning requests are inherently biased, leading to non-i.i.d. deletions and causing distribution shifts between the original and retained datasets. In this paper, we show that certified unlearning with the Newton method becomes inefficient and ineffective under non-i.i.d. unlearning sets. We then propose a better certified unlearning approach by performing a distribution-aware certified unlearning framework based on iterative Newton updates constrained by a trust region. Our method provides a closer approximation to the retrained model and yields a tighter pre-run bound on the gradient residual, thereby ensuring efficient (epsilon, delta)-certified unlearning. To demonstrate its practical effectiveness under distribution shift, we also conduct extensive experiments across multiple evaluation metrics, providing a comprehensive assessment of our approach.
Towards Lifecycle Unlearning Commitment Management: Measuring Sample-level Unlearning Completeness
Jun 06, 2025Growing concerns over data privacy and security highlight the importance of machine unlearning--removing specific data influences from trained models without full retraining. Techniques like Membership Inference Attacks (MIAs) are widely used to externally assess successful unlearning. However, existing methods face two key limitations: (1) maximizing MIA effectiveness (e.g., via online attacks) requires prohibitive computational resources, often exceeding retraining costs; (2) MIAs, designed for binary inclusion tests, struggle to capture granular changes in approximate unlearning. To address these challenges, we propose the Interpolated Approximate Measurement (IAM), a framework natively designed for unlearning inference. IAM quantifies sample-level unlearning completeness by interpolating the model's generalization-fitting behavior gap on queried samples. IAM achieves strong performance in binary inclusion tests for exact unlearning and high correlation for approximate unlearning--scalable to LLMs using just one pre-trained shadow model. We theoretically analyze how IAM's scoring mechanism maintains performance efficiently. We then apply IAM to recent approximate unlearning algorithms, revealing general risks of both over-unlearning and under-unlearning, underscoring the need for stronger safeguards in approximate unlearning systems. The code is available at https://github.com/Happy2Git/Unlearning_Inference_IAM.
Mirror Mirror on the Wall, Have I Forgotten it All? A New Framework for Evaluating Machine Unlearning
May 13, 2025Machine unlearning methods take a model trained on a dataset and a forget set, then attempt to produce a model as if it had only been trained on the examples not in the forget set. We empirically show that an adversary is able to distinguish between a mirror model (a control model produced by retraining without the data to forget) and a model produced by an unlearning method across representative unlearning methods from the literature. We build distinguishing algorithms based on evaluation scores in the literature (i.e. membership inference scores) and Kullback-Leibler divergence. We propose a strong formal definition for machine unlearning called computational unlearning. Computational unlearning is defined as the inability for an adversary to distinguish between a mirror model and a model produced by an unlearning method. If the adversary cannot guess better than random (except with negligible probability), then we say that an unlearning method achieves computational unlearning. Our computational unlearning definition provides theoretical structure to prove unlearning feasibility results. For example, our computational unlearning definition immediately implies that there are no deterministic computational unlearning methods for entropic learning algorithms. We also explore the relationship between differential privacy (DP)-based unlearning methods and computational unlearning, showing that DP-based approaches can satisfy computational unlearning at the cost of an extreme utility collapse. These results demonstrate that current methodology in the literature fundamentally falls short of achieving computational unlearning. We conclude by identifying several open questions for future work.
Jailbreaking Safeguarded Text-to-Image Models via Large Language Models
Mar 03, 2025



Text-to-Image models may generate harmful content, such as pornographic images, particularly when unsafe prompts are submitted. To address this issue, safety filters are often added on top of text-to-image models, or the models themselves are aligned to reduce harmful outputs. However, these defenses remain vulnerable when an attacker strategically designs adversarial prompts to bypass these safety guardrails. In this work, we propose PromptTune, a method to jailbreak text-to-image models with safety guardrails using a fine-tuned large language model. Unlike other query-based jailbreak attacks that require repeated queries to the target model, our attack generates adversarial prompts efficiently after fine-tuning our AttackLLM. We evaluate our method on three datasets of unsafe prompts and against five safety guardrails. Our results demonstrate that our approach effectively bypasses safety guardrails, outperforms existing no-box attacks, and also facilitates other query-based attacks.
Data Lineage Inference: Uncovering Privacy Vulnerabilities of Dataset Pruning
Nov 24, 2024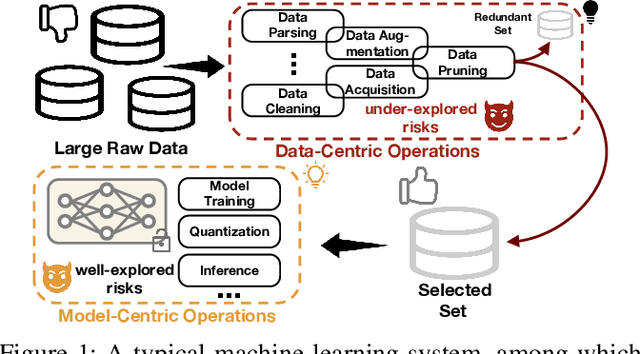
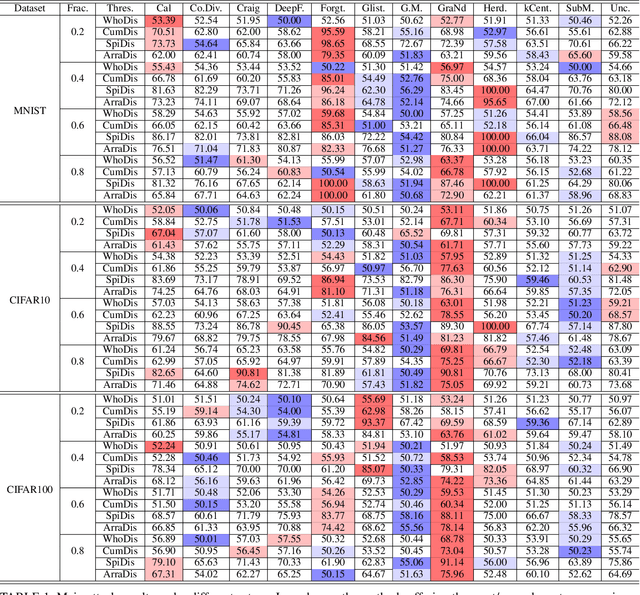
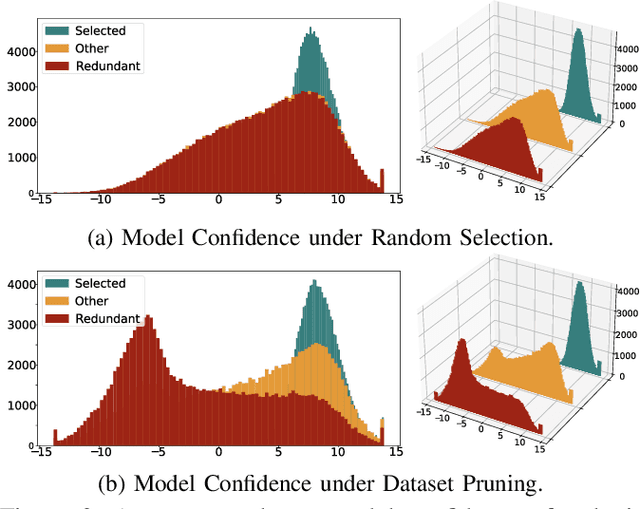
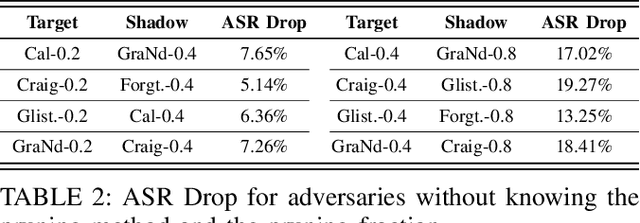
In this work, we systematically explore the data privacy issues of dataset pruning in machine learning systems. Our findings reveal, for the first time, that even if data in the redundant set is solely used before model training, its pruning-phase membership status can still be detected through attacks. Since this is a fully upstream process before model training, traditional model output-based privacy inference methods are completely unsuitable. To address this, we introduce a new task called Data-Centric Membership Inference and propose the first ever data-centric privacy inference paradigm named Data Lineage Inference (DaLI). Under this paradigm, four threshold-based attacks are proposed, named WhoDis, CumDis, ArraDis and SpiDis. We show that even without access to downstream models, adversaries can accurately identify the redundant set with only limited prior knowledge. Furthermore, we find that different pruning methods involve varying levels of privacy leakage, and even the same pruning method can present different privacy risks at different pruning fractions. We conducted an in-depth analysis of these phenomena and introduced a metric called the Brimming score to offer guidance for selecting pruning methods with privacy protection in mind.
Pseudo-Probability Unlearning: Towards Efficient and Privacy-Preserving Machine Unlearning
Nov 04, 2024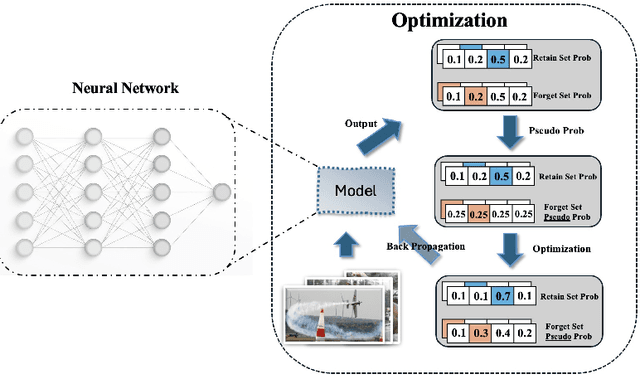
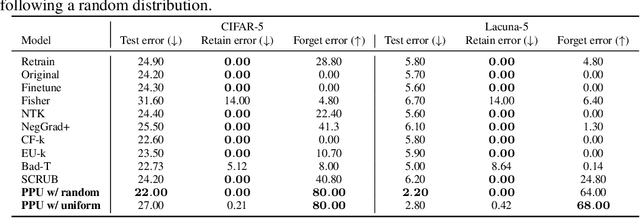
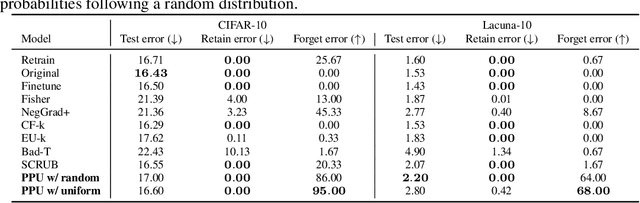
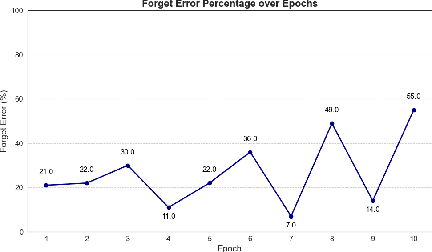
Machine unlearning--enabling a trained model to forget specific data--is crucial for addressing biased data and adhering to privacy regulations like the General Data Protection Regulation (GDPR)'s "right to be forgotten". Recent works have paid little attention to privacy concerns, leaving the data intended for forgetting vulnerable to membership inference attacks. Moreover, they often come with high computational overhead. In this work, we propose Pseudo-Probability Unlearning (PPU), a novel method that enables models to forget data efficiently and in a privacy-preserving manner. Our method replaces the final-layer output probabilities of the neural network with pseudo-probabilities for the data to be forgotten. These pseudo-probabilities follow either a uniform distribution or align with the model's overall distribution, enhancing privacy and reducing risk of membership inference attacks. Our optimization strategy further refines the predictive probability distributions and updates the model's weights accordingly, ensuring effective forgetting with minimal impact on the model's overall performance. Through comprehensive experiments on multiple benchmarks, our method achieves over 20% improvements in forgetting error compared to the state-of-the-art. Additionally, our method enhances privacy by preventing the forgotten set from being inferred to around random guesses.
RIPPLECOT: Amplifying Ripple Effect of Knowledge Editing in Language Models via Chain-of-Thought In-Context Learning
Oct 04, 2024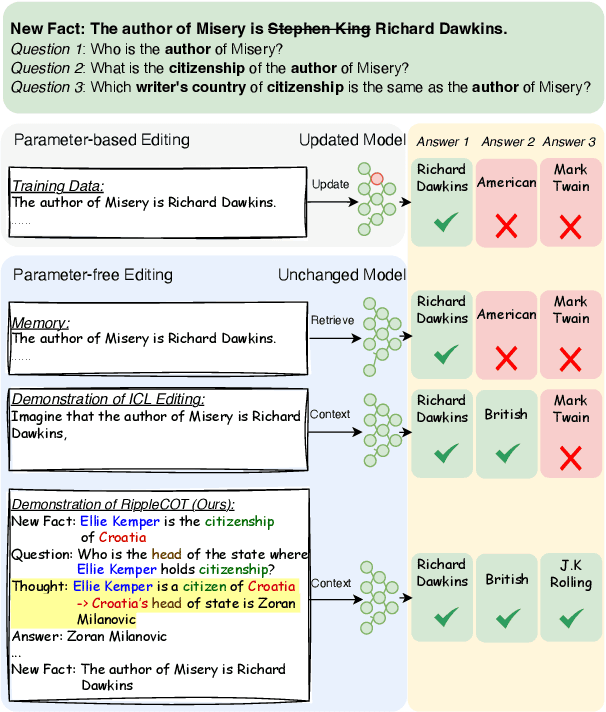
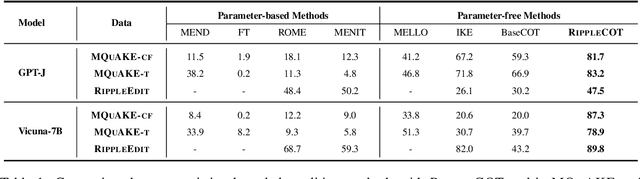
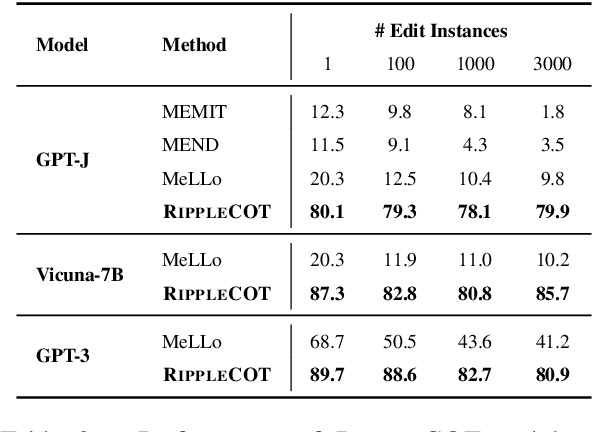
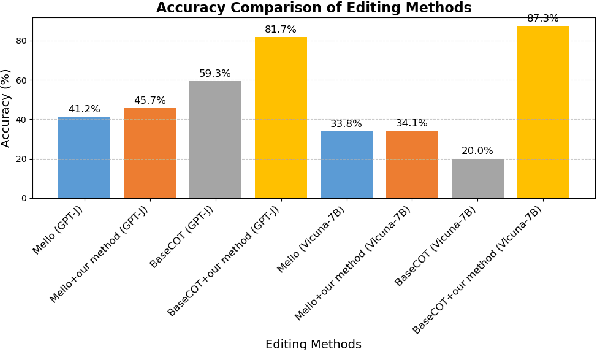
The ripple effect poses a significant challenge in knowledge editing for large language models. Namely, when a single fact is edited, the model struggles to accurately update the related facts in a sequence, which is evaluated by multi-hop questions linked to a chain of related facts. Recent strategies have moved away from traditional parameter updates to more flexible, less computation-intensive methods, proven to be more effective in addressing the ripple effect. In-context learning (ICL) editing uses a simple demonstration `Imagine that + new fact` to guide LLMs, but struggles with complex multi-hop questions as the new fact alone fails to specify the chain of facts involved in such scenarios. Besides, memory-based editing maintains additional storage for all edits and related facts, requiring continuous updates to stay effective. As a result of these design limitations, the challenge remains, with the highest accuracy being only 33.8% on the MQuAKE-cf benchmarks for Vicuna-7B. To address this, we propose RippleCOT, a novel ICL editing approach integrating Chain-of-Thought (COT) reasoning. RippleCOT structures demonstrations as `newfact, question, thought, answer`, incorporating a thought component to identify and decompose the multi-hop logic within questions. This approach effectively guides the model through complex multi-hop questions with chains of related facts. Comprehensive experiments demonstrate that RippleCOT significantly outperforms the state-of-the-art on the ripple effect, achieving accuracy gains ranging from 7.8% to 87.1%.
Follow the Rules: Reasoning for Video Anomaly Detection with Large Language Models
Jul 14, 2024Video Anomaly Detection (VAD) is crucial for applications such as security surveillance and autonomous driving. However, existing VAD methods provide little rationale behind detection, hindering public trust in real-world deployments. In this paper, we approach VAD with a reasoning framework. Although Large Language Models (LLMs) have shown revolutionary reasoning ability, we find that their direct use falls short of VAD. Specifically, the implicit knowledge pre-trained in LLMs focuses on general context and thus may not apply to every specific real-world VAD scenario, leading to inflexibility and inaccuracy. To address this, we propose AnomalyRuler, a novel rule-based reasoning framework for VAD with LLMs. AnomalyRuler comprises two main stages: induction and deduction. In the induction stage, the LLM is fed with few-shot normal reference samples and then summarizes these normal patterns to induce a set of rules for detecting anomalies. The deduction stage follows the induced rules to spot anomalous frames in test videos. Additionally, we design rule aggregation, perception smoothing, and robust reasoning strategies to further enhance AnomalyRuler's robustness. AnomalyRuler is the first reasoning approach for the one-class VAD task, which requires only few-normal-shot prompting without the need for full-shot training, thereby enabling fast adaption to various VAD scenarios. Comprehensive experiments across four VAD benchmarks demonstrate AnomalyRuler's state-of-the-art detection performance and reasoning ability.