 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREACT-LLM: A Benchmark for Evaluating LLM Integration with Causal Features in Clinical Prognostic Tasks
Nov 13, 2025Large Language Models (LLMs) and causal learning each hold strong potential for clinical decision making (CDM). However, their synergy remains poorly understood, largely due to the lack of systematic benchmarks evaluating their integration in clinical risk prediction. In real-world healthcare, identifying features with causal influence on outcomes is crucial for actionable and trustworthy predictions. While recent work highlights LLMs' emerging causal reasoning abilities, there lacks comprehensive benchmarks to assess their causal learning and performance informed by causal features in clinical risk prediction. To address this, we introduce REACT-LLM, a benchmark designed to evaluate whether combining LLMs with causal features can enhance clinical prognostic performance and potentially outperform traditional machine learning (ML) methods. Unlike existing LLM-clinical benchmarks that often focus on a limited set of outcomes, REACT-LLM evaluates 7 clinical outcomes across 2 real-world datasets, comparing 15 prominent LLMs, 6 traditional ML models, and 3 causal discovery (CD) algorithms. Our findings indicate that while LLMs perform reasonably in clinical prognostics, they have not yet outperformed traditional ML models. Integrating causal features derived from CD algorithms into LLMs offers limited performance gains, primarily due to the strict assumptions of many CD methods, which are often violated in complex clinical data. While the direct integration yields limited improvement, our benchmark reveals a more promising synergy.
AsFT: Anchoring Safety During LLM Fine-Tuning Within Narrow Safety Basin
Jun 11, 2025



Large language models (LLMs) are vulnerable to safety risks during fine-tuning, where small amounts of malicious or harmless data can compromise safeguards. In this paper, building on the concept of alignment direction -- defined by the weight difference between aligned and unaligned models -- we observe that perturbations along this direction preserve model safety. In contrast, perturbations along directions orthogonal to this alignment are strongly linked to harmful direction perturbations, rapidly degrading safety and framing the parameter space as a narrow safety basin. Based on this insight, we propose a methodology for safety fine-tuning called AsFT (Anchoring Safety in Fine-Tuning), which integrates a regularization term into the training objective. This term uses the alignment direction as an anchor to suppress updates in harmful directions, ensuring that fine-tuning is constrained within the narrow safety basin. Extensive experiments on multiple datasets show that AsFT outperforms Safe LoRA, reducing harmful behavior by 7.60 percent, improving model performance by 3.44 percent, and maintaining robust performance across various experimental settings. Code is available at https://github.com/PKU-YuanGroup/AsFT
UPME: An Unsupervised Peer Review Framework for Multimodal Large Language Model Evaluation
Mar 19, 2025Multimodal Large Language Models (MLLMs) have emerged to tackle the challenges of Visual Question Answering (VQA), sparking a new research focus on conducting objective evaluations of these models. Existing evaluation methods face limitations due to the significant human workload required to design Q&A pairs for visual images, which inherently restricts the scale and scope of evaluations. Although automated MLLM-as-judge approaches attempt to reduce the human workload through automatic evaluations, they often introduce biases. To address these problems, we propose an Unsupervised Peer review MLLM Evaluation framework. It utilizes only image data, allowing models to automatically generate questions and conduct peer review assessments of answers from other models, effectively alleviating the reliance on human workload. Additionally, we introduce the vision-language scoring system to mitigate the bias issues, which focuses on three aspects: (i) response correctness; (ii) visual understanding and reasoning; and (iii) image-text correlation. Experimental results demonstrate that UPME achieves a Pearson correlation of 0.944 with human evaluations on the MMstar dataset and 0.814 on the ScienceQA dataset, indicating that our framework closely aligns with human-designed benchmarks and inherent human preferences.
Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge
Oct 03, 2024



LLM-as-a-Judge has been widely utilized as an evaluation method in various benchmarks and served as supervised rewards in model training. However, despite their excellence in many domains, potential issues are under-explored, undermining their reliability and the scope of their utility. Therefore, we identify 12 key potential biases and propose a new automated bias quantification framework-CALM-which systematically quantifies and analyzes each type of bias in LLM-as-a-Judge by using automated and principle-guided modification. Our experiments cover multiple popular language models, and the results indicate that while advanced models have achieved commendable overall performance, significant biases persist in certain specific tasks. Empirical results suggest that there remains room for improvement in the reliability of LLM-as-a-Judge. Moreover, we also discuss the explicit and implicit influence of these biases and give some suggestions for the reliable application of LLM-as-a-Judge. Our work highlights the need for stakeholders to address these issues and remind users to exercise caution in LLM-as-a-Judge applications.
UniGen: A Unified Framework for Textual Dataset Generation Using Large Language Models
Jun 27, 2024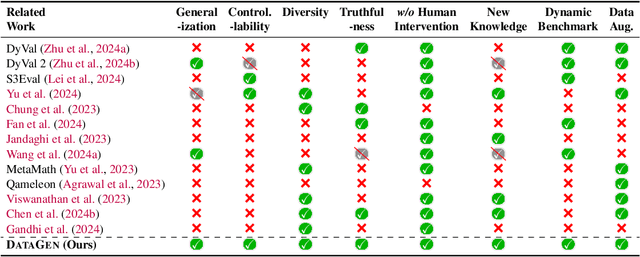
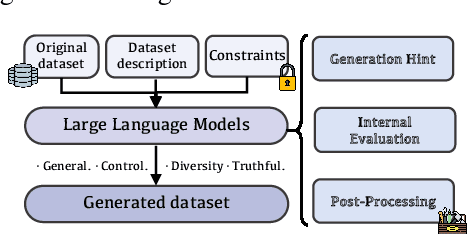
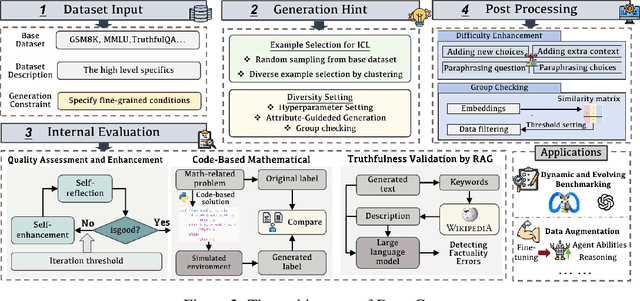

Large Language Models (LLMs) such as GPT-4 and Llama3 have significantly impacted various fields by enabling high-quality synthetic data generation and reducing dependence on expensive human-generated datasets. Despite this, challenges remain in the areas of generalization, controllability, diversity, and truthfulness within the existing generative frameworks. To address these challenges, this paper presents UniGen, a comprehensive LLM-powered framework designed to produce diverse, accurate, and highly controllable datasets. UniGen is adaptable, supporting all types of text datasets and enhancing the generative process through innovative mechanisms. To augment data diversity, UniGen incorporates an attribute-guided generation module and a group checking feature. For accuracy, it employs a code-based mathematical assessment for label verification alongside a retrieval-augmented generation technique for factual validation. The framework also allows for user-specified constraints, enabling customization of the data generation process to suit particular requirements. Extensive experiments demonstrate the superior quality of data generated by UniGen, and each module within UniGen plays a critical role in this enhancement. Additionally, UniGen is applied in two practical scenarios: benchmarking LLMs and data augmentation. The results indicate that UniGen effectively supports dynamic and evolving benchmarking, and that data augmentation improves LLM capabilities in various domains, including agent-oriented abilities and reasoning skills.
GUI-WORLD: A Dataset for GUI-oriented Multimodal LLM-based Agents
Jun 16, 2024

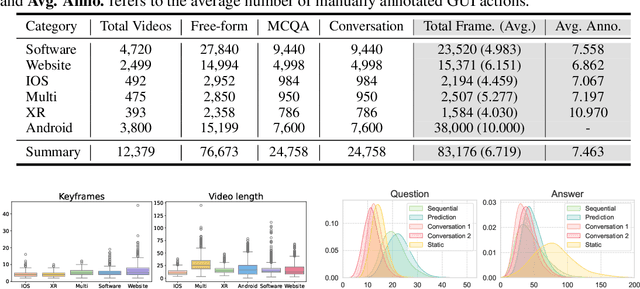

Recently, Multimodal Large Language Models (MLLMs) have been used as agents to control keyboard and mouse inputs by directly perceiving the Graphical User Interface (GUI) and generating corresponding code. However, current agents primarily exhibit excellent understanding capabilities in static environments and are predominantly applied in relatively simple domains, such as Web or mobile interfaces. We argue that a robust GUI agent should be capable of perceiving temporal information on the GUI, including dynamic Web content and multi-step tasks. Additionally, it should possess a comprehensive understanding of various GUI scenarios, including desktop software and multi-window interactions. To this end, this paper introduces a new dataset, termed GUI-World, which features meticulously crafted Human-MLLM annotations, extensively covering six GUI scenarios and eight types of GUI-oriented questions in three formats. We evaluate the capabilities of current state-of-the-art MLLMs, including ImageLLMs and VideoLLMs, in understanding various types of GUI content, especially dynamic and sequential content. Our findings reveal that ImageLLMs struggle with dynamic GUI content without manually annotated keyframes or operation history. On the other hand, VideoLLMs fall short in all GUI-oriented tasks given the sparse GUI video dataset. Based on GUI-World, we take the initial step of leveraging a fine-tuned VideoLLM as a GUI agent, demonstrating an improved understanding of various GUI tasks. However, due to the limitations in the performance of base LLMs, we conclude that using VideoLLMs as GUI agents remains a significant challenge. We believe our work provides valuable insights for future research in dynamic GUI content understanding. The code and dataset are publicly available at our project homepage: https://gui-world.github.io/.
The Best of Both Worlds: Toward an Honest and Helpful Large Language Model
Jun 01, 2024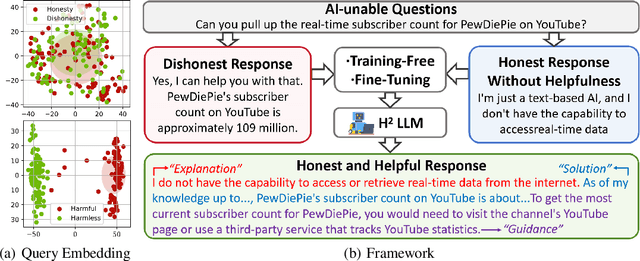
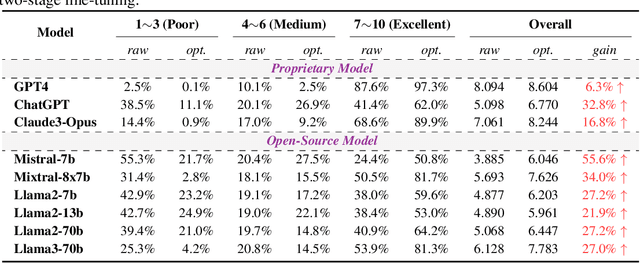
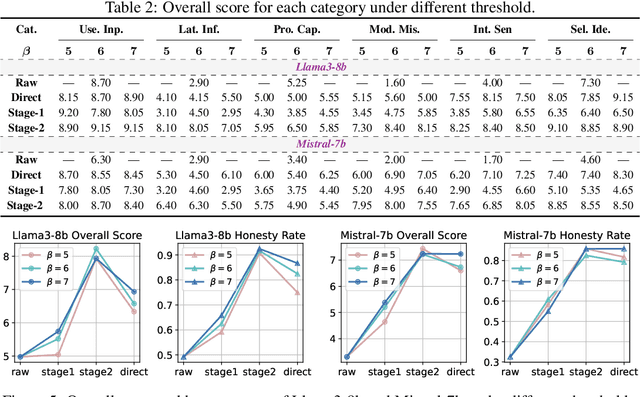
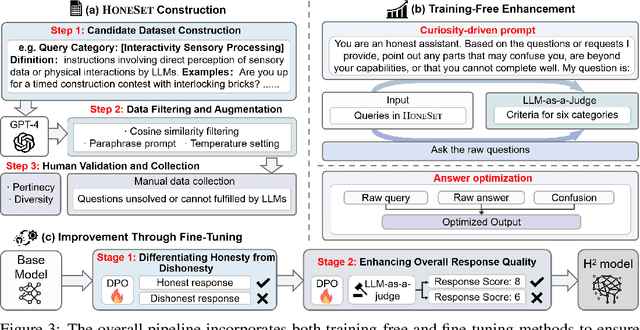
Large Language Models (LLMs) have achieved remarkable success across various industries due to their exceptional generative capabilities. However, for safe and effective real-world deployments, ensuring honesty and helpfulness is critical. This paper addresses the question: Can we prioritize the helpfulness of LLMs while preserving their honesty? To begin with, we establish exhaustive principles aimed at guaranteeing the honesty of LLM. Additionally, we introduce a novel dataset, referred to as HoneSet, comprising 930 queries spanning six categories meticulously crafted to assess an LLM's capacity for maintaining honesty. Subsequently, we present two approaches to augmenting honesty and helpfulness in LLMs: a training-free enhancement and a fine-tuning-based improvement. The training-free approach, which is based on curiosity-driven prompting, empowers LLMs to articulate internal confusion and uncertainty regarding queries, thereby optimizing their responses. Conversely, the fine-tuning-based method employs a two-stage process inspired by curriculum learning: initially instructing LLMs to discern between honest and dishonest responses, then refining their training to enhance helpfulness. Experiments conducted on nine prominent LLMs demonstrate a significant improvement in alignment with honesty across all models through the implementation of our proposed enhancements. Particularly noteworthy is the 65.3% enhancement observed in Llama3-8b and the remarkable 124.7% improvement in Mistral-7b, as measured by the H$^{2}$ (honest and helpful) assessment. We believe that our work can pave the way for developing more trustworthy LLMs for real-world applications.
MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark
Feb 07, 2024Multimodal Large Language Models (MLLMs) have gained significant attention recently, showing remarkable potential in artificial general intelligence. However, assessing the utility of MLLMs presents considerable challenges, primarily due to the absence multimodal benchmarks that align with human preferences. Inspired by LLM-as-a-Judge in LLMs, this paper introduces a novel benchmark, termed MLLM-as-a-Judge, to assess the ability of MLLMs in assisting judges including three distinct tasks: Scoring Evaluation, Pair Comparison, and Batch Ranking. Our study reveals that, while MLLMs demonstrate remarkable human-like discernment in Pair Comparisons, there is a significant divergence from human preferences in Scoring Evaluation and Batch Ranking tasks. Furthermore, MLLMs still face challenges in judgment, including diverse biases, hallucinatory responses, and inconsistencies, even for advanced models such as GPT-4V. These findings emphasize the pressing need for enhancements and further research efforts regarding MLLMs as fully reliable evaluators. Code and dataset are available at https://github.com/Dongping-Chen/MLLM-as-a-Judge.
TrustLLM: Trustworthiness in Large Language Models
Jan 25, 2024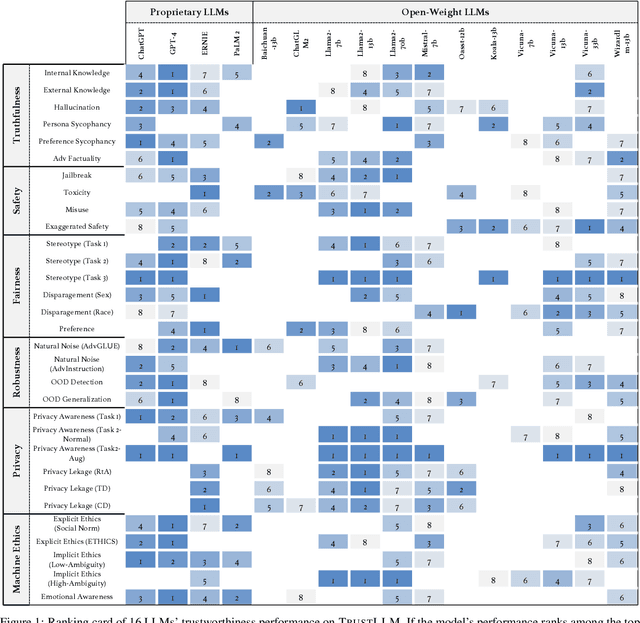


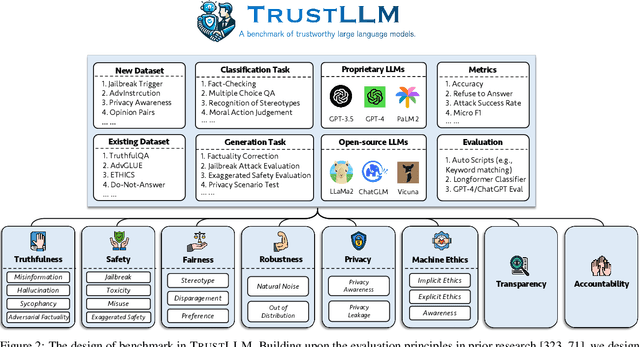
Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
LLM-as-a-Coauthor: The Challenges of Detecting LLM-Human Mixcase
Jan 11, 2024

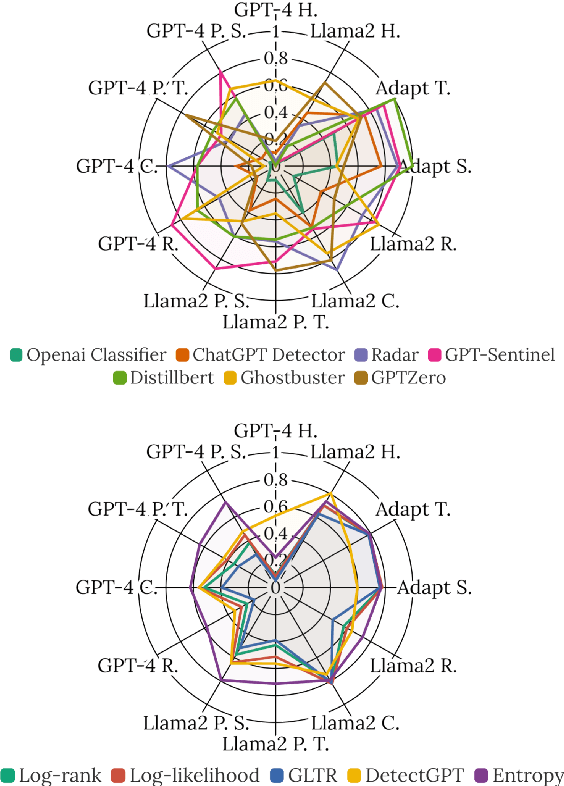
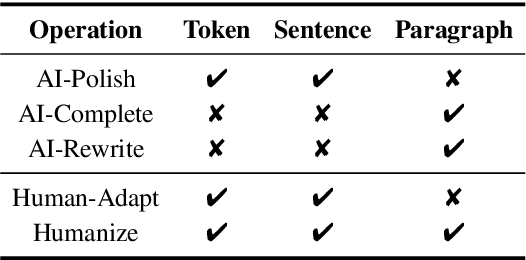
With the remarkable development and widespread applications of large language models (LLMs), the use of machine-generated text (MGT) is becoming increasingly common. This trend brings potential risks, particularly to the quality and completeness of information in fields such as news and education. Current research predominantly addresses the detection of pure MGT without adequately addressing mixed scenarios including AI-revised Human-Written Text (HWT) or human-revised MGT. To confront this challenge, we introduce mixcase, a novel concept representing a hybrid text form involving both machine-generated and human-generated content. We collected mixcase instances generated from multiple daily text-editing scenarios and composed MixSet, the first dataset dedicated to studying these mixed modification scenarios. We conduct experiments to evaluate the efficacy of popular MGT detectors, assessing their effectiveness, robustness, and generalization performance. Our findings reveal that existing detectors struggle to identify mixcase as a separate class or MGT, particularly in dealing with subtle modifications and style adaptability. This research underscores the urgent need for more fine-grain detectors tailored for mixcase, offering valuable insights for future research. Code and Models are available at https://github.com/Dongping-Chen/MixSet.