 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-a-Coauthor: The Challenges of Detecting LLM-Human Mixcase
Paper and Code


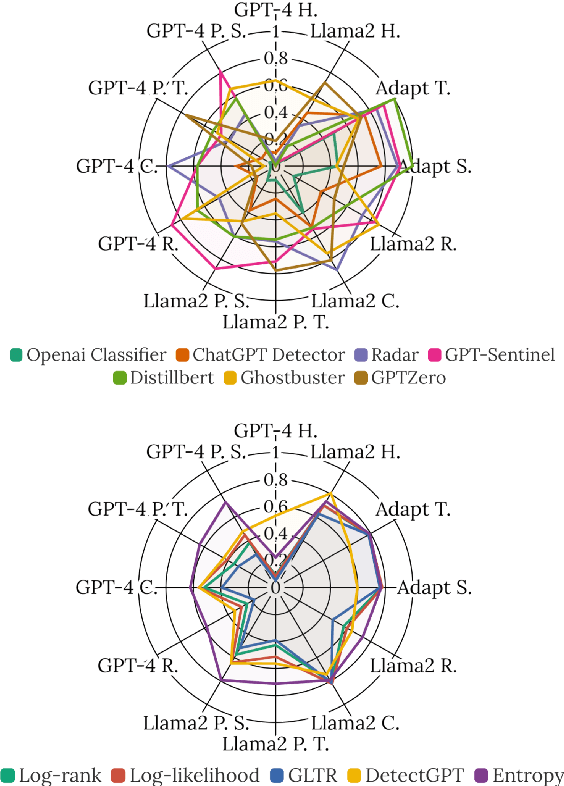
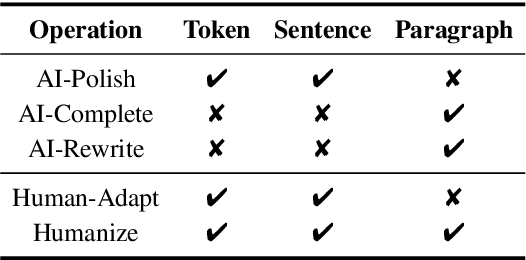
With the remarkable development and widespread applications of large language models (LLMs), the use of machine-generated text (MGT) is becoming increasingly common. This trend brings potential risks, particularly to the quality and completeness of information in fields such as news and education. Current research predominantly addresses the detection of pure MGT without adequately addressing mixed scenarios including AI-revised Human-Written Text (HWT) or human-revised MGT. To confront this challenge, we introduce mixcase, a novel concept representing a hybrid text form involving both machine-generated and human-generated content. We collected mixcase instances generated from multiple daily text-editing scenarios and composed MixSet, the first dataset dedicated to studying these mixed modification scenarios. We conduct experiments to evaluate the efficacy of popular MGT detectors, assessing their effectiveness, robustness, and generalization performance. Our findings reveal that existing detectors struggle to identify mixcase as a separate class or MGT, particularly in dealing with subtle modifications and style adaptability. This research underscores the urgent need for more fine-grain detectors tailored for mixcase, offering valuable insights for future research. Code and Models are available at https://github.com/Dongping-Chen/MixSet.