 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Focus: Contextual Distraction Curse in Large Language Models
Feb 03, 2025



Recent advances in Large Language Models (LLMs) have revolutionized generative systems, achieving excellent performance across diverse domains. Although these models perform well in controlled environments, their real-world applications frequently encounter inputs containing both essential and irrelevant details. Our investigation has revealed a critical vulnerability in LLMs, which we term Contextual Distraction Vulnerability (CDV). This phenomenon arises when models fail to maintain consistent performance on questions modified with semantically coherent but irrelevant context. To systematically investigate this vulnerability, we propose an efficient tree-based search methodology to automatically generate CDV examples. Our approach successfully generates CDV examples across four datasets, causing an average performance degradation of approximately 45% in state-of-the-art LLMs. To address this critical issue, we explore various mitigation strategies and find that post-targeted training approaches can effectively enhance model robustness against contextual distractions. Our findings highlight the fundamental nature of CDV as an ability-level challenge rather than a knowledge-level issue since models demonstrate the necessary knowledge by answering correctly in the absence of distractions. This calls the community's attention to address CDV during model development to ensure reliability. The code is available at https://github.com/wyf23187/LLM_CDV.
UniGen: A Unified Framework for Textual Dataset Generation Using Large Language Models
Jun 27, 2024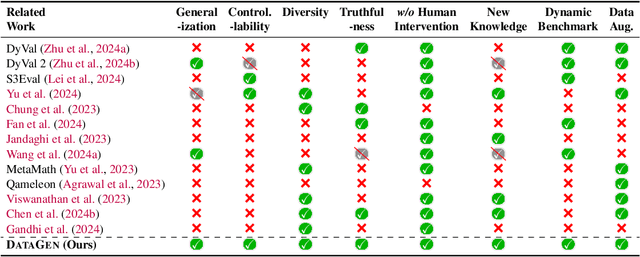
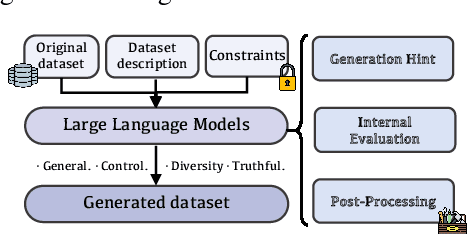
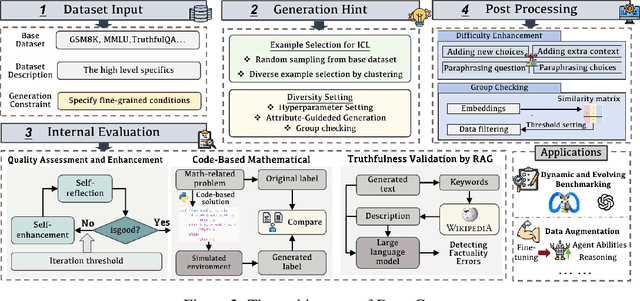

Large Language Models (LLMs) such as GPT-4 and Llama3 have significantly impacted various fields by enabling high-quality synthetic data generation and reducing dependence on expensive human-generated datasets. Despite this, challenges remain in the areas of generalization, controllability, diversity, and truthfulness within the existing generative frameworks. To address these challenges, this paper presents UniGen, a comprehensive LLM-powered framework designed to produce diverse, accurate, and highly controllable datasets. UniGen is adaptable, supporting all types of text datasets and enhancing the generative process through innovative mechanisms. To augment data diversity, UniGen incorporates an attribute-guided generation module and a group checking feature. For accuracy, it employs a code-based mathematical assessment for label verification alongside a retrieval-augmented generation technique for factual validation. The framework also allows for user-specified constraints, enabling customization of the data generation process to suit particular requirements. Extensive experiments demonstrate the superior quality of data generated by UniGen, and each module within UniGen plays a critical role in this enhancement. Additionally, UniGen is applied in two practical scenarios: benchmarking LLMs and data augmentation. The results indicate that UniGen effectively supports dynamic and evolving benchmarking, and that data augmentation improves LLM capabilities in various domains, including agent-oriented abilities and reasoning skills.
GUI-WORLD: A Dataset for GUI-oriented Multimodal LLM-based Agents
Jun 16, 2024

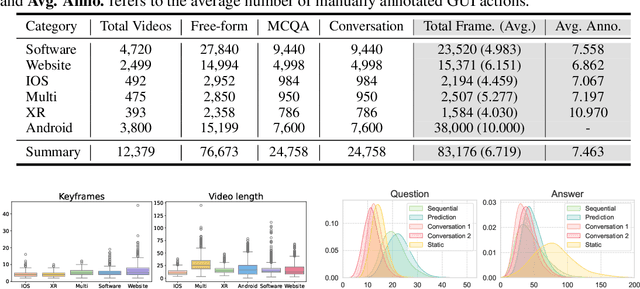

Recently, Multimodal Large Language Models (MLLMs) have been used as agents to control keyboard and mouse inputs by directly perceiving the Graphical User Interface (GUI) and generating corresponding code. However, current agents primarily exhibit excellent understanding capabilities in static environments and are predominantly applied in relatively simple domains, such as Web or mobile interfaces. We argue that a robust GUI agent should be capable of perceiving temporal information on the GUI, including dynamic Web content and multi-step tasks. Additionally, it should possess a comprehensive understanding of various GUI scenarios, including desktop software and multi-window interactions. To this end, this paper introduces a new dataset, termed GUI-World, which features meticulously crafted Human-MLLM annotations, extensively covering six GUI scenarios and eight types of GUI-oriented questions in three formats. We evaluate the capabilities of current state-of-the-art MLLMs, including ImageLLMs and VideoLLMs, in understanding various types of GUI content, especially dynamic and sequential content. Our findings reveal that ImageLLMs struggle with dynamic GUI content without manually annotated keyframes or operation history. On the other hand, VideoLLMs fall short in all GUI-oriented tasks given the sparse GUI video dataset. Based on GUI-World, we take the initial step of leveraging a fine-tuned VideoLLM as a GUI agent, demonstrating an improved understanding of various GUI tasks. However, due to the limitations in the performance of base LLMs, we conclude that using VideoLLMs as GUI agents remains a significant challenge. We believe our work provides valuable insights for future research in dynamic GUI content understanding. The code and dataset are publicly available at our project homepage: https://gui-world.github.io/.
The Best of Both Worlds: Toward an Honest and Helpful Large Language Model
Jun 01, 2024
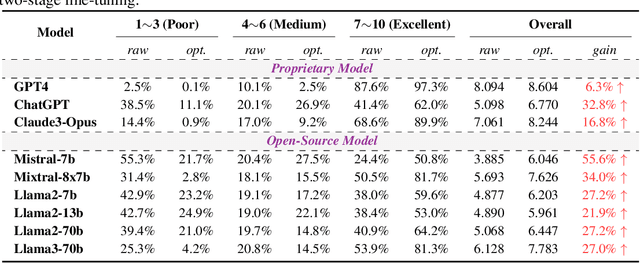
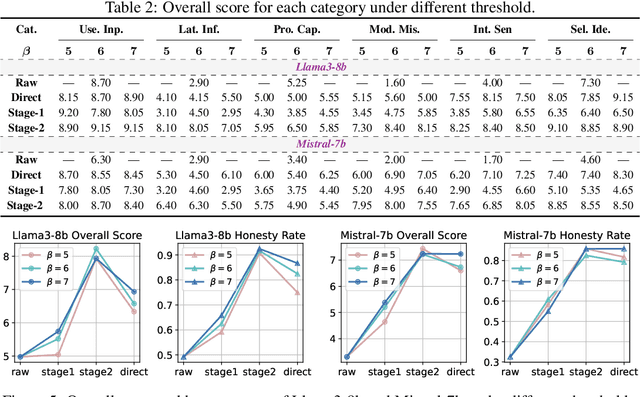
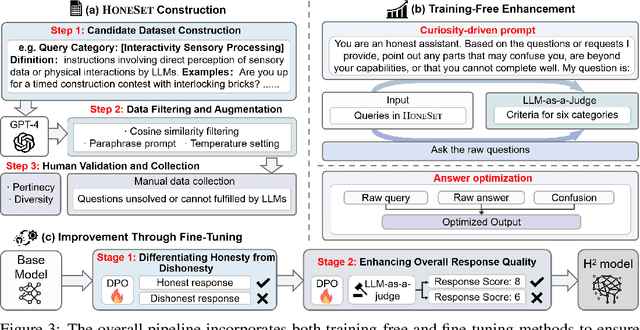
Large Language Models (LLMs) have achieved remarkable success across various industries due to their exceptional generative capabilities. However, for safe and effective real-world deployments, ensuring honesty and helpfulness is critical. This paper addresses the question: Can we prioritize the helpfulness of LLMs while preserving their honesty? To begin with, we establish exhaustive principles aimed at guaranteeing the honesty of LLM. Additionally, we introduce a novel dataset, referred to as HoneSet, comprising 930 queries spanning six categories meticulously crafted to assess an LLM's capacity for maintaining honesty. Subsequently, we present two approaches to augmenting honesty and helpfulness in LLMs: a training-free enhancement and a fine-tuning-based improvement. The training-free approach, which is based on curiosity-driven prompting, empowers LLMs to articulate internal confusion and uncertainty regarding queries, thereby optimizing their responses. Conversely, the fine-tuning-based method employs a two-stage process inspired by curriculum learning: initially instructing LLMs to discern between honest and dishonest responses, then refining their training to enhance helpfulness. Experiments conducted on nine prominent LLMs demonstrate a significant improvement in alignment with honesty across all models through the implementation of our proposed enhancements. Particularly noteworthy is the 65.3% enhancement observed in Llama3-8b and the remarkable 124.7% improvement in Mistral-7b, as measured by the H$^{2}$ (honest and helpful) assessment. We believe that our work can pave the way for developing more trustworthy LLMs for real-world applications.
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Feb 28, 2024



Sora is a text-to-video generative AI model, released by OpenAI in February 2024. The model is trained to generate videos of realistic or imaginative scenes from text instructions and show potential in simulating the physical world. Based on public technical reports and reverse engineering, this paper presents a comprehensive review of the model's background, related technologies, applications, remaining challenges, and future directions of text-to-video AI models. We first trace Sora's development and investigate the underlying technologies used to build this "world simulator". Then, we describe in detail the applications and potential impact of Sora in multiple industries ranging from film-making and education to marketing. We discuss the main challenges and limitations that need to be addressed to widely deploy Sora, such as ensuring safe and unbiased video generation. Lastly, we discuss the future development of Sora and video generation models in general, and how advancements in the field could enable new ways of human-AI interaction, boosting productivity and creativity of video generation.
TrustLLM: Trustworthiness in Large Language Models
Jan 25, 2024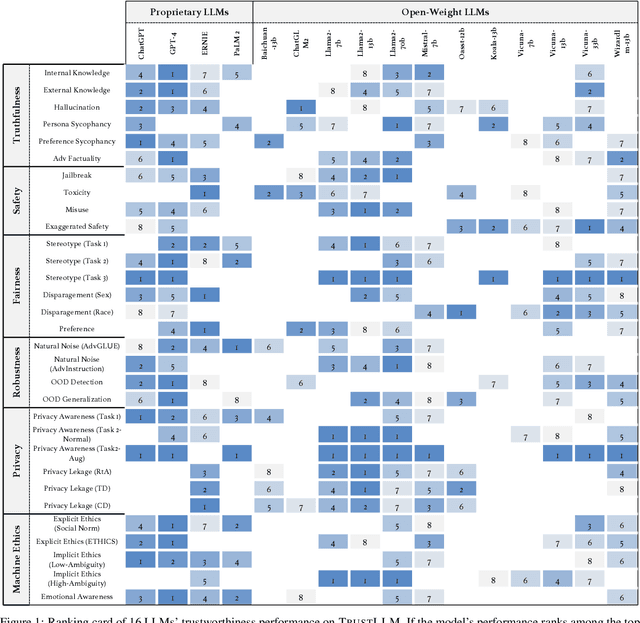


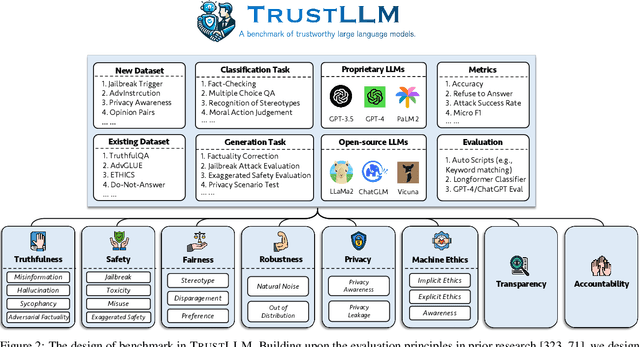
Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
LLM-as-a-Coauthor: The Challenges of Detecting LLM-Human Mixcase
Jan 11, 2024

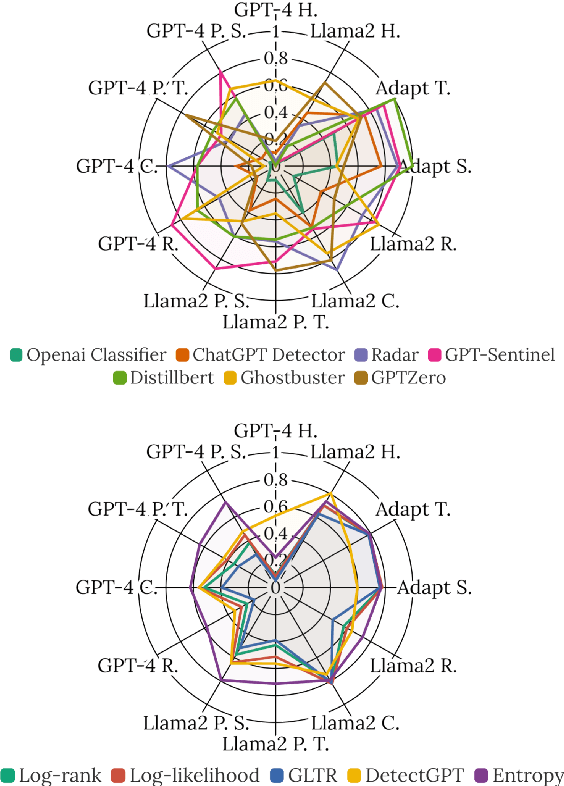
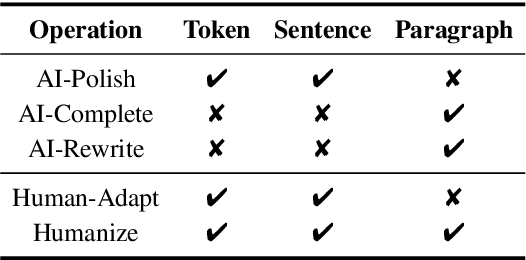
With the remarkable development and widespread applications of large language models (LLMs), the use of machine-generated text (MGT) is becoming increasingly common. This trend brings potential risks, particularly to the quality and completeness of information in fields such as news and education. Current research predominantly addresses the detection of pure MGT without adequately addressing mixed scenarios including AI-revised Human-Written Text (HWT) or human-revised MGT. To confront this challenge, we introduce mixcase, a novel concept representing a hybrid text form involving both machine-generated and human-generated content. We collected mixcase instances generated from multiple daily text-editing scenarios and composed MixSet, the first dataset dedicated to studying these mixed modification scenarios. We conduct experiments to evaluate the efficacy of popular MGT detectors, assessing their effectiveness, robustness, and generalization performance. Our findings reveal that existing detectors struggle to identify mixcase as a separate class or MGT, particularly in dealing with subtle modifications and style adaptability. This research underscores the urgent need for more fine-grain detectors tailored for mixcase, offering valuable insights for future research. Code and Models are available at https://github.com/Dongping-Chen/MixSet.