 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Best of Both Worlds: Toward an Honest and Helpful Large Language Model
Jun 01, 2024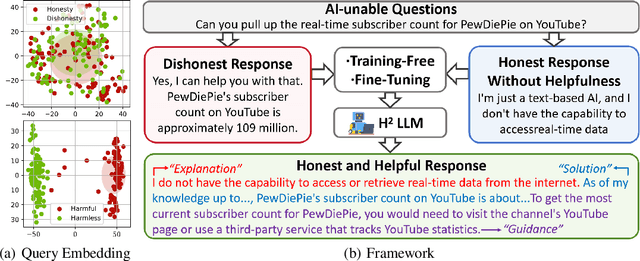
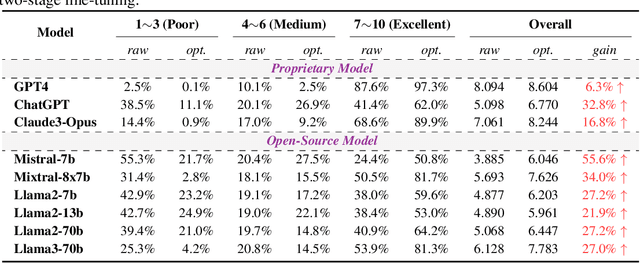
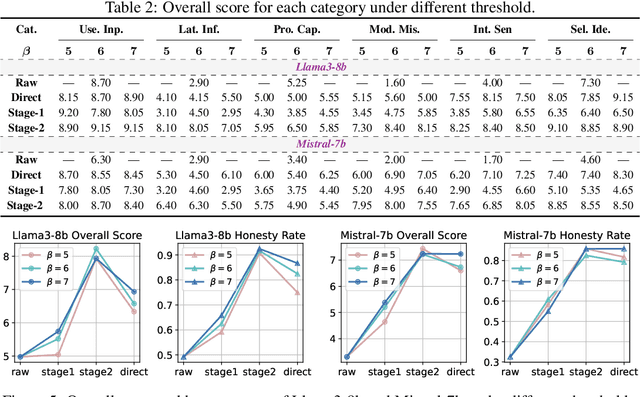
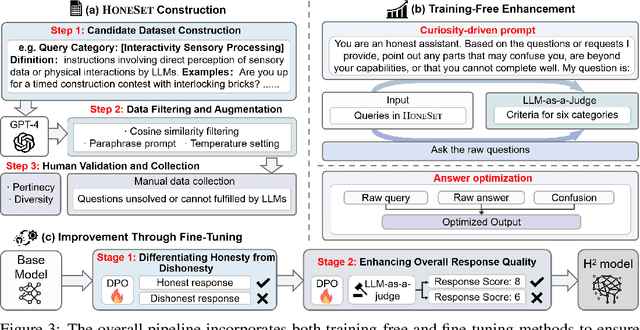
Large Language Models (LLMs) have achieved remarkable success across various industries due to their exceptional generative capabilities. However, for safe and effective real-world deployments, ensuring honesty and helpfulness is critical. This paper addresses the question: Can we prioritize the helpfulness of LLMs while preserving their honesty? To begin with, we establish exhaustive principles aimed at guaranteeing the honesty of LLM. Additionally, we introduce a novel dataset, referred to as HoneSet, comprising 930 queries spanning six categories meticulously crafted to assess an LLM's capacity for maintaining honesty. Subsequently, we present two approaches to augmenting honesty and helpfulness in LLMs: a training-free enhancement and a fine-tuning-based improvement. The training-free approach, which is based on curiosity-driven prompting, empowers LLMs to articulate internal confusion and uncertainty regarding queries, thereby optimizing their responses. Conversely, the fine-tuning-based method employs a two-stage process inspired by curriculum learning: initially instructing LLMs to discern between honest and dishonest responses, then refining their training to enhance helpfulness. Experiments conducted on nine prominent LLMs demonstrate a significant improvement in alignment with honesty across all models through the implementation of our proposed enhancements. Particularly noteworthy is the 65.3% enhancement observed in Llama3-8b and the remarkable 124.7% improvement in Mistral-7b, as measured by the H$^{2}$ (honest and helpful) assessment. We believe that our work can pave the way for developing more trustworthy LLMs for real-world applications.