 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuardian-as-an-Advisor: Advancing Next-Generation Guardian Models for Trustworthy LLMs
Apr 08, 2026Hard-gated safety checkers often over-refuse and misalign with a vendor's model spec; prevailing taxonomies also neglect robustness and honesty, yielding safer-on-paper yet less useful systems. This work introduces Guardian-as-an-Advisor (GaaA), a soft-gating pipeline where a guardian predicts a binary risk label plus a concise explanation and prepends this advice to the original query for re-inference, keeping the base model operating under its original spec. To support training and evaluation, GuardSet is constructed, a 208k+ multi-domain dataset unifying harmful and harmless cases with targeted robustness and honesty slices. GuardAdvisor is trained via SFT followed by RL to enforce label-explanation consistency. GuardAdvisor attains competitive detection accuracy while enabling the advisory workflow; when used to augment inputs, responses improve over unaugmented prompts. A latency study shows advisor inference uses below 5% of base-model compute and adds only 2-10% end-to-end overhead under realistic harmful-input rates. Overall, GaaA steers models to comply with the model spec, maintaining safety while reducing over-refusal.
Dissecting Logical Reasoning in LLMs: A Fine-Grained Evaluation and Supervision Study
Jun 05, 2025Logical reasoning is a core capability for many applications of large language models (LLMs), yet existing benchmarks often rely solely on final-answer accuracy, failing to capture the quality and structure of the reasoning process. We propose FineLogic, a fine-grained evaluation framework that assesses logical reasoning across three dimensions: overall benchmark accuracy, stepwise soundness, and representation-level alignment. In addition, to better understand how reasoning capabilities emerge, we conduct a comprehensive study on the effects of supervision format during fine-tuning. We construct four supervision styles (one natural language and three symbolic variants) and train LLMs under each. Our findings reveal that natural language supervision yields strong generalization even on out-of-distribution and long-context tasks, while symbolic reasoning styles promote more structurally sound and atomic inference chains. Further, our representation-level probing shows that fine-tuning primarily improves reasoning behaviors through step-by-step generation, rather than enhancing shortcut prediction or internalized correctness. Together, our framework and analysis provide a more rigorous and interpretable lens for evaluating and improving logical reasoning in LLMs.
SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models
May 29, 2025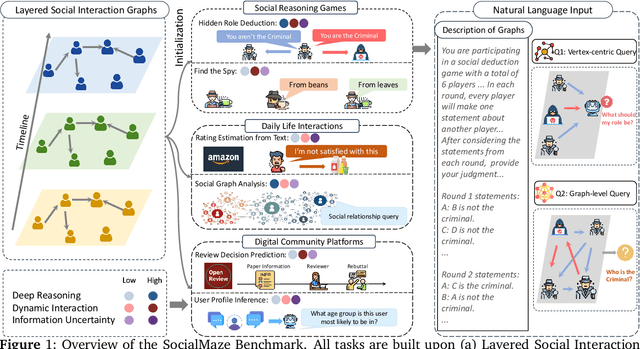
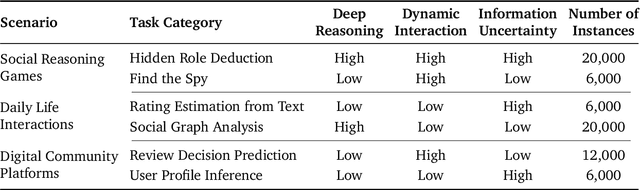
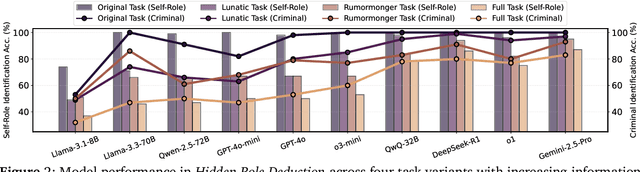
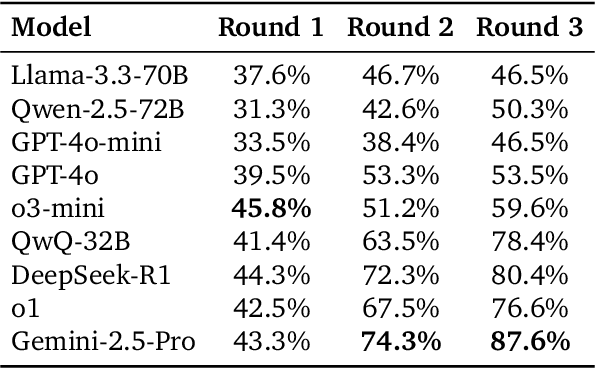
Large language models (LLMs) are increasingly applied to socially grounded tasks, such as online community moderation, media content analysis, and social reasoning games. Success in these contexts depends on a model's social reasoning ability - the capacity to interpret social contexts, infer others' mental states, and assess the truthfulness of presented information. However, there is currently no systematic evaluation framework that comprehensively assesses the social reasoning capabilities of LLMs. Existing efforts often oversimplify real-world scenarios and consist of tasks that are too basic to challenge advanced models. To address this gap, we introduce SocialMaze, a new benchmark specifically designed to evaluate social reasoning. SocialMaze systematically incorporates three core challenges: deep reasoning, dynamic interaction, and information uncertainty. It provides six diverse tasks across three key settings: social reasoning games, daily-life interactions, and digital community platforms. Both automated and human validation are used to ensure data quality. Our evaluation reveals several key insights: models vary substantially in their ability to handle dynamic interactions and integrate temporally evolving information; models with strong chain-of-thought reasoning perform better on tasks requiring deeper inference beyond surface-level cues; and model reasoning degrades significantly under uncertainty. Furthermore, we show that targeted fine-tuning on curated reasoning examples can greatly improve model performance in complex social scenarios. The dataset is publicly available at: https://huggingface.co/datasets/MBZUAI/SocialMaze
UPME: An Unsupervised Peer Review Framework for Multimodal Large Language Model Evaluation
Mar 19, 2025Multimodal Large Language Models (MLLMs) have emerged to tackle the challenges of Visual Question Answering (VQA), sparking a new research focus on conducting objective evaluations of these models. Existing evaluation methods face limitations due to the significant human workload required to design Q&A pairs for visual images, which inherently restricts the scale and scope of evaluations. Although automated MLLM-as-judge approaches attempt to reduce the human workload through automatic evaluations, they often introduce biases. To address these problems, we propose an Unsupervised Peer review MLLM Evaluation framework. It utilizes only image data, allowing models to automatically generate questions and conduct peer review assessments of answers from other models, effectively alleviating the reliance on human workload. Additionally, we introduce the vision-language scoring system to mitigate the bias issues, which focuses on three aspects: (i) response correctness; (ii) visual understanding and reasoning; and (iii) image-text correlation. Experimental results demonstrate that UPME achieves a Pearson correlation of 0.944 with human evaluations on the MMstar dataset and 0.814 on the ScienceQA dataset, indicating that our framework closely aligns with human-designed benchmarks and inherent human preferences.
Breaking Focus: Contextual Distraction Curse in Large Language Models
Feb 03, 2025



Recent advances in Large Language Models (LLMs) have revolutionized generative systems, achieving excellent performance across diverse domains. Although these models perform well in controlled environments, their real-world applications frequently encounter inputs containing both essential and irrelevant details. Our investigation has revealed a critical vulnerability in LLMs, which we term Contextual Distraction Vulnerability (CDV). This phenomenon arises when models fail to maintain consistent performance on questions modified with semantically coherent but irrelevant context. To systematically investigate this vulnerability, we propose an efficient tree-based search methodology to automatically generate CDV examples. Our approach successfully generates CDV examples across four datasets, causing an average performance degradation of approximately 45% in state-of-the-art LLMs. To address this critical issue, we explore various mitigation strategies and find that post-targeted training approaches can effectively enhance model robustness against contextual distractions. Our findings highlight the fundamental nature of CDV as an ability-level challenge rather than a knowledge-level issue since models demonstrate the necessary knowledge by answering correctly in the absence of distractions. This calls the community's attention to address CDV during model development to ensure reliability. The code is available at https://github.com/wyf23187/LLM_CDV.
Large Action Models: From Inception to Implementation
Dec 13, 2024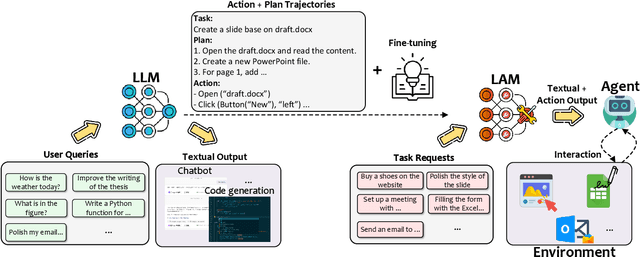

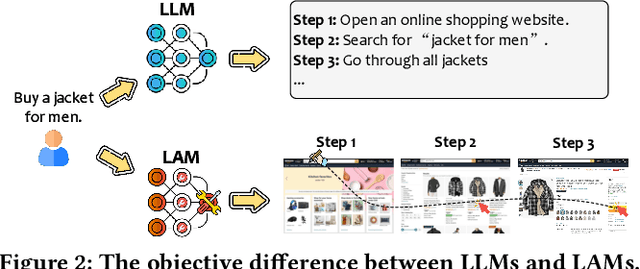

As AI continues to advance, there is a growing demand for systems that go beyond language-based assistance and move toward intelligent agents capable of performing real-world actions. This evolution requires the transition from traditional Large Language Models (LLMs), which excel at generating textual responses, to Large Action Models (LAMs), designed for action generation and execution within dynamic environments. Enabled by agent systems, LAMs hold the potential to transform AI from passive language understanding to active task completion, marking a significant milestone in the progression toward artificial general intelligence. In this paper, we present a comprehensive framework for developing LAMs, offering a systematic approach to their creation, from inception to deployment. We begin with an overview of LAMs, highlighting their unique characteristics and delineating their differences from LLMs. Using a Windows OS-based agent as a case study, we provide a detailed, step-by-step guide on the key stages of LAM development, including data collection, model training, environment integration, grounding, and evaluation. This generalizable workflow can serve as a blueprint for creating functional LAMs in various application domains. We conclude by identifying the current limitations of LAMs and discussing directions for future research and industrial deployment, emphasizing the challenges and opportunities that lie ahead in realizing the full potential of LAMs in real-world applications. The code for the data collection process utilized in this paper is publicly available at: https://github.com/microsoft/UFO/tree/main/dataflow, and comprehensive documentation can be found at https://microsoft.github.io/UFO/dataflow/overview/.
AutoBench-V: Can Large Vision-Language Models Benchmark Themselves?
Oct 29, 2024Large Vision-Language Models (LVLMs) have become essential for advancing the integration of visual and linguistic information, facilitating a wide range of complex applications and tasks. However, the evaluation of LVLMs presents significant challenges as the evaluation benchmark always demands lots of human cost for its construction, and remains static, lacking flexibility once constructed. Even though automatic evaluation has been explored in textual modality, the visual modality remains under-explored. As a result, in this work, we address a question: "Can LVLMs serve as a path to automatic benchmarking?". We introduce AutoBench-V, an automated framework for serving evaluation on demand, i.e., benchmarking LVLMs based on specific aspects of model capability. Upon receiving an evaluation capability, AutoBench-V leverages text-to-image models to generate relevant image samples and then utilizes LVLMs to orchestrate visual question-answering (VQA) tasks, completing the evaluation process efficiently and flexibly. Through an extensive evaluation of seven popular LVLMs across five demanded user inputs (i.e., evaluation capabilities), the framework shows effectiveness and reliability. We observe the following: (1) Our constructed benchmark accurately reflects varying task difficulties; (2) As task difficulty rises, the performance gap between models widens; (3) While models exhibit strong performance in abstract level understanding, they underperform in details reasoning tasks; and (4) Constructing a dataset with varying levels of difficulties is critical for a comprehensive and exhaustive evaluation. Overall, AutoBench-V not only successfully utilizes LVLMs for automated benchmarking but also reveals that LVLMs as judges have significant potential in various domains.
Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge
Oct 03, 2024



LLM-as-a-Judge has been widely utilized as an evaluation method in various benchmarks and served as supervised rewards in model training. However, despite their excellence in many domains, potential issues are under-explored, undermining their reliability and the scope of their utility. Therefore, we identify 12 key potential biases and propose a new automated bias quantification framework-CALM-which systematically quantifies and analyzes each type of bias in LLM-as-a-Judge by using automated and principle-guided modification. Our experiments cover multiple popular language models, and the results indicate that while advanced models have achieved commendable overall performance, significant biases persist in certain specific tasks. Empirical results suggest that there remains room for improvement in the reliability of LLM-as-a-Judge. Moreover, we also discuss the explicit and implicit influence of these biases and give some suggestions for the reliable application of LLM-as-a-Judge. Our work highlights the need for stakeholders to address these issues and remind users to exercise caution in LLM-as-a-Judge applications.
Archiving Body Movements: Collective Generation of Chinese Calligraphy
Nov 27, 2023



As a communication channel, body movements have been widely explored in behavioral studies and kinesics. Performing and visual arts share the same interests but focus on documenting and representing human body movements, such as for dance notation and visual work creation. This paper investigates body movements in oriental calligraphy and how to apply calligraphy principles to stimulate and archive body movements. Through an artwork (Wushu), the authors experiment with an interactive and generative approach to engage the audience's bodily participation and archive the body movements as a compendium of generated calligraphy. The audience assumes the role of both writers and readers; creating ("writing") and appreciating ("reading") the generated calligraphy becomes a cyclical process within this infinite "Book," which can motivate further attention and discussions concerning Chinese characters and calligraphy.
Chasing Consistency in Text-to-3D Generation from a Single Image
Sep 07, 2023

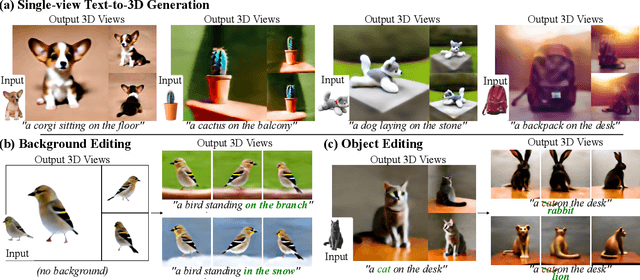
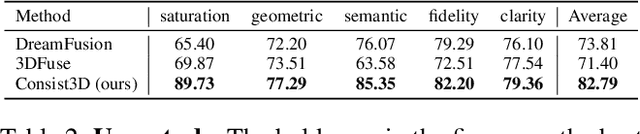
Text-to-3D generation from a single-view image is a popular but challenging task in 3D vision. Although numerous methods have been proposed, existing works still suffer from the inconsistency issues, including 1) semantic inconsistency, 2) geometric inconsistency, and 3) saturation inconsistency, resulting in distorted, overfitted, and over-saturated generations. In light of the above issues, we present Consist3D, a three-stage framework Chasing for semantic-, geometric-, and saturation-Consistent Text-to-3D generation from a single image, in which the first two stages aim to learn parameterized consistency tokens, and the last stage is for optimization. Specifically, the semantic encoding stage learns a token independent of views and estimations, promoting semantic consistency and robustness. Meanwhile, the geometric encoding stage learns another token with comprehensive geometry and reconstruction constraints under novel-view estimations, reducing overfitting and encouraging geometric consistency. Finally, the optimization stage benefits from the semantic and geometric tokens, allowing a low classifier-free guidance scale and therefore preventing oversaturation. Experimental results demonstrate that Consist3D produces more consistent, faithful, and photo-realistic 3D assets compared to previous state-of-the-art methods. Furthermore, Consist3D also allows background and object editing through text prompts.