 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChasing Consistency in Text-to-3D Generation from a Single Image
Paper and Code
Sep 07, 2023

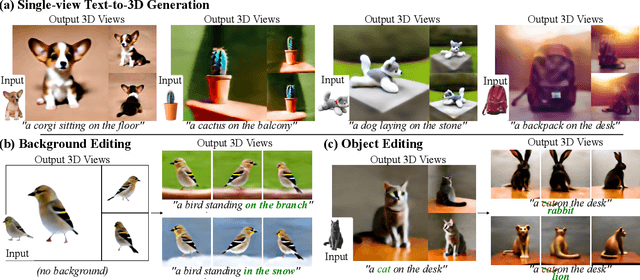
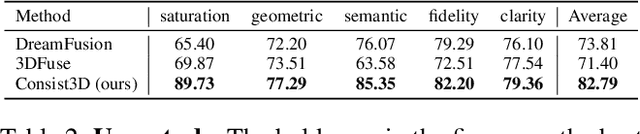
Text-to-3D generation from a single-view image is a popular but challenging task in 3D vision. Although numerous methods have been proposed, existing works still suffer from the inconsistency issues, including 1) semantic inconsistency, 2) geometric inconsistency, and 3) saturation inconsistency, resulting in distorted, overfitted, and over-saturated generations. In light of the above issues, we present Consist3D, a three-stage framework Chasing for semantic-, geometric-, and saturation-Consistent Text-to-3D generation from a single image, in which the first two stages aim to learn parameterized consistency tokens, and the last stage is for optimization. Specifically, the semantic encoding stage learns a token independent of views and estimations, promoting semantic consistency and robustness. Meanwhile, the geometric encoding stage learns another token with comprehensive geometry and reconstruction constraints under novel-view estimations, reducing overfitting and encouraging geometric consistency. Finally, the optimization stage benefits from the semantic and geometric tokens, allowing a low classifier-free guidance scale and therefore preventing oversaturation. Experimental results demonstrate that Consist3D produces more consistent, faithful, and photo-realistic 3D assets compared to previous state-of-the-art methods. Furthermore, Consist3D also allows background and object editing through text prompts.