 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-level Proximal Policy Optimization for Query Generation
Nov 01, 2024Query generation is a critical task for web search engines (e.g. Google, Bing) and recommendation systems. Recently, state-of-the-art query generation methods leverage Large Language Models (LLMs) for their strong capabilities in context understanding and text generation. However, they still face challenges in generating high-quality queries in terms of inferring user intent based on their web search interaction history. In this paper, we propose Token-level Proximal Policy Optimization (TPPO), a noval approach designed to empower LLMs perform better in query generation through fine-tuning. TPPO is based on the Reinforcement Learning from AI Feedback (RLAIF) paradigm, consisting of a token-level reward model and a token-level proximal policy optimization module to address the sparse reward challenge in traditional RLAIF frameworks. To evaluate the effectiveness and robustness of TPPO, we conducted experiments on both open-source dataset and an industrial dataset that was collected from a globally-used search engine. The experimental results demonstrate that TPPO significantly improves the performance of query generation for LLMs and outperforms its existing competitors.
FlexiFilm: Long Video Generation with Flexible Conditions
Apr 29, 2024


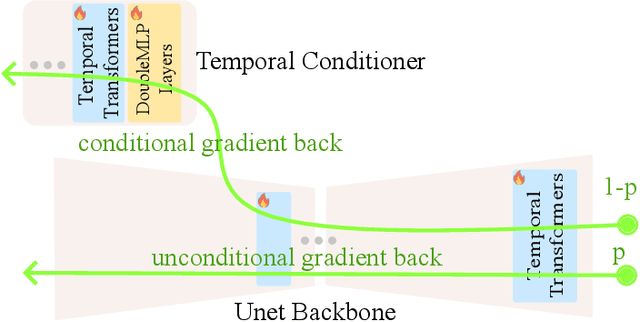
Generating long and consistent videos has emerged as a significant yet challenging problem. While most existing diffusion-based video generation models, derived from image generation models, demonstrate promising performance in generating short videos, their simple conditioning mechanism and sampling strategy-originally designed for image generation-cause severe performance degradation when adapted to long video generation. This results in prominent temporal inconsistency and overexposure. Thus, in this work, we introduce FlexiFilm, a new diffusion model tailored for long video generation. Our framework incorporates a temporal conditioner to establish a more consistent relationship between generation and multi-modal conditions, and a resampling strategy to tackle overexposure. Empirical results demonstrate FlexiFilm generates long and consistent videos, each over 30 seconds in length, outperforming competitors in qualitative and quantitative analyses. Project page: https://y-ichen.github.io/FlexiFilm-Page/
Chasing Consistency in Text-to-3D Generation from a Single Image
Sep 07, 2023

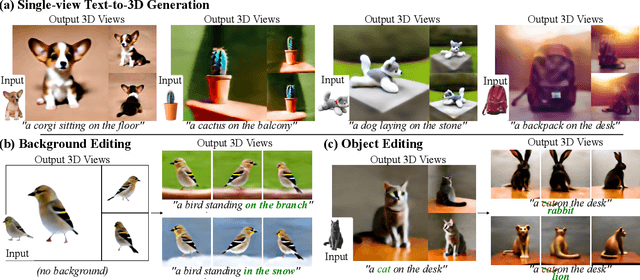
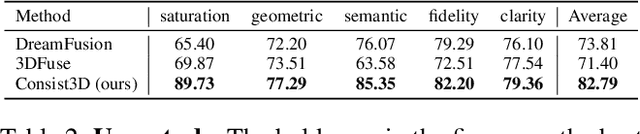
Text-to-3D generation from a single-view image is a popular but challenging task in 3D vision. Although numerous methods have been proposed, existing works still suffer from the inconsistency issues, including 1) semantic inconsistency, 2) geometric inconsistency, and 3) saturation inconsistency, resulting in distorted, overfitted, and over-saturated generations. In light of the above issues, we present Consist3D, a three-stage framework Chasing for semantic-, geometric-, and saturation-Consistent Text-to-3D generation from a single image, in which the first two stages aim to learn parameterized consistency tokens, and the last stage is for optimization. Specifically, the semantic encoding stage learns a token independent of views and estimations, promoting semantic consistency and robustness. Meanwhile, the geometric encoding stage learns another token with comprehensive geometry and reconstruction constraints under novel-view estimations, reducing overfitting and encouraging geometric consistency. Finally, the optimization stage benefits from the semantic and geometric tokens, allowing a low classifier-free guidance scale and therefore preventing oversaturation. Experimental results demonstrate that Consist3D produces more consistent, faithful, and photo-realistic 3D assets compared to previous state-of-the-art methods. Furthermore, Consist3D also allows background and object editing through text prompts.