 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-level Proximal Policy Optimization for Query Generation
Nov 01, 2024Query generation is a critical task for web search engines (e.g. Google, Bing) and recommendation systems. Recently, state-of-the-art query generation methods leverage Large Language Models (LLMs) for their strong capabilities in context understanding and text generation. However, they still face challenges in generating high-quality queries in terms of inferring user intent based on their web search interaction history. In this paper, we propose Token-level Proximal Policy Optimization (TPPO), a noval approach designed to empower LLMs perform better in query generation through fine-tuning. TPPO is based on the Reinforcement Learning from AI Feedback (RLAIF) paradigm, consisting of a token-level reward model and a token-level proximal policy optimization module to address the sparse reward challenge in traditional RLAIF frameworks. To evaluate the effectiveness and robustness of TPPO, we conducted experiments on both open-source dataset and an industrial dataset that was collected from a globally-used search engine. The experimental results demonstrate that TPPO significantly improves the performance of query generation for LLMs and outperforms its existing competitors.
Model-enhanced Vector Index
Sep 23, 2023

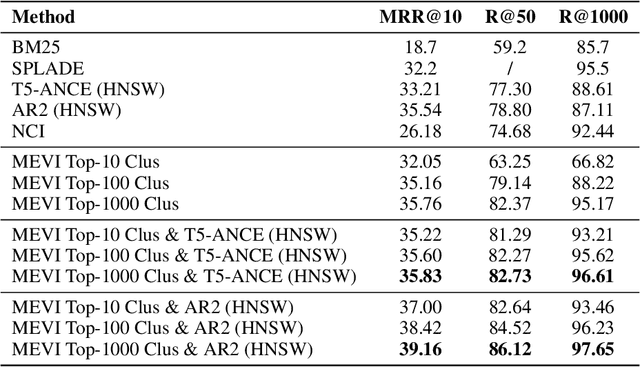

Embedding-based retrieval methods construct vector indices to search for document representations that are most similar to the query representations. They are widely used in document retrieval due to low latency and decent recall performance. Recent research indicates that deep retrieval solutions offer better model quality, but are hindered by unacceptable serving latency and the inability to support document updates. In this paper, we aim to enhance the vector index with end-to-end deep generative models, leveraging the differentiable advantages of deep retrieval models while maintaining desirable serving efficiency. We propose Model-enhanced Vector Index (MEVI), a differentiable model-enhanced index empowered by a twin-tower representation model. MEVI leverages a Residual Quantization (RQ) codebook to bridge the sequence-to-sequence deep retrieval and embedding-based models. To substantially reduce the inference time, instead of decoding the unique document ids in long sequential steps, we first generate some semantic virtual cluster ids of candidate documents in a small number of steps, and then leverage the well-adapted embedding vectors to further perform a fine-grained search for the relevant documents in the candidate virtual clusters. We empirically show that our model achieves better performance on the commonly used academic benchmarks MSMARCO Passage and Natural Questions, with comparable serving latency to dense retrieval solutions.
AdsGNN: Behavior-Graph Augmented Relevance Modeling in Sponsored Search
Apr 25, 2021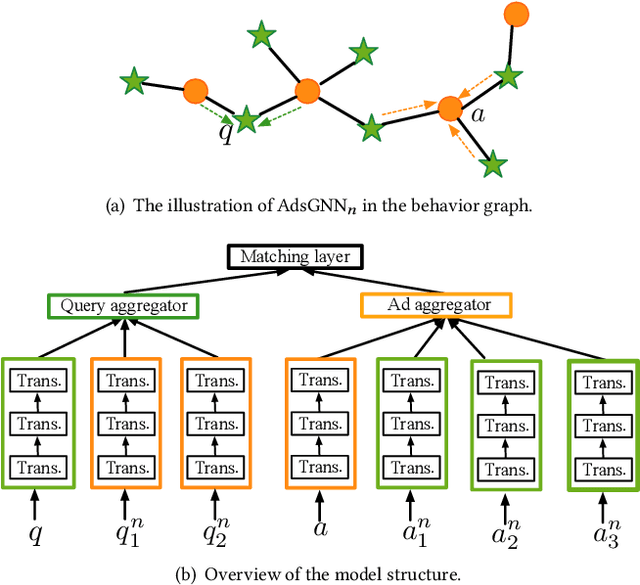

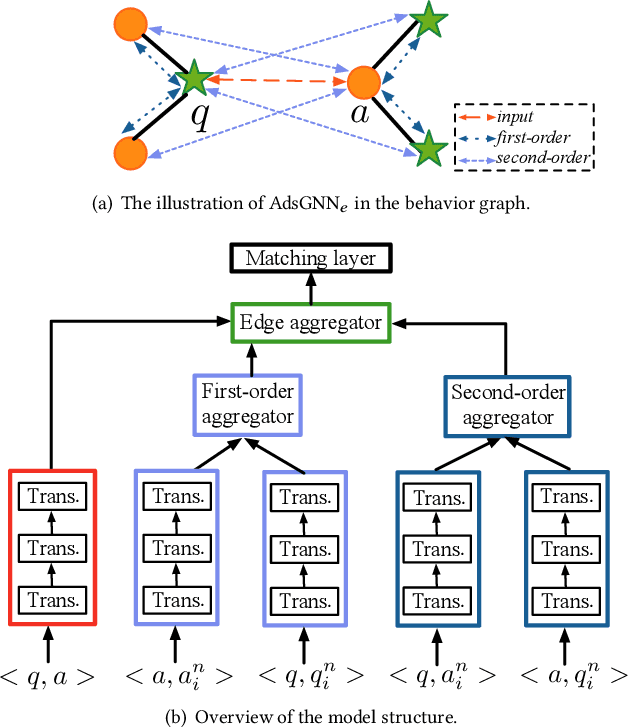
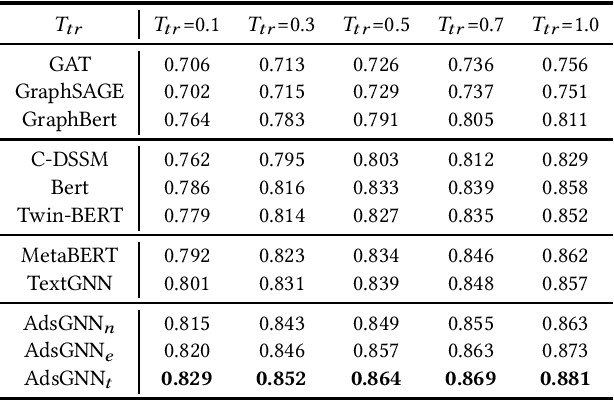
Sponsored search ads appear next to search results when people look for products and services on search engines. In recent years, they have become one of the most lucrative channels for marketing. As the fundamental basis of search ads, relevance modeling has attracted increasing attention due to the significant research challenges and tremendous practical value. Most existing approaches solely rely on the semantic information in the input query-ad pair, while the pure semantic information in the short ads data is not sufficient to fully identify user's search intents. Our motivation lies in incorporating the tremendous amount of unsupervised user behavior data from the historical search logs as the complementary graph to facilitate relevance modeling. In this paper, we extensively investigate how to naturally fuse the semantic textual information with the user behavior graph, and further propose three novel AdsGNN models to aggregate topological neighborhood from the perspectives of nodes, edges and tokens. Furthermore, two critical but rarely investigated problems, domain-specific pre-training and long-tail ads matching, are studied thoroughly. Empirically, we evaluate the AdsGNN models over the large industry dataset, and the experimental results of online/offline tests consistently demonstrate the superiority of our proposal.