 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgerStar2-Agent: Agentic Reasoning Technical Report
Aug 28, 2025We introduce rStar2-Agent, a 14B math reasoning model trained with agentic reinforcement learning to achieve frontier-level performance. Beyond current long CoT, the model demonstrates advanced cognitive behaviors, such as thinking carefully before using Python coding tools and reflecting on code execution feedback to autonomously explore, verify, and refine intermediate steps in complex problem-solving. This capability is enabled through three key innovations that makes agentic RL effective at scale: (i) an efficient RL infrastructure with a reliable Python code environment that supports high-throughput execution and mitigates the high rollout costs, enabling training on limited GPU resources (64 MI300X GPUs); (ii) GRPO-RoC, an agentic RL algorithm with a Resample-on-Correct rollout strategy that addresses the inherent environment noises from coding tools, allowing the model to reason more effectively in a code environment; (iii) An efficient agent training recipe that starts with non-reasoning SFT and progresses through multi-RL stages, yielding advanced cognitive abilities with minimal compute cost. To this end, rStar2-Agent boosts a pre-trained 14B model to state of the art in only 510 RL steps within one week, achieving average pass@1 scores of 80.6% on AIME24 and 69.8% on AIME25, surpassing DeepSeek-R1 (671B) with significantly shorter responses. Beyond mathematics, rStar2-Agent-14B also demonstrates strong generalization to alignment, scientific reasoning, and agentic tool-use tasks. Code and training recipes are available at https://github.com/microsoft/rStar.
MoE-CAP: Benchmarking Cost, Accuracy and Performance of Sparse Mixture-of-Experts Systems
May 16, 2025The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently, but it depends on heterogeneous compute and memory resources. These factors jointly affect system Cost, Accuracy, and Performance (CAP), making trade-offs inevitable. Existing benchmarks often fail to capture these trade-offs accurately, complicating practical deployment decisions. To address this, we introduce MoE-CAP, a benchmark specifically designed for MoE systems. Our analysis reveals that achieving an optimal balance across CAP is difficult with current hardware; MoE systems typically optimize two of the three dimensions at the expense of the third-a dynamic we term the MoE-CAP trade-off. To visualize this, we propose the CAP Radar Diagram. We further introduce sparsity-aware performance metrics-Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU)-to enable accurate performance benchmarking of MoE systems across diverse hardware platforms and deployment scenarios.
AttentionEngine: A Versatile Framework for Efficient Attention Mechanisms on Diverse Hardware Platforms
Feb 21, 2025Transformers and large language models (LLMs) have revolutionized machine learning, with attention mechanisms at the core of their success. As the landscape of attention variants expands, so too do the challenges of optimizing their performance, particularly across different hardware platforms. Current optimization strategies are often narrowly focused, requiring extensive manual intervention to accommodate changes in model configurations or hardware environments. In this paper, we introduce AttentionEngine, a comprehensive framework designed to streamline the optimization of attention mechanisms across heterogeneous hardware backends. By decomposing attention computation into modular operations with customizable components, AttentionEngine enables flexible adaptation to diverse algorithmic requirements. The framework further automates kernel optimization through a combination of programmable templates and a robust cross-platform scheduling strategy. Empirical results reveal performance gains of up to 10x on configurations beyond the reach of existing methods. AttentionEngine offers a scalable, efficient foundation for developing and deploying attention mechanisms with minimal manual tuning. Our code has been open-sourced and is available at https://github.com/microsoft/AttentionEngine.
WaferLLM: A Wafer-Scale LLM Inference System
Feb 06, 2025Emerging AI accelerators increasingly adopt wafer-scale manufacturing technologies, integrating hundreds of thousands of AI cores in a mesh-based architecture with large distributed on-chip memory (tens of GB in total) and ultra-high on-chip memory bandwidth (tens of PB/s). However, current LLM inference systems, optimized for shared memory architectures like GPUs, fail to fully exploit these accelerators. We introduce WaferLLM, the first wafer-scale LLM inference system. WaferLLM is guided by a novel PLMR device model that captures the unique hardware characteristics of wafer-scale architectures. Leveraging this model, WaferLLM pioneers wafer-scale LLM parallelism, optimizing the utilization of hundreds of thousands of on-chip cores. It also introduces MeshGEMM and MeshGEMV, the first GEMM and GEMV implementations designed to scale effectively on wafer-scale accelerators. Evaluations show that WaferLLM achieves 200$\times$ better wafer-scale accelerator utilization than state-of-the-art systems. On a commodity wafer-scale accelerator, WaferLLM delivers 606$\times$ faster and 22$\times$ more energy-efficient GEMV compared to an advanced GPU. For LLMs, WaferLLM enables 39$\times$ faster decoding with 1.7$\times$ better energy efficiency. We anticipate these numbers will grow significantly as wafer-scale AI models, software, and hardware continue to mature.
MoE-CAP: Cost-Accuracy-Performance Benchmarking for Mixture-of-Experts Systems
Dec 10, 2024The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently; however, MoE systems rely on heterogeneous compute and memory resources. These factors collectively influence the system's Cost, Accuracy, and Performance (CAP), creating a challenging trade-off. Current benchmarks often fail to provide precise estimates of these effects, complicating practical considerations for deploying MoE systems. To bridge this gap, we introduce MoE-CAP, a benchmark specifically designed to evaluate MoE systems. Our findings highlight the difficulty of achieving an optimal balance of cost, accuracy, and performance with existing hardware capabilities. MoE systems often necessitate compromises on one factor to optimize the other two, a dynamic we term the MoE-CAP trade-off. To identify the best trade-off, we propose novel performance evaluation metrics - Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU) - and develop cost models that account for the heterogeneous compute and memory hardware integral to MoE systems. This benchmark is publicly available on HuggingFace: https://huggingface.co/spaces/sparse-generative-ai/open-moe-llm-leaderboard.
Scaling Deep Learning Computation over the Inter-Core Connected Intelligence Processor
Aug 09, 2024As AI chips incorporate numerous parallelized cores to scale deep learning (DL) computing, inter-core communication is enabled recently by employing high-bandwidth and low-latency interconnect links on the chip (e.g., Graphcore IPU). It allows each core to directly access the fast scratchpad memory in other cores, which enables new parallel computing paradigms. However, without proper support for the scalable inter-core connections in current DL compilers, it is hard for developers to exploit the benefits of this new architecture. We present T10, the first DL compiler to exploit the inter-core communication bandwidth and distributed on-chip memory on AI chips. To formulate the computation and communication patterns of tensor operators in this new architecture, T10 introduces a distributed tensor abstraction rTensor. T10 maps a DNN model to execution plans with a generalized compute-shift pattern, by partitioning DNN computation into sub-operators and mapping them to cores, so that the cores can exchange data following predictable patterns. T10 makes globally optimized trade-offs between on-chip memory consumption and inter-core communication overhead, selects the best execution plan from a vast optimization space, and alleviates unnecessary inter-core communications. Our evaluation with a real inter-core connected AI chip, the Graphcore IPU, shows up to 3.3$\times$ performance improvement, and scalability support for larger models, compared to state-of-the-art DL compilers and vendor libraries.
Model-enhanced Vector Index
Sep 23, 2023

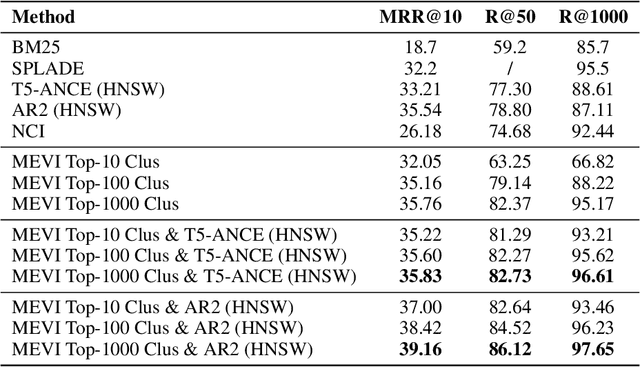

Embedding-based retrieval methods construct vector indices to search for document representations that are most similar to the query representations. They are widely used in document retrieval due to low latency and decent recall performance. Recent research indicates that deep retrieval solutions offer better model quality, but are hindered by unacceptable serving latency and the inability to support document updates. In this paper, we aim to enhance the vector index with end-to-end deep generative models, leveraging the differentiable advantages of deep retrieval models while maintaining desirable serving efficiency. We propose Model-enhanced Vector Index (MEVI), a differentiable model-enhanced index empowered by a twin-tower representation model. MEVI leverages a Residual Quantization (RQ) codebook to bridge the sequence-to-sequence deep retrieval and embedding-based models. To substantially reduce the inference time, instead of decoding the unique document ids in long sequential steps, we first generate some semantic virtual cluster ids of candidate documents in a small number of steps, and then leverage the well-adapted embedding vectors to further perform a fine-grained search for the relevant documents in the candidate virtual clusters. We empirically show that our model achieves better performance on the commonly used academic benchmarks MSMARCO Passage and Natural Questions, with comparable serving latency to dense retrieval solutions.
A Neural Corpus Indexer for Document Retrieval
Jun 06, 2022
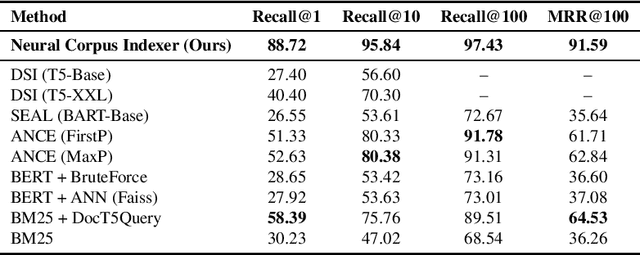
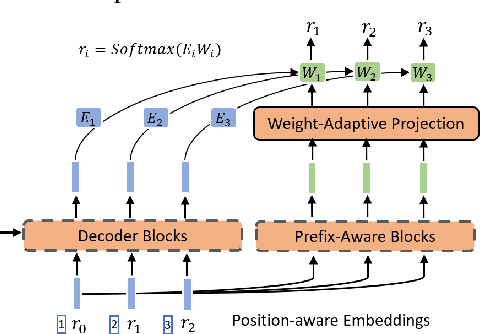
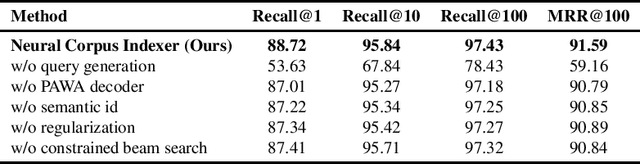
Current state-of-the-art document retrieval solutions mainly follow an index-retrieve paradigm, where the index is hard to be optimized for the final retrieval target. In this paper, we aim to show that an end-to-end deep neural network unifying training and indexing stages can significantly improve the recall performance of traditional methods. To this end, we propose Neural Corpus Indexer (NCI), a sequence-to-sequence network that generates relevant document identifiers directly for a designated query. To optimize the recall performance of NCI, we invent a prefix-aware weight-adaptive decoder architecture, and leverage tailored techniques including query generation, semantic document identifiers and consistency-based regularization. Empirical studies demonstrated the superiority of NCI on a commonly used academic benchmark, achieving +51.9% relative improvement on NQ320k dataset compared to the best baseline.