 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeerAttention-R: Sparse Attention Adaptation for Long Reasoning
Jun 10, 2025



We introduce SeerAttention-R, a sparse attention framework specifically tailored for the long decoding of reasoning models. Extended from SeerAttention, SeerAttention-R retains the design of learning attention sparsity through a self-distilled gating mechanism, while removing query pooling to accommodate auto-regressive decoding. With a lightweight plug-in gating, SeerAttention-R is flexible and can be easily integrated into existing pretrained model without modifying the original parameters. We demonstrate that SeerAttention-R, trained on just 0.4B tokens, maintains near-lossless reasoning accuracy with 4K token budget in AIME benchmark under large sparse attention block sizes (64/128). Using TileLang, we develop a highly optimized sparse decoding kernel that achieves near-theoretical speedups of up to 9x over FlashAttention-3 on H100 GPU at 90% sparsity. Code is available at: https://github.com/microsoft/SeerAttention.
Rectified Sparse Attention
Jun 05, 2025Efficient long-sequence generation is a critical challenge for Large Language Models. While recent sparse decoding methods improve efficiency, they suffer from KV cache misalignment, where approximation errors accumulate and degrade generation quality. In this work, we propose Rectified Sparse Attention (ReSA), a simple yet effective method that combines block-sparse attention with periodic dense rectification. By refreshing the KV cache at fixed intervals using a dense forward pass, ReSA bounds error accumulation and preserves alignment with the pretraining distribution. Experiments across math reasoning, language modeling, and retrieval tasks demonstrate that ReSA achieves near-lossless generation quality with significantly improved efficiency. Notably, ReSA delivers up to 2.42$\times$ end-to-end speedup under decoding at 256K sequence length, making it a practical solution for scalable long-context inference. Code is available at https://aka.ms/ReSA-LM.
TileLang: A Composable Tiled Programming Model for AI Systems
Apr 24, 2025Modern AI workloads rely heavily on optimized computing kernels for both training and inference. These AI kernels follow well-defined data-flow patterns, such as moving tiles between DRAM and SRAM and performing a sequence of computations on those tiles. However, writing high-performance kernels remains complex despite the clarity of these patterns. Achieving peak performance requires careful, hardware-centric optimizations to fully leverage modern accelerators. While domain-specific compilers attempt to reduce the burden of writing high-performance kernels, they often struggle with usability and expressiveness gaps. In this paper, we present TileLang, a generalized tiled programming model for more efficient AI Kernel programming. TileLang decouples scheduling space (thread binding, layout, tensorize and pipeline) from dataflow, and encapsulated them as a set of customization annotations and primitives. This approach allows users to focus on the kernel's data-flow itself, while leaving most other optimizations to compilers. We conduct comprehensive experiments on commonly-used devices, across numerous experiments, our evaluation shows that TileLang can achieve state-of-the-art performance in key kernels, demonstrating that its unified block-and-thread paradigm and transparent scheduling capabilities deliver both the power and flexibility demanded by modern AI system development.
AttentionEngine: A Versatile Framework for Efficient Attention Mechanisms on Diverse Hardware Platforms
Feb 21, 2025Transformers and large language models (LLMs) have revolutionized machine learning, with attention mechanisms at the core of their success. As the landscape of attention variants expands, so too do the challenges of optimizing their performance, particularly across different hardware platforms. Current optimization strategies are often narrowly focused, requiring extensive manual intervention to accommodate changes in model configurations or hardware environments. In this paper, we introduce AttentionEngine, a comprehensive framework designed to streamline the optimization of attention mechanisms across heterogeneous hardware backends. By decomposing attention computation into modular operations with customizable components, AttentionEngine enables flexible adaptation to diverse algorithmic requirements. The framework further automates kernel optimization through a combination of programmable templates and a robust cross-platform scheduling strategy. Empirical results reveal performance gains of up to 10x on configurations beyond the reach of existing methods. AttentionEngine offers a scalable, efficient foundation for developing and deploying attention mechanisms with minimal manual tuning. Our code has been open-sourced and is available at https://github.com/microsoft/AttentionEngine.
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Jan 23, 2025



We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data. DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators. Specifically, we (1) conduct extensive experiments that demonstrate the model's varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model's representation capacity with minimal impacts on the inference speed. Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios. We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models. In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
Differential Transformer
Oct 07, 2024



Transformer tends to overallocate attention to irrelevant context. In this work, we introduce Diff Transformer, which amplifies attention to the relevant context while canceling noise. Specifically, the differential attention mechanism calculates attention scores as the difference between two separate softmax attention maps. The subtraction cancels noise, promoting the emergence of sparse attention patterns. Experimental results on language modeling show that Diff Transformer outperforms Transformer in various settings of scaling up model size and training tokens. More intriguingly, it offers notable advantages in practical applications, such as long-context modeling, key information retrieval, hallucination mitigation, in-context learning, and reduction of activation outliers. By being less distracted by irrelevant context, Diff Transformer can mitigate hallucination in question answering and text summarization. For in-context learning, Diff Transformer not only enhances accuracy but is also more robust to order permutation, which was considered as a chronic robustness issue. The results position Diff Transformer as a highly effective and promising architecture to advance large language models.
Retentive Network: A Successor to Transformer for Large Language Models
Aug 09, 2023In this work, we propose Retentive Network (RetNet) as a foundation architecture for large language models, simultaneously achieving training parallelism, low-cost inference, and good performance. We theoretically derive the connection between recurrence and attention. Then we propose the retention mechanism for sequence modeling, which supports three computation paradigms, i.e., parallel, recurrent, and chunkwise recurrent. Specifically, the parallel representation allows for training parallelism. The recurrent representation enables low-cost $O(1)$ inference, which improves decoding throughput, latency, and GPU memory without sacrificing performance. The chunkwise recurrent representation facilitates efficient long-sequence modeling with linear complexity, where each chunk is encoded parallelly while recurrently summarizing the chunks. Experimental results on language modeling show that RetNet achieves favorable scaling results, parallel training, low-cost deployment, and efficient inference. The intriguing properties make RetNet a strong successor to Transformer for large language models. Code will be available at https://aka.ms/retnet.
A Neural Corpus Indexer for Document Retrieval
Jun 06, 2022
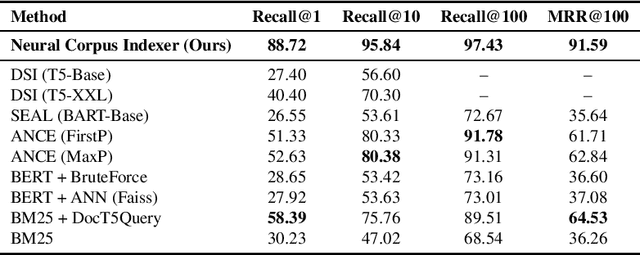
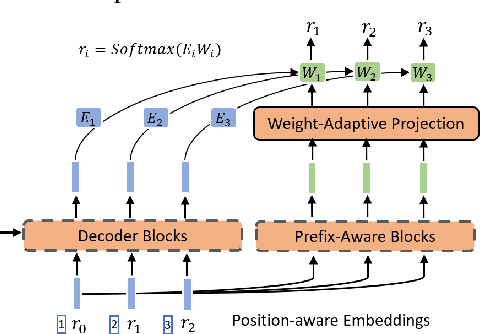
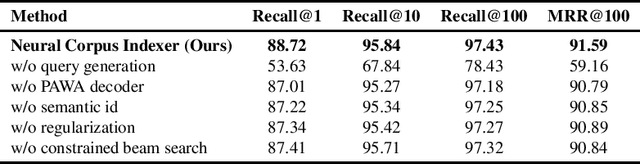
Current state-of-the-art document retrieval solutions mainly follow an index-retrieve paradigm, where the index is hard to be optimized for the final retrieval target. In this paper, we aim to show that an end-to-end deep neural network unifying training and indexing stages can significantly improve the recall performance of traditional methods. To this end, we propose Neural Corpus Indexer (NCI), a sequence-to-sequence network that generates relevant document identifiers directly for a designated query. To optimize the recall performance of NCI, we invent a prefix-aware weight-adaptive decoder architecture, and leverage tailored techniques including query generation, semantic document identifiers and consistency-based regularization. Empirical studies demonstrated the superiority of NCI on a commonly used academic benchmark, achieving +51.9% relative improvement on NQ320k dataset compared to the best baseline.
Manifold Fitting under Unbounded Noise
Sep 23, 2019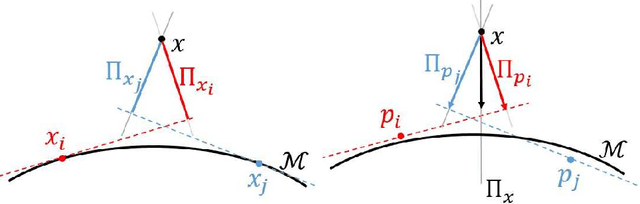
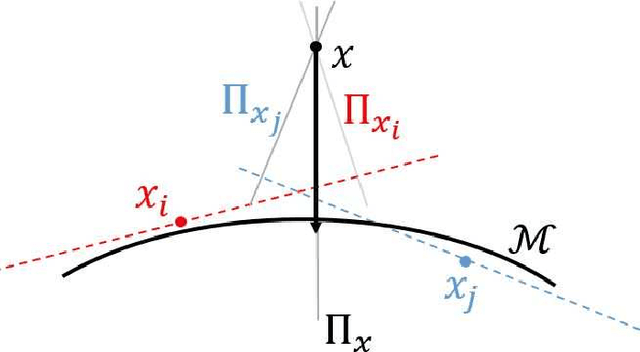
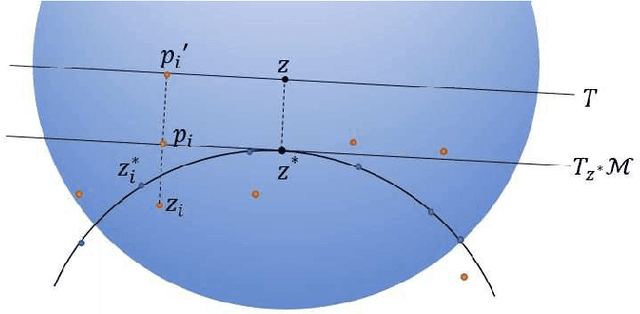

There has been an emerging trend in non-Euclidean dimension reduction of aiming to recover a low dimensional structure, namely a manifold, underlying the high dimensional data. Recovering the manifold requires the noise to be of certain concentration. Existing methods address this problem by constructing an output manifold based on the tangent space estimation at each sample point. Although theoretical convergence for these methods is guaranteed, either the samples are noiseless or the noise is bounded. However, if the noise is unbounded, which is a common scenario, the tangent space estimation of the noisy samples will be blurred, thereby breaking the manifold fitting. In this paper, we introduce a new manifold-fitting method, by which the output manifold is constructed by directly estimating the tangent spaces at the projected points on the underlying manifold, rather than at the sample points, to decrease the error caused by the noise. Our new method provides theoretical convergence, in terms of the upper bound on the Hausdorff distance between the output and underlying manifold and the lower bound on the reach of the output manifold, when the noise is unbounded. Numerical simulations are provided to validate our theoretical findings and demonstrate the advantages of our method over other relevant methods. Finally, our method is applied to real data examples.
Minimal Sample Subspace Learning: Theory and Algorithms
Jul 13, 2019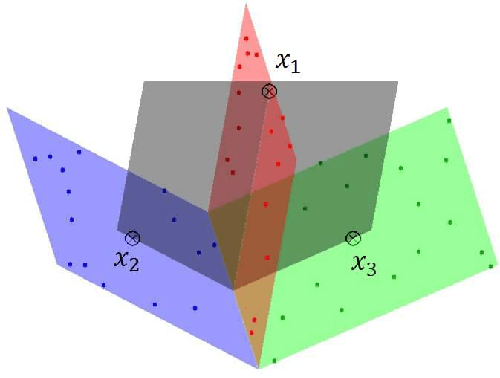
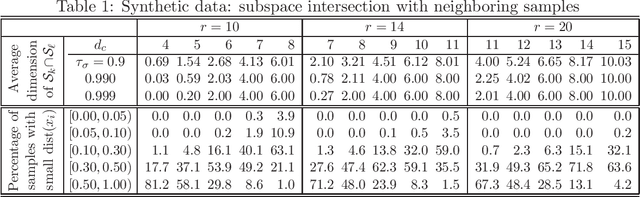

Subspace segmentation or subspace learning is a challenging and complicated task in machine learning. This paper builds a primary frame and solid theoretical bases for the minimal subspace segmentation (MSS) of finite samples. Existence and conditional uniqueness of MSS are discussed with conditions generally satisfied in applications. Utilizing weak prior information of MSS, the minimality inspection of segments is further simplified to the prior detection of partitions. The MSS problem is then modeled as a computable optimization problem via self-expressiveness of samples. A closed form of representation matrices is first given for the self-expressiveness, and the connection of diagonal blocks is then addressed. The MSS model uses a rank restriction on the sum of segment ranks. Theoretically, it can retrieve the minimal sample subspaces that could be heavily intersected. The optimization problem is solved via a basic manifold conjugate gradient algorithm, alternative optimization and hybrid optimization, taking into account of solving both the primal MSS problem and its pseudo-dual problem. The MSS model is further modified for handling noisy data, and solved by an ADMM algorithm. The reported experiments show the strong ability of the MSS method on retrieving minimal sample subspaces that are heavily intersected.