 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Data Difficulty: Improving Coding Models via Reinforcement Learning on Fresh and Challenging Problems
Mar 08, 2026Training next-generation code generation models requires high-quality datasets, yet existing datasets face difficulty imbalance, format inconsistency, and data quality problems. We address these challenges through systematic data processing and difficulty scaling. We introduce a four-stage Data Processing Framework encompassing collection, processing, filtering, and verification, incorporating Automatic Difficulty Filtering via an LLM-based predict-calibrate-select framework that leverages multi-dimensional difficulty metrics across five weighted dimensions to retain challenging problems while removing simplistic ones. The resulting MicroCoder dataset comprises tens of thousands of curated real competitive programming problems from diverse platforms, emphasizing recency and difficulty. Evaluations on strictly unseen LiveCodeBench demonstrate that MicroCoder achieves 3x larger performance gains within 300 training steps compared to widely-used baseline datasets of comparable size, with consistent advantages under both GRPO and its variant training algorithms. The MicroCoder dataset delivers obvious improvements on medium and hard problems across different model sizes, achieving up to 17.2% relative gains in overall performance where model capabilities are most stretched. These results validate that difficulty-aware data curation improves model performance on challenging tasks, providing multiple insights for dataset creation in code generation.
Closing the Loop: Universal Repository Representation with RPG-Encoder
Feb 03, 2026Current repository agents encounter a reasoning disconnect due to fragmented representations, as existing methods rely on isolated API documentation or dependency graphs that lack semantic depth. We consider repository comprehension and generation to be inverse processes within a unified cycle: generation expands intent into implementation, while comprehension compresses implementation back into intent. To address this, we propose RPG-Encoder, a framework that generalizes the Repository Planning Graph (RPG) from a static generative blueprint into a unified, high-fidelity representation. RPG-Encoder closes the reasoning loop through three mechanisms: (1) Encoding raw code into the RPG that combines lifted semantic features with code dependencies; (2) Evolving the topology incrementally to decouple maintenance costs from repository scale, reducing overhead by 95.7%; and (3) Operating as a unified interface for structure-aware navigation. In evaluations, RPG-Encoder establishes state-of-the-art localization performance on SWE-bench Verified with 93.7% Acc@5 and exceeds the best baseline by over 10% in localization accuracy on SWE-bench Live Lite. These results highlight our superior fine-grained precision in complex codebases. Furthermore, it achieves 98.5% reconstruction coverage on RepoCraft, confirming RPG's high-fidelity capacity to mirror the original codebase and closing the loop between intent and implementation.
RPG: A Repository Planning Graph for Unified and Scalable Codebase Generation
Sep 19, 2025



Large language models excel at function- and file-level code generation, yet generating complete repositories from scratch remains a fundamental challenge. This process demands coherent and reliable planning across proposal- and implementation-level stages, while natural language, due to its ambiguity and verbosity, is ill-suited for faithfully representing complex software structures. To address this, we introduce the Repository Planning Graph (RPG), a persistent representation that unifies proposal- and implementation-level planning by encoding capabilities, file structures, data flows, and functions in one graph. RPG replaces ambiguous natural language with an explicit blueprint, enabling long-horizon planning and scalable repository generation. Building on RPG, we develop ZeroRepo, a graph-driven framework for repository generation from scratch. It operates in three stages: proposal-level planning and implementation-level refinement to construct the graph, followed by graph-guided code generation with test validation. To evaluate this setting, we construct RepoCraft, a benchmark of six real-world projects with 1,052 tasks. On RepoCraft, ZeroRepo produces repositories averaging nearly 36K LOC, roughly 3.9$\times$ the strongest baseline (Claude Code) and about 64$\times$ other baselines. It attains 81.5% functional coverage and a 69.7% pass rate, exceeding Claude Code by 27.3 and 35.8 percentage points, respectively. Further analysis shows that RPG models complex dependencies, enables progressively more sophisticated planning through near-linear scaling, and enhances LLM understanding of repositories, thereby accelerating agent localization.
rStar2-Agent: Agentic Reasoning Technical Report
Aug 28, 2025We introduce rStar2-Agent, a 14B math reasoning model trained with agentic reinforcement learning to achieve frontier-level performance. Beyond current long CoT, the model demonstrates advanced cognitive behaviors, such as thinking carefully before using Python coding tools and reflecting on code execution feedback to autonomously explore, verify, and refine intermediate steps in complex problem-solving. This capability is enabled through three key innovations that makes agentic RL effective at scale: (i) an efficient RL infrastructure with a reliable Python code environment that supports high-throughput execution and mitigates the high rollout costs, enabling training on limited GPU resources (64 MI300X GPUs); (ii) GRPO-RoC, an agentic RL algorithm with a Resample-on-Correct rollout strategy that addresses the inherent environment noises from coding tools, allowing the model to reason more effectively in a code environment; (iii) An efficient agent training recipe that starts with non-reasoning SFT and progresses through multi-RL stages, yielding advanced cognitive abilities with minimal compute cost. To this end, rStar2-Agent boosts a pre-trained 14B model to state of the art in only 510 RL steps within one week, achieving average pass@1 scores of 80.6% on AIME24 and 69.8% on AIME25, surpassing DeepSeek-R1 (671B) with significantly shorter responses. Beyond mathematics, rStar2-Agent-14B also demonstrates strong generalization to alignment, scientific reasoning, and agentic tool-use tasks. Code and training recipes are available at https://github.com/microsoft/rStar.
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Jan 23, 2025



We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data. DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators. Specifically, we (1) conduct extensive experiments that demonstrate the model's varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model's representation capacity with minimal impacts on the inference speed. Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios. We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models. In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
EpiCoder: Encompassing Diversity and Complexity in Code Generation
Jan 08, 2025Effective instruction tuning is indispensable for optimizing code LLMs, aligning model behavior with user expectations and enhancing model performance in real-world applications. However, most existing methods focus on code snippets, which are limited to specific functionalities and rigid structures, restricting the complexity and diversity of the synthesized data. To address these limitations, we introduce a novel feature tree-based synthesis framework inspired by Abstract Syntax Trees (AST). Unlike AST, which captures syntactic structure of code, our framework models semantic relationships between code elements, enabling the generation of more nuanced and diverse data. The feature tree is constructed from raw data and refined iteratively to increase the quantity and diversity of the extracted features. This process enables the identification of more complex patterns and relationships within the code. By sampling subtrees with controlled depth and breadth, our framework allows precise adjustments to the complexity of the generated code, supporting a wide range of tasks from simple function-level operations to intricate multi-file scenarios. We fine-tuned widely-used base models to create the EpiCoder series, achieving state-of-the-art performance at both the function and file levels across multiple benchmarks. Notably, empirical evidence indicates that our approach shows significant potential in synthesizing highly complex repository-level code data. Further analysis elucidates the merits of this approach by rigorously assessing data complexity and diversity through software engineering principles and LLM-as-a-judge method.
MMLU-CF: A Contamination-free Multi-task Language Understanding Benchmark
Dec 19, 2024



Multiple-choice question (MCQ) datasets like Massive Multitask Language Understanding (MMLU) are widely used to evaluate the commonsense, understanding, and problem-solving abilities of large language models (LLMs). However, the open-source nature of these benchmarks and the broad sources of training data for LLMs have inevitably led to benchmark contamination, resulting in unreliable evaluation results. To alleviate this issue, we propose a contamination-free and more challenging MCQ benchmark called MMLU-CF. This benchmark reassesses LLMs' understanding of world knowledge by averting both unintentional and malicious data leakage. To avoid unintentional data leakage, we source data from a broader domain and design three decontamination rules. To prevent malicious data leakage, we divide the benchmark into validation and test sets with similar difficulty and subject distributions. The test set remains closed-source to ensure reliable results, while the validation set is publicly available to promote transparency and facilitate independent verification. Our evaluation of mainstream LLMs reveals that the powerful GPT-4o achieves merely a 5-shot score of 73.4% and a 0-shot score of 71.9% on the test set, which indicates the effectiveness of our approach in creating a more rigorous and contamination-free evaluation standard. The GitHub repository is available at https://github.com/microsoft/MMLU-CF and the dataset refers to https://huggingface.co/datasets/microsoft/MMLU-CF.
RedStone: Curating General, Code, Math, and QA Data for Large Language Models
Dec 04, 2024
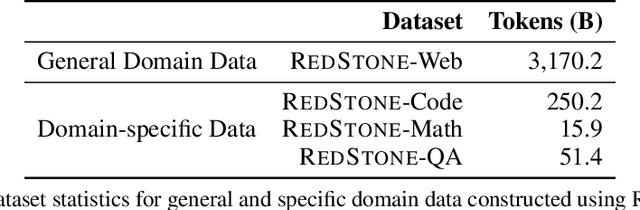
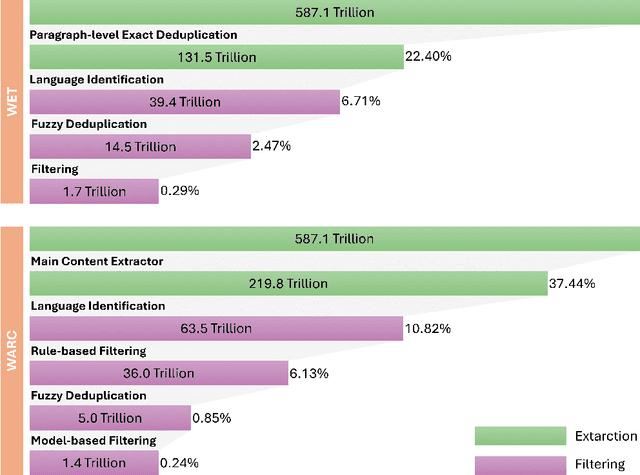
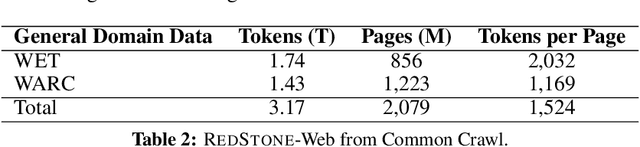
Pre-training Large Language Models (LLMs) on high-quality, meticulously curated datasets is widely recognized as critical for enhancing their performance and generalization capabilities. This study explores the untapped potential of Common Crawl as a comprehensive and flexible resource for pre-training LLMs, addressing both general-purpose language understanding and specialized domain knowledge. We introduce RedStone, an innovative and scalable pipeline engineered to extract and process data from Common Crawl, facilitating the creation of extensive and varied pre-training datasets. Unlike traditional datasets, which often require expensive curation and domain-specific expertise, RedStone leverages the breadth of Common Crawl to deliver datasets tailored to a wide array of domains. In this work, we exemplify its capability by constructing pre-training datasets across multiple fields, including general language understanding, code, mathematics, and question-answering tasks. The flexibility of RedStone allows for easy adaptation to other specialized domains, significantly lowering the barrier to creating valuable domain-specific datasets. Our findings demonstrate that Common Crawl, when harnessed through effective pipelines like RedStone, can serve as a rich, renewable source of pre-training data, unlocking new avenues for domain adaptation and knowledge discovery in LLMs. This work also underscores the importance of innovative data acquisition strategies and highlights the role of web-scale data as a powerful resource in the continued evolution of LLMs. RedStone code and data samples will be publicly available at \url{https://aka.ms/redstone}.
Context Autoencoder for Self-Supervised Representation Learning
Feb 07, 2022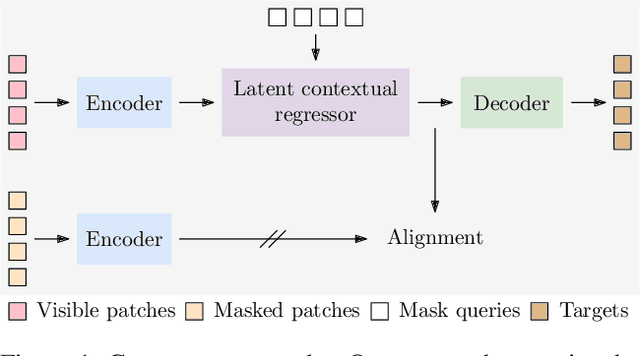
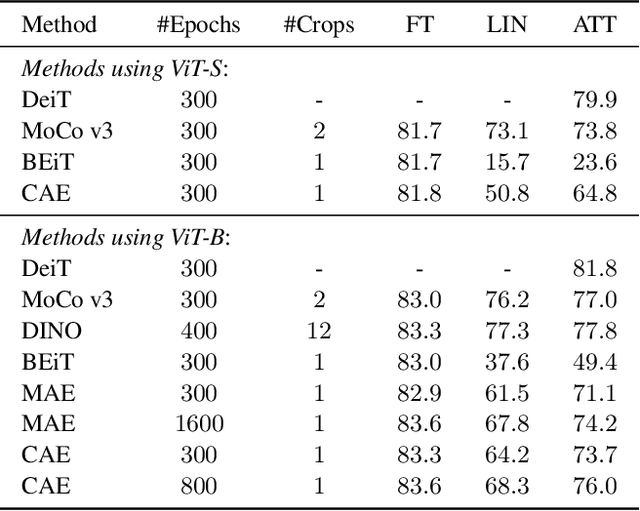


We present a novel masked image modeling (MIM) approach, context autoencoder (CAE), for self-supervised learning. We randomly partition the image into two sets: visible patches and masked patches. The CAE architecture consists of: (i) an encoder that takes visible patches as input and outputs their latent representations, (ii) a latent context regressor that predicts the masked patch representations from the visible patch representations that are not updated in this regressor, (iii) a decoder that takes the estimated masked patch representations as input and makes predictions for the masked patches, and (iv) an alignment module that aligns the masked patch representation estimation with the masked patch representations computed from the encoder. In comparison to previous MIM methods that couple the encoding and decoding roles, e.g., using a single module in BEiT, our approach attempts to~\emph{separate the encoding role (content understanding) from the decoding role (making predictions for masked patches)} using different modules, improving the content understanding capability. In addition, our approach makes predictions from the visible patches to the masked patches in \emph{the latent representation space} that is expected to take on semantics. In addition, we present the explanations about why contrastive pretraining and supervised pretraining perform similarly and why MIM potentially performs better. We demonstrate the effectiveness of our CAE through superior transfer performance in downstream tasks: semantic segmentation, and object detection and instance segmentation.
PAFNet: An Efficient Anchor-Free Object Detector Guidance
Apr 28, 2021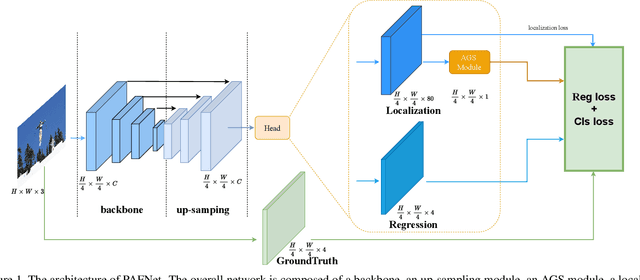
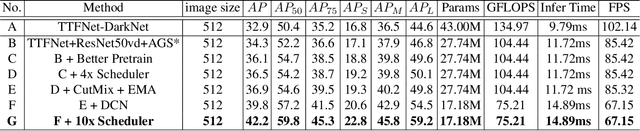
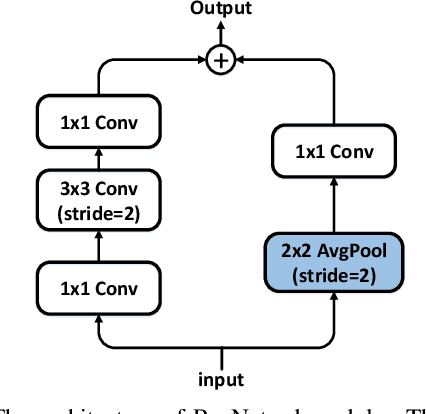

Object detection is a basic but challenging task in computer vision, which plays a key role in a variety of industrial applications. However, object detectors based on deep learning usually require greater storage requirements and longer inference time, which hinders its practicality seriously. Therefore, a trade-off between effectiveness and efficiency is necessary in practical scenarios. Considering that without constraint of pre-defined anchors, anchor-free detectors can achieve acceptable accuracy and inference speed simultaneously. In this paper, we start from an anchor-free detector called TTFNet, modify the structure of TTFNet and introduce multiple existing tricks to realize effective server and mobile solutions respectively. Since all experiments in this paper are conducted based on PaddlePaddle, we call the model as PAFNet(Paddle Anchor Free Network). For server side, PAFNet can achieve a better balance between effectiveness (42.2% mAP) and efficiency (67.15 FPS) on a single V100 GPU. For moblie side, PAFNet-lite can achieve a better accuracy of (23.9% mAP) and 26.00 ms on Kirin 990 ARM CPU, outperforming the existing state-of-the-art anchor-free detectors by significant margins. Source code is at https://github.com/PaddlePaddle/PaddleDetection.