 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Data Difficulty: Improving Coding Models via Reinforcement Learning on Fresh and Challenging Problems
Mar 08, 2026Training next-generation code generation models requires high-quality datasets, yet existing datasets face difficulty imbalance, format inconsistency, and data quality problems. We address these challenges through systematic data processing and difficulty scaling. We introduce a four-stage Data Processing Framework encompassing collection, processing, filtering, and verification, incorporating Automatic Difficulty Filtering via an LLM-based predict-calibrate-select framework that leverages multi-dimensional difficulty metrics across five weighted dimensions to retain challenging problems while removing simplistic ones. The resulting MicroCoder dataset comprises tens of thousands of curated real competitive programming problems from diverse platforms, emphasizing recency and difficulty. Evaluations on strictly unseen LiveCodeBench demonstrate that MicroCoder achieves 3x larger performance gains within 300 training steps compared to widely-used baseline datasets of comparable size, with consistent advantages under both GRPO and its variant training algorithms. The MicroCoder dataset delivers obvious improvements on medium and hard problems across different model sizes, achieving up to 17.2% relative gains in overall performance where model capabilities are most stretched. These results validate that difficulty-aware data curation improves model performance on challenging tasks, providing multiple insights for dataset creation in code generation.
MMLU-CF: A Contamination-free Multi-task Language Understanding Benchmark
Dec 19, 2024



Multiple-choice question (MCQ) datasets like Massive Multitask Language Understanding (MMLU) are widely used to evaluate the commonsense, understanding, and problem-solving abilities of large language models (LLMs). However, the open-source nature of these benchmarks and the broad sources of training data for LLMs have inevitably led to benchmark contamination, resulting in unreliable evaluation results. To alleviate this issue, we propose a contamination-free and more challenging MCQ benchmark called MMLU-CF. This benchmark reassesses LLMs' understanding of world knowledge by averting both unintentional and malicious data leakage. To avoid unintentional data leakage, we source data from a broader domain and design three decontamination rules. To prevent malicious data leakage, we divide the benchmark into validation and test sets with similar difficulty and subject distributions. The test set remains closed-source to ensure reliable results, while the validation set is publicly available to promote transparency and facilitate independent verification. Our evaluation of mainstream LLMs reveals that the powerful GPT-4o achieves merely a 5-shot score of 73.4% and a 0-shot score of 71.9% on the test set, which indicates the effectiveness of our approach in creating a more rigorous and contamination-free evaluation standard. The GitHub repository is available at https://github.com/microsoft/MMLU-CF and the dataset refers to https://huggingface.co/datasets/microsoft/MMLU-CF.
RedStone: Curating General, Code, Math, and QA Data for Large Language Models
Dec 04, 2024
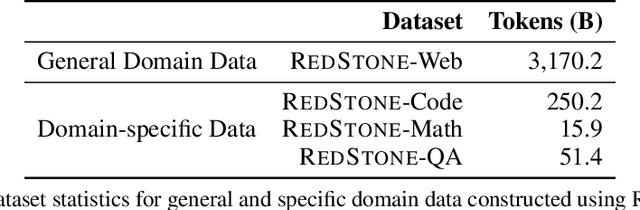
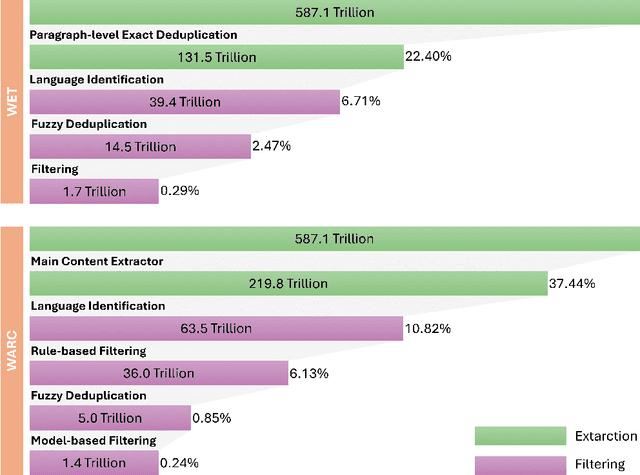
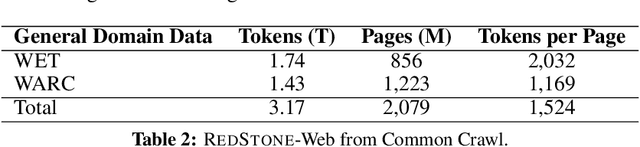
Pre-training Large Language Models (LLMs) on high-quality, meticulously curated datasets is widely recognized as critical for enhancing their performance and generalization capabilities. This study explores the untapped potential of Common Crawl as a comprehensive and flexible resource for pre-training LLMs, addressing both general-purpose language understanding and specialized domain knowledge. We introduce RedStone, an innovative and scalable pipeline engineered to extract and process data from Common Crawl, facilitating the creation of extensive and varied pre-training datasets. Unlike traditional datasets, which often require expensive curation and domain-specific expertise, RedStone leverages the breadth of Common Crawl to deliver datasets tailored to a wide array of domains. In this work, we exemplify its capability by constructing pre-training datasets across multiple fields, including general language understanding, code, mathematics, and question-answering tasks. The flexibility of RedStone allows for easy adaptation to other specialized domains, significantly lowering the barrier to creating valuable domain-specific datasets. Our findings demonstrate that Common Crawl, when harnessed through effective pipelines like RedStone, can serve as a rich, renewable source of pre-training data, unlocking new avenues for domain adaptation and knowledge discovery in LLMs. This work also underscores the importance of innovative data acquisition strategies and highlights the role of web-scale data as a powerful resource in the continued evolution of LLMs. RedStone code and data samples will be publicly available at \url{https://aka.ms/redstone}.
WaveCoder: Widespread And Versatile Enhanced Instruction Tuning with Refined Data Generation
Jan 11, 2024Recent work demonstrates that, after being fine-tuned on a high-quality instruction dataset, the resulting model can obtain impressive capabilities to address a wide range of tasks. However, existing methods for instruction data generation often produce duplicate data and are not controllable enough on data quality. In this paper, we extend the generalization of instruction tuning by classifying the instruction data to 4 code-related tasks and propose a LLM-based Generator-Discriminator data process framework to generate diverse, high-quality instruction data from open source code. Hence, we introduce CodeOcean, a dataset comprising 20,000 instruction instances across 4 universal code-related tasks,which is aimed at augmenting the effectiveness of instruction tuning and improving the generalization ability of fine-tuned model. Subsequently, we present WaveCoder, a fine-tuned Code LLM with Widespread And Versatile Enhanced instruction tuning. This model is specifically designed for enhancing instruction tuning of Code Language Models (LLMs). Our experiments demonstrate that Wavecoder models outperform other open-source models in terms of generalization ability across different code-related tasks at the same level of fine-tuning scale. Moreover, Wavecoder exhibits high efficiency in previous code generation tasks. This paper thus offers a significant contribution to the field of instruction data generation and fine-tuning models, providing new insights and tools for enhancing performance in code-related tasks.