 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEN-VL: A Visual Ensemble MoE Framework for Effective and Efficient Multi-Modal Understanding
May 25, 2026Despite the remarkable progress achieved by recent efficient methods in accelerating multimodal understanding, they still suffer from noticeable performance degradation. Their emphasis on the high compression ratio of a single visual clue and reliance on the heuristic pruning strategy with coarse attention alignment incurs a bottleneck on the information capacity and density of visual tokens. Addressing this limitation, we propose VEN-VL, a visual ensemble MoE framework for effective and efficient perception following the enrich then compact principle. Specifically, we first enrich the information capacity by unifying the visual representations of different perspectives, and then progressively compact it with adaptive routers in specialized visual experts to enhance the information density. Furthermore, we incorporate the reconstruction ability of vanilla structure via explicit visual supervision, facilitating crucial information preservation. Experimental results demonstrate our superiority in complex visual tasks with few information-condensed tokens, which effectively bridges the gap between performance and efficiency.
AlphaResearch: Accelerating New Algorithm Discovery with Language Models
Nov 11, 2025Large language models have made significant progress in complex but easy-to-verify problems, yet they still struggle with discovering the unknown. In this paper, we present \textbf{AlphaResearch}, an autonomous research agent designed to discover new algorithms on open-ended problems. To synergize the feasibility and innovation of the discovery process, we construct a novel dual research environment by combining the execution-based verify and simulated real-world peer review environment. AlphaResearch discovers new algorithm by iteratively running the following steps: (1) propose new ideas (2) verify the ideas in the dual research environment (3) optimize the research proposals for better performance. To promote a transparent evaluation process, we construct \textbf{AlphaResearchComp}, a new evaluation benchmark that includes an eight open-ended algorithmic problems competition, with each problem carefully curated and verified through executable pipelines, objective metrics, and reproducibility checks. AlphaResearch gets a 2/8 win rate in head-to-head comparison with human researchers, demonstrate the possibility of accelerating algorithm discovery with LLMs. Notably, the algorithm discovered by AlphaResearch on the \emph{``packing circles''} problem achieves the best-of-known performance, surpassing the results of human researchers and strong baselines from recent work (e.g., AlphaEvolve). Additionally, we conduct a comprehensive analysis of the remaining challenges of the 6/8 failure cases, providing valuable insights for future research.
Z1: Efficient Test-time Scaling with Code
Apr 01, 2025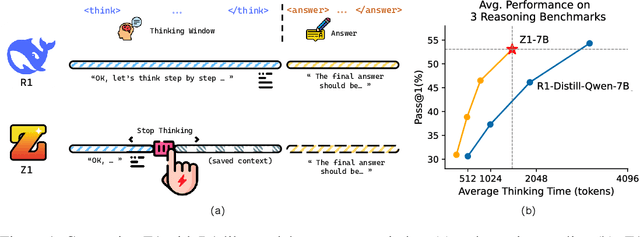
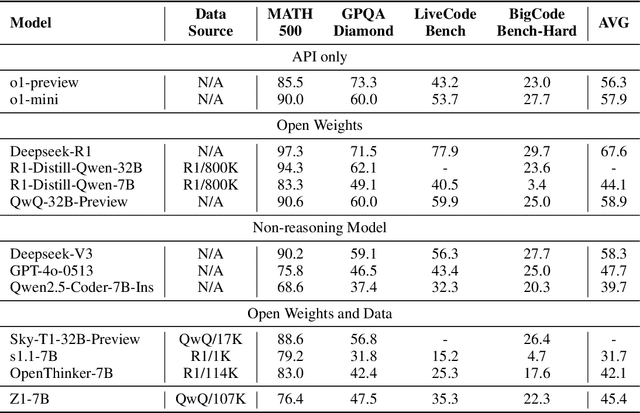

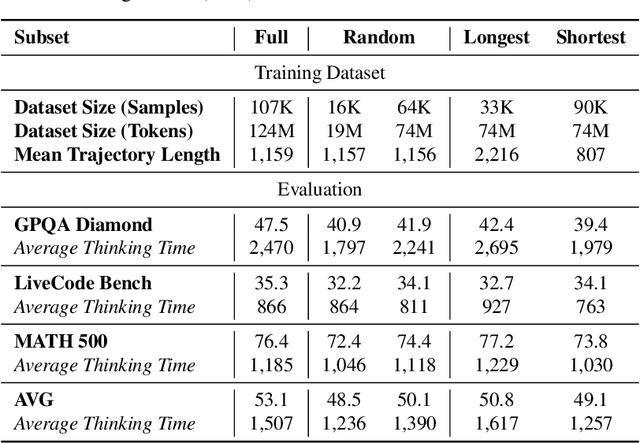
Large Language Models (LLMs) can achieve enhanced complex problem-solving through test-time computing scaling, yet this often entails longer contexts and numerous reasoning token costs. In this paper, we propose an efficient test-time scaling method that trains LLMs on code-related reasoning trajectories, facilitating their reduction of excess thinking tokens while maintaining performance. First, we create Z1-Code-Reasoning-107K, a curated dataset of simple and complex coding problems paired with their short and long solution trajectories. Second, we present a novel Shifted Thinking Window to mitigate overthinking overhead by removing context-delimiting tags (e.g., <think>. . . </think>) and capping reasoning tokens. Trained with long and short trajectory data and equipped with Shifted Thinking Window, our model, Z1-7B, demonstrates the ability to adjust its reasoning level as the complexity of problems and exhibits efficient test-time scaling across different reasoning tasks that matches R1-Distill-Qwen-7B performance with about 30% of its average thinking tokens. Notably, fine-tuned with only code trajectories, Z1-7B demonstrates generalization to broader reasoning tasks (47.5% on GPQA Diamond). Our analysis of efficient reasoning elicitation also provides valuable insights for future research.
HumanEval Pro and MBPP Pro: Evaluating Large Language Models on Self-invoking Code Generation
Dec 30, 2024We introduce self-invoking code generation, a new task designed to evaluate the progressive reasoning and problem-solving capabilities of LLMs. In this task, models are presented with a base problem and a related, more complex problem. They must solve the base problem and then utilize its solution to address the more complex one. This work features three key contributions. First, we propose a general recipe for generating more challenging versions of existing benchmarks, resulting in three new benchmarks: HumanEval Pro, MBPP Pro, and BigCodeBench-Lite Pro, specifically designed to assess LLMs on self-invoking code generation. Second, from the analysis of experimental results over twenty LLMs on our benchmarks, we have two important observations: (i) Most LLMs excel in traditional code generation benchmarks like HumanEval and MBPP, but their performance declines on self-invoking tasks. For example, o1-mini achieves 96.2% pass@1 on HumanEval but only 76.2% on HumanEval Pro. (ii) On self-invoking code generation task, the instruction-tuned models demonstrate only marginal improvements compared to the base models. Third, we disclose the types of failure modes that exist in our evaluation results. All these results underscore the need for further advancements in self-invoking code generation tasks and provide a new direction for future research on enhancing LLMs' code reasoning capabilities.
OpenCarbonEval: A Unified Carbon Emission Estimation Framework in Large-Scale AI Models
May 21, 2024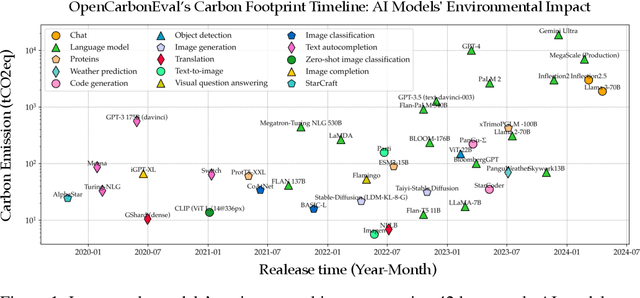
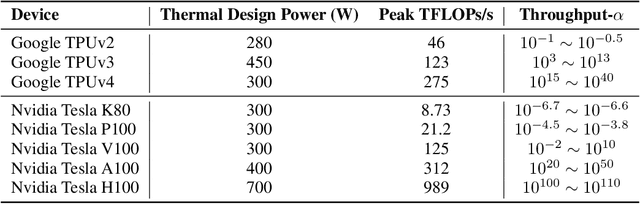
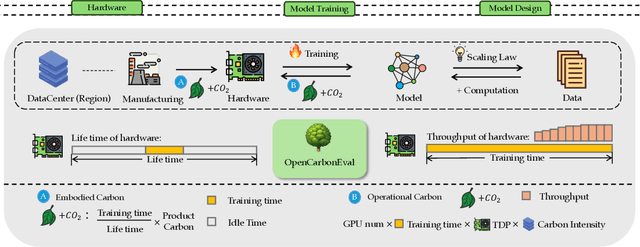
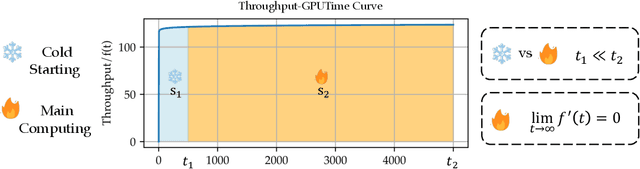
In recent years, large-scale auto-regressive models have made significant progress in various tasks, such as text or video generation. However, the environmental impact of these models has been largely overlooked, with a lack of assessment and analysis of their carbon footprint. To address this gap, we introduce OpenCarbonEval, a unified framework for integrating large-scale models across diverse modalities to predict carbon emissions, which could provide AI service providers and users with a means to estimate emissions beforehand and help mitigate the environmental pressure associated with these models. In OpenCarbonEval, we propose a dynamic throughput modeling approach that could capture workload and hardware fluctuations in the training process for more precise emissions estimates. Our evaluation results demonstrate that OpenCarbonEval can more accurately predict training emissions than previous methods, and can be seamlessly applied to different modal tasks. Specifically, we show that OpenCarbonEval achieves superior performance in predicting carbon emissions for both visual models and language models. By promoting sustainable AI development and deployment, OpenCarbonEval can help reduce the environmental impact of large-scale models and contribute to a more environmentally responsible future for the AI community.
WaveCoder: Widespread And Versatile Enhanced Instruction Tuning with Refined Data Generation
Jan 11, 2024Recent work demonstrates that, after being fine-tuned on a high-quality instruction dataset, the resulting model can obtain impressive capabilities to address a wide range of tasks. However, existing methods for instruction data generation often produce duplicate data and are not controllable enough on data quality. In this paper, we extend the generalization of instruction tuning by classifying the instruction data to 4 code-related tasks and propose a LLM-based Generator-Discriminator data process framework to generate diverse, high-quality instruction data from open source code. Hence, we introduce CodeOcean, a dataset comprising 20,000 instruction instances across 4 universal code-related tasks,which is aimed at augmenting the effectiveness of instruction tuning and improving the generalization ability of fine-tuned model. Subsequently, we present WaveCoder, a fine-tuned Code LLM with Widespread And Versatile Enhanced instruction tuning. This model is specifically designed for enhancing instruction tuning of Code Language Models (LLMs). Our experiments demonstrate that Wavecoder models outperform other open-source models in terms of generalization ability across different code-related tasks at the same level of fine-tuning scale. Moreover, Wavecoder exhibits high efficiency in previous code generation tasks. This paper thus offers a significant contribution to the field of instruction data generation and fine-tuning models, providing new insights and tools for enhancing performance in code-related tasks.