 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZ1: Efficient Test-time Scaling with Code
Apr 01, 2025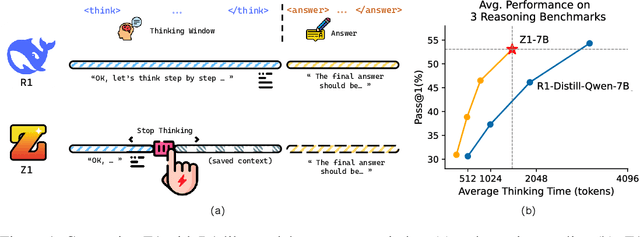
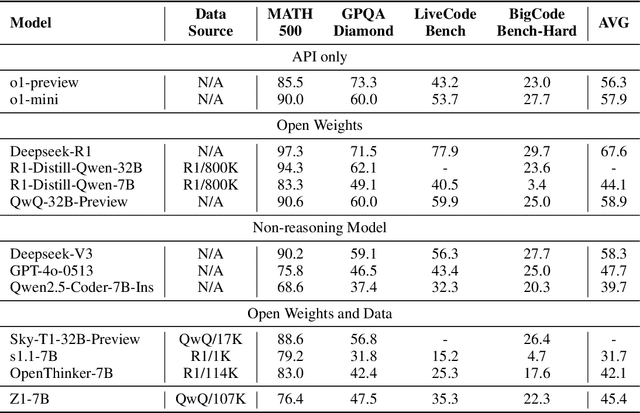

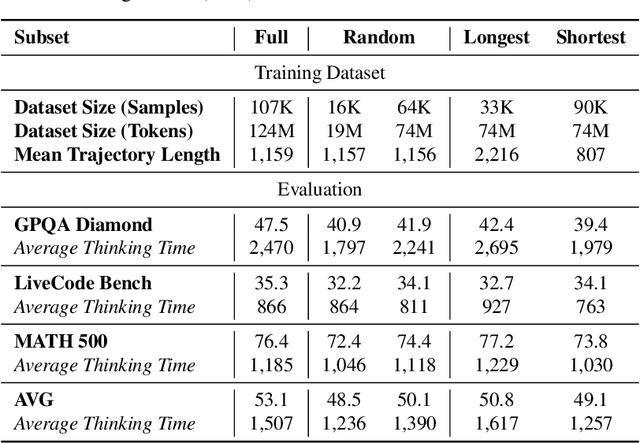
Large Language Models (LLMs) can achieve enhanced complex problem-solving through test-time computing scaling, yet this often entails longer contexts and numerous reasoning token costs. In this paper, we propose an efficient test-time scaling method that trains LLMs on code-related reasoning trajectories, facilitating their reduction of excess thinking tokens while maintaining performance. First, we create Z1-Code-Reasoning-107K, a curated dataset of simple and complex coding problems paired with their short and long solution trajectories. Second, we present a novel Shifted Thinking Window to mitigate overthinking overhead by removing context-delimiting tags (e.g., <think>. . . </think>) and capping reasoning tokens. Trained with long and short trajectory data and equipped with Shifted Thinking Window, our model, Z1-7B, demonstrates the ability to adjust its reasoning level as the complexity of problems and exhibits efficient test-time scaling across different reasoning tasks that matches R1-Distill-Qwen-7B performance with about 30% of its average thinking tokens. Notably, fine-tuned with only code trajectories, Z1-7B demonstrates generalization to broader reasoning tasks (47.5% on GPQA Diamond). Our analysis of efficient reasoning elicitation also provides valuable insights for future research.
HDC: Hierarchical Semantic Decoding with Counting Assistance for Generalized Referring Expression Segmentation
May 24, 2024



The newly proposed Generalized Referring Expression Segmentation (GRES) amplifies the formulation of classic RES by involving multiple/non-target scenarios. Recent approaches focus on optimizing the last modality-fused feature which is directly utilized for segmentation and object-existence identification. However, the attempt to integrate all-grained information into a single joint representation is impractical in GRES due to the increased complexity of the spatial relationships among instances and deceptive text descriptions. Furthermore, the subsequent binary target justification across all referent scenarios fails to specify their inherent differences, leading to ambiguity in object understanding. To address the weakness, we propose a $\textbf{H}$ierarchical Semantic $\textbf{D}$ecoding with $\textbf{C}$ounting Assistance framework (HDC). It hierarchically transfers complementary modality information across granularities, and then aggregates each well-aligned semantic correspondence for multi-level decoding. Moreover, with complete semantic context modeling, we endow HDC with explicit counting capability to facilitate comprehensive object perception in multiple/single/non-target settings. Experimental results on gRefCOCO, Ref-ZOM, R-RefCOCO, and RefCOCO benchmarks demonstrate the effectiveness and rationality of HDC which outperforms the state-of-the-art GRES methods by a remarkable margin. Code will be available $\href{https://github.com/RobertLuo1/HDC}{here}$.
OpenCarbonEval: A Unified Carbon Emission Estimation Framework in Large-Scale AI Models
May 21, 2024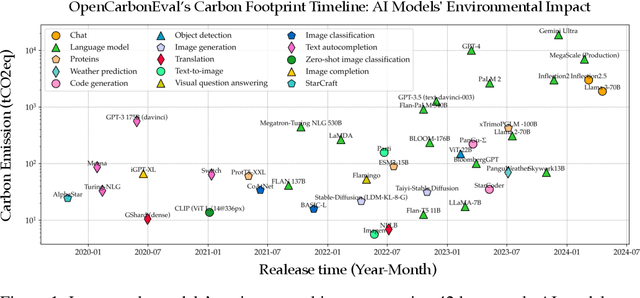
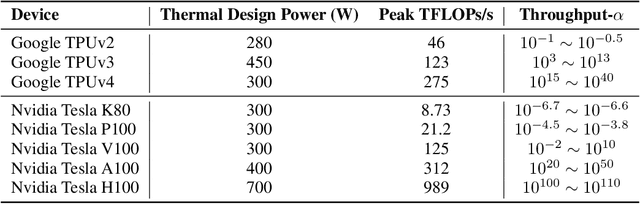
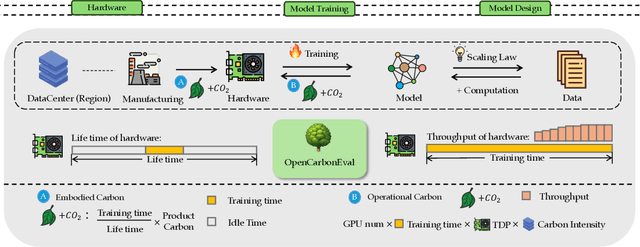
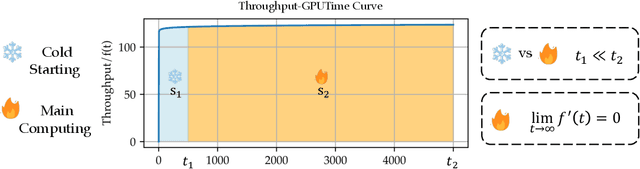
In recent years, large-scale auto-regressive models have made significant progress in various tasks, such as text or video generation. However, the environmental impact of these models has been largely overlooked, with a lack of assessment and analysis of their carbon footprint. To address this gap, we introduce OpenCarbonEval, a unified framework for integrating large-scale models across diverse modalities to predict carbon emissions, which could provide AI service providers and users with a means to estimate emissions beforehand and help mitigate the environmental pressure associated with these models. In OpenCarbonEval, we propose a dynamic throughput modeling approach that could capture workload and hardware fluctuations in the training process for more precise emissions estimates. Our evaluation results demonstrate that OpenCarbonEval can more accurately predict training emissions than previous methods, and can be seamlessly applied to different modal tasks. Specifically, we show that OpenCarbonEval achieves superior performance in predicting carbon emissions for both visual models and language models. By promoting sustainable AI development and deployment, OpenCarbonEval can help reduce the environmental impact of large-scale models and contribute to a more environmentally responsible future for the AI community.
An Effective Index for Truss-based Community Search on Large Directed Graphs
Jan 19, 2024Community search is a derivative of community detection that enables online and personalized discovery of communities and has found extensive applications in massive real-world networks. Recently, there needs to be more focus on the community search issue within directed graphs, even though substantial research has been carried out on undirected graphs. The recently proposed D-truss model has achieved good results in the quality of retrieved communities. However, existing D-truss-based work cannot perform efficient community searches on large graphs because it consumes too many computing resources to retrieve the maximal D-truss. To overcome this issue, we introduce an innovative merge relation known as D-truss-connected to capture the inherent density and cohesiveness of edges within D-truss. This relation allows us to partition all the edges in the original graph into a series of D-truss-connected classes. Then, we construct a concise and compact index, ConDTruss, based on D-truss-connected. Using ConDTruss, the efficiency of maximum D-truss retrieval will be greatly improved, making it a theoretically optimal approach. Experimental evaluations conducted on large directed graph certificate the effectiveness of our proposed method.
Fast Butterfly-Core Community Search For Large Labeled Graphs
Jan 19, 2024Community Search (CS) aims to identify densely interconnected subgraphs corresponding to query vertices within a graph. However, existing heterogeneous graph-based community search methods need help identifying cross-group communities and suffer from efficiency issues, making them unsuitable for large graphs. This paper presents a fast community search model based on the Butterfly-Core Community (BCC) structure for heterogeneous graphs. The Random Walk with Restart (RWR) algorithm and butterfly degree comprehensively evaluate the importance of vertices within communities, allowing leader vertices to be rapidly updated to maintain cross-group cohesion. Moreover, we devised a more efficient method for updating vertex distances, which minimizes vertex visits and enhances operational efficiency. Extensive experiments on several real-world temporal graphs demonstrate the effectiveness and efficiency of this solution.
InFIP: An Explainable DNN Intellectual Property Protection Method based on Intrinsic Features
Oct 14, 2022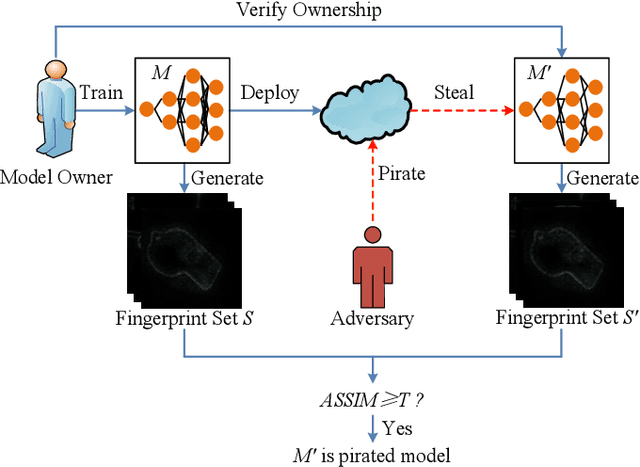
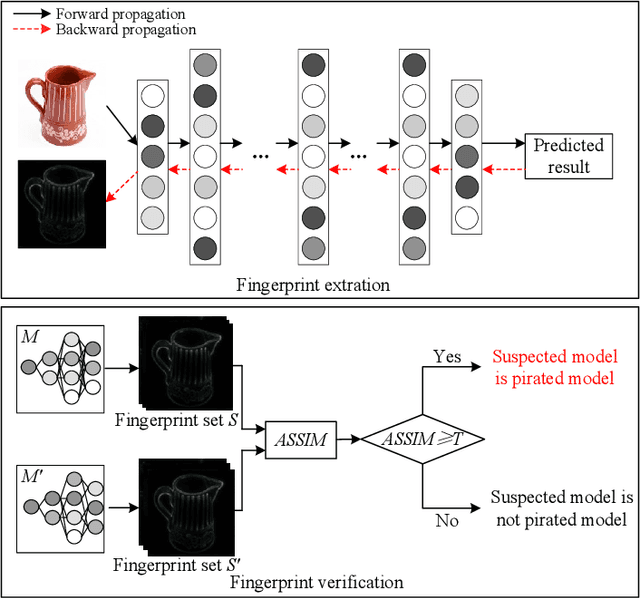
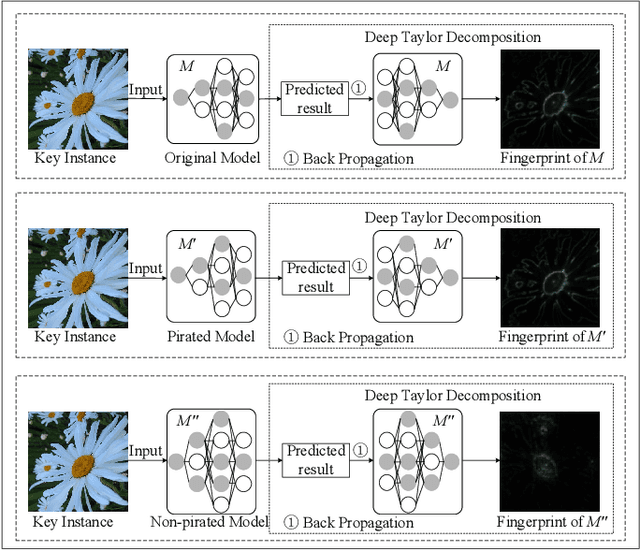

Intellectual property (IP) protection for Deep Neural Networks (DNNs) has raised serious concerns in recent years. Most existing works embed watermarks in the DNN model for IP protection, which need to modify the model and lack of interpretability. In this paper, for the first time, we propose an interpretable intellectual property protection method for DNN based on explainable artificial intelligence. Compared with existing works, the proposed method does not modify the DNN model, and the decision of the ownership verification is interpretable. We extract the intrinsic features of the DNN model by using Deep Taylor Decomposition. Since the intrinsic feature is composed of unique interpretation of the model's decision, the intrinsic feature can be regarded as fingerprint of the model. If the fingerprint of a suspected model is the same as the original model, the suspected model is considered as a pirated model. Experimental results demonstrate that the fingerprints can be successfully used to verify the ownership of the model and the test accuracy of the model is not affected. Furthermore, the proposed method is robust to fine-tuning attack, pruning attack, watermark overwriting attack, and adaptive attack.
Imperceptible and Multi-channel Backdoor Attack against Deep Neural Networks
Jan 31, 2022Recent researches demonstrate that Deep Neural Networks (DNN) models are vulnerable to backdoor attacks. The backdoored DNN model will behave maliciously when images containing backdoor triggers arrive. To date, existing backdoor attacks are single-trigger and single-target attacks, and the triggers of most existing backdoor attacks are obvious thus are easy to be detected or noticed. In this paper, we propose a novel imperceptible and multi-channel backdoor attack against Deep Neural Networks by exploiting Discrete Cosine Transform (DCT) steganography. Based on the proposed backdoor attack method, we implement two variants of backdoor attacks, i.e., N-to-N backdoor attack and N-to-One backdoor attack. Specifically, for a colored image, we utilize DCT steganography to construct the trigger on different channels of the image. As a result, the trigger is stealthy and natural. Based on the proposed method, we implement multi-target and multi-trigger backdoor attacks. Experimental results demonstrate that the average attack success rate of the N-to-N backdoor attack is 93.95% on CIFAR-10 dataset and 91.55% on TinyImageNet dataset, respectively. The average attack success rate of N-to-One attack is 90.22% and 89.53% on CIFAR-10 and TinyImageNet datasets, respectively. Meanwhile, the proposed backdoor attack does not affect the classification accuracy of the DNN model. Moreover, the proposed attack is demonstrated to be robust to the state-of-the-art backdoor defense (Neural Cleanse).
Detecting Backdoor in Deep Neural Networks via Intentional Adversarial Perturbations
Jun 22, 2021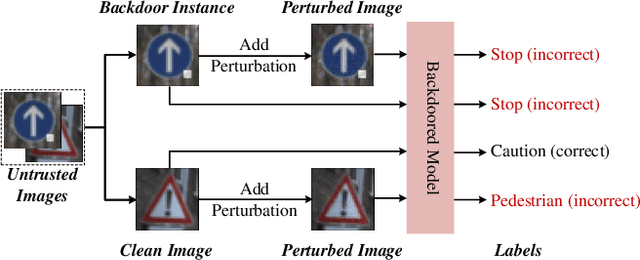



Recent researches show that deep learning model is susceptible to backdoor attacks. Many defenses against backdoor attacks have been proposed. However, existing defense works require high computational overhead or backdoor attack information such as the trigger size, which is difficult to satisfy in realistic scenarios. In this paper, a novel backdoor detection method based on adversarial examples is proposed. The proposed method leverages intentional adversarial perturbations to detect whether an image contains a trigger, which can be applied in both the training stage and the inference stage (sanitize the training set in training stage and detect the backdoor instances in inference stage). Specifically, given an untrusted image, the adversarial perturbation is added to the image intentionally. If the prediction of the model on the perturbed image is consistent with that on the unperturbed image, the input image will be considered as a backdoor instance. Compared with most existing defense works, the proposed adversarial perturbation based method requires low computational resources and maintains the visual quality of the images. Experimental results show that, the backdoor detection rate of the proposed defense method is 99.63%, 99.76% and 99.91% on Fashion-MNIST, CIFAR-10 and GTSRB datasets, respectively. Besides, the proposed method maintains the visual quality of the image as the l2 norm of the added perturbation are as low as 2.8715, 3.0513 and 2.4362 on Fashion-MNIST, CIFAR-10 and GTSRB datasets, respectively. In addition, it is also demonstrated that the proposed method can achieve high defense performance against backdoor attacks under different attack settings (trigger transparency, trigger size and trigger pattern). Compared with the existing defense work (STRIP), the proposed method has better detection performance on all the three datasets, and is more efficient than STRIP.