 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInFIP: An Explainable DNN Intellectual Property Protection Method based on Intrinsic Features
Oct 14, 2022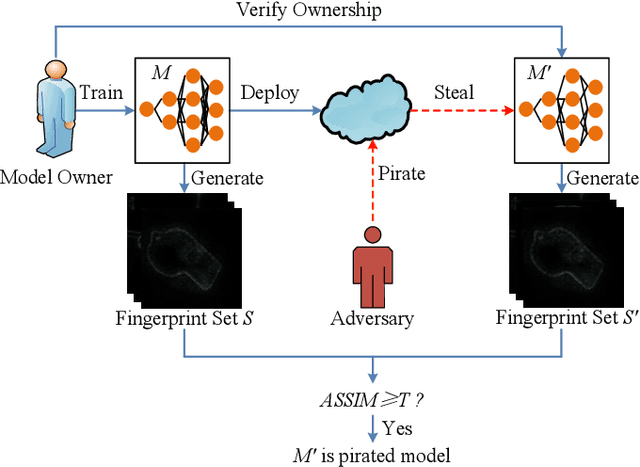
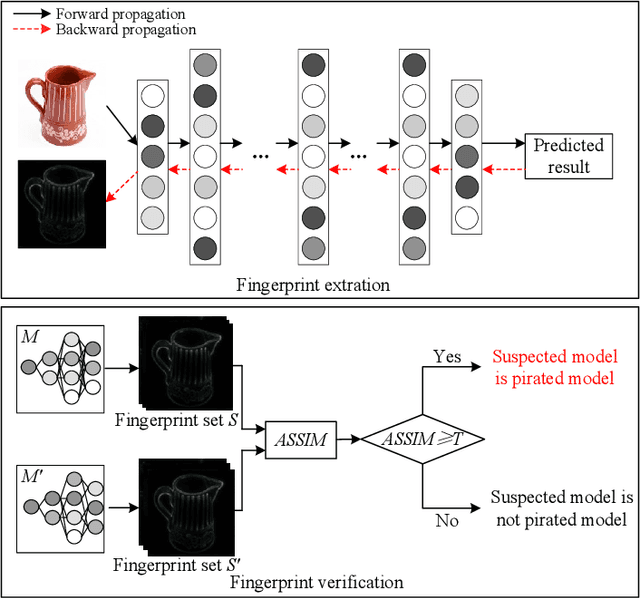
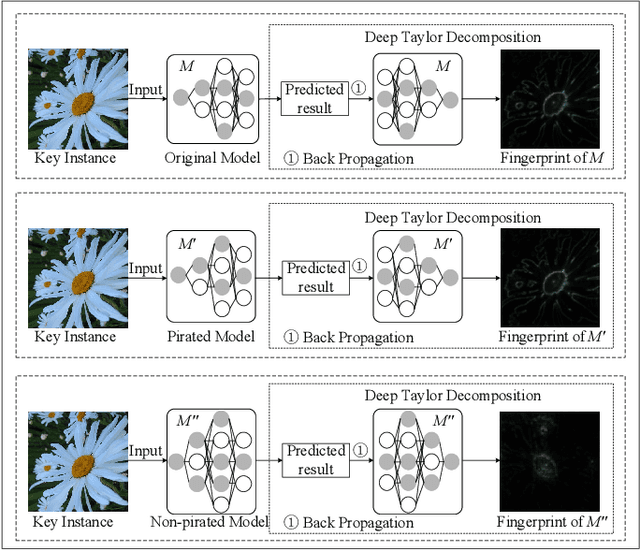

Intellectual property (IP) protection for Deep Neural Networks (DNNs) has raised serious concerns in recent years. Most existing works embed watermarks in the DNN model for IP protection, which need to modify the model and lack of interpretability. In this paper, for the first time, we propose an interpretable intellectual property protection method for DNN based on explainable artificial intelligence. Compared with existing works, the proposed method does not modify the DNN model, and the decision of the ownership verification is interpretable. We extract the intrinsic features of the DNN model by using Deep Taylor Decomposition. Since the intrinsic feature is composed of unique interpretation of the model's decision, the intrinsic feature can be regarded as fingerprint of the model. If the fingerprint of a suspected model is the same as the original model, the suspected model is considered as a pirated model. Experimental results demonstrate that the fingerprints can be successfully used to verify the ownership of the model and the test accuracy of the model is not affected. Furthermore, the proposed method is robust to fine-tuning attack, pruning attack, watermark overwriting attack, and adaptive attack.
Imperceptible and Multi-channel Backdoor Attack against Deep Neural Networks
Jan 31, 2022Recent researches demonstrate that Deep Neural Networks (DNN) models are vulnerable to backdoor attacks. The backdoored DNN model will behave maliciously when images containing backdoor triggers arrive. To date, existing backdoor attacks are single-trigger and single-target attacks, and the triggers of most existing backdoor attacks are obvious thus are easy to be detected or noticed. In this paper, we propose a novel imperceptible and multi-channel backdoor attack against Deep Neural Networks by exploiting Discrete Cosine Transform (DCT) steganography. Based on the proposed backdoor attack method, we implement two variants of backdoor attacks, i.e., N-to-N backdoor attack and N-to-One backdoor attack. Specifically, for a colored image, we utilize DCT steganography to construct the trigger on different channels of the image. As a result, the trigger is stealthy and natural. Based on the proposed method, we implement multi-target and multi-trigger backdoor attacks. Experimental results demonstrate that the average attack success rate of the N-to-N backdoor attack is 93.95% on CIFAR-10 dataset and 91.55% on TinyImageNet dataset, respectively. The average attack success rate of N-to-One attack is 90.22% and 89.53% on CIFAR-10 and TinyImageNet datasets, respectively. Meanwhile, the proposed backdoor attack does not affect the classification accuracy of the DNN model. Moreover, the proposed attack is demonstrated to be robust to the state-of-the-art backdoor defense (Neural Cleanse).