 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurn Passive to Active: A Survey on Active Intellectual Property Protection of Deep Learning Models
Oct 15, 2023The intellectual property protection of deep learning (DL) models has attracted increasing serious concerns. Many works on intellectual property protection for Deep Neural Networks (DNN) models have been proposed. The vast majority of existing work uses DNN watermarking to verify the ownership of the model after piracy occurs, which is referred to as passive verification. On the contrary, we focus on a new type of intellectual property protection method named active copyright protection, which refers to active authorization control and user identity management of the DNN model. As of now, there is relatively limited research in the field of active DNN copyright protection. In this review, we attempt to clearly elaborate on the connotation, attributes, and requirements of active DNN copyright protection, provide evaluation methods and metrics for active copyright protection, review and analyze existing work on active DL model intellectual property protection, discuss potential attacks that active DL model copyright protection techniques may face, and provide challenges and future directions for active DL model intellectual property protection. This review is helpful to systematically introduce the new field of active DNN copyright protection and provide reference and foundation for subsequent work.
InFIP: An Explainable DNN Intellectual Property Protection Method based on Intrinsic Features
Oct 14, 2022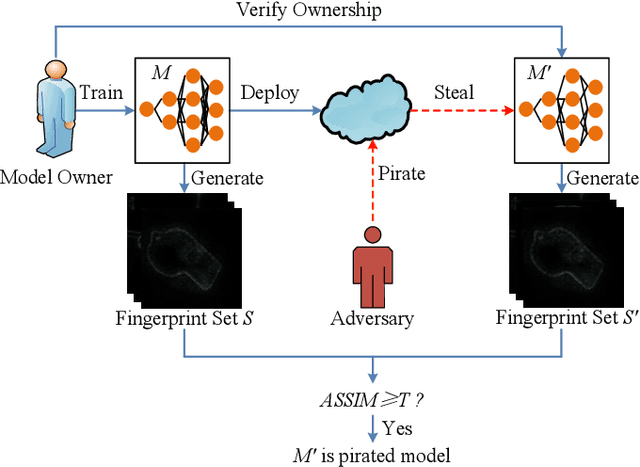
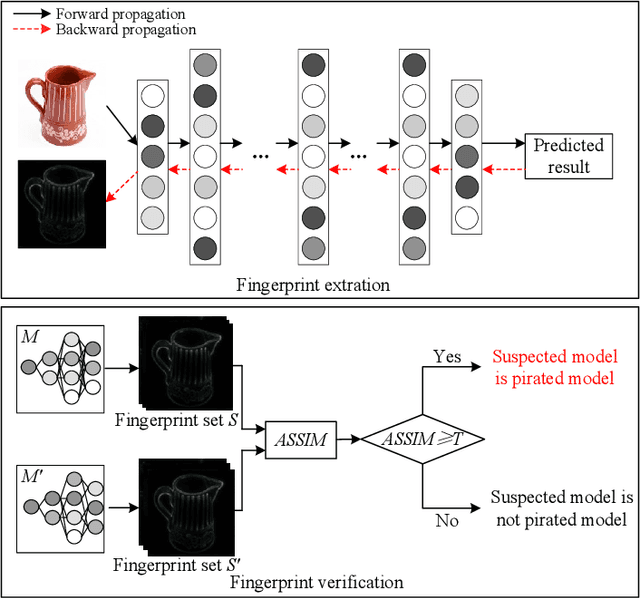
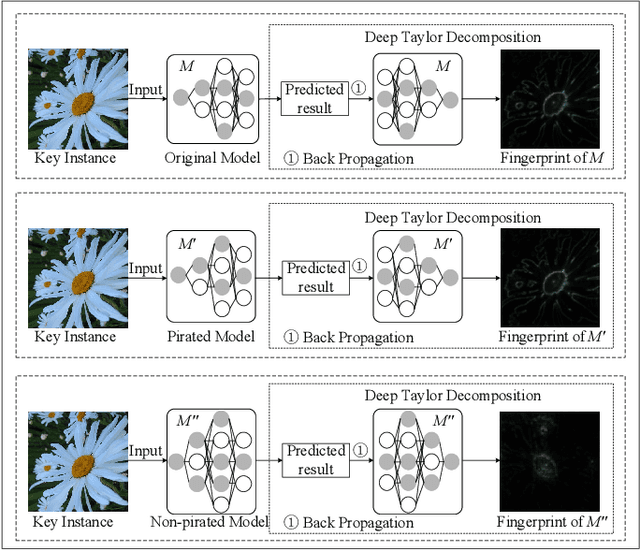

Intellectual property (IP) protection for Deep Neural Networks (DNNs) has raised serious concerns in recent years. Most existing works embed watermarks in the DNN model for IP protection, which need to modify the model and lack of interpretability. In this paper, for the first time, we propose an interpretable intellectual property protection method for DNN based on explainable artificial intelligence. Compared with existing works, the proposed method does not modify the DNN model, and the decision of the ownership verification is interpretable. We extract the intrinsic features of the DNN model by using Deep Taylor Decomposition. Since the intrinsic feature is composed of unique interpretation of the model's decision, the intrinsic feature can be regarded as fingerprint of the model. If the fingerprint of a suspected model is the same as the original model, the suspected model is considered as a pirated model. Experimental results demonstrate that the fingerprints can be successfully used to verify the ownership of the model and the test accuracy of the model is not affected. Furthermore, the proposed method is robust to fine-tuning attack, pruning attack, watermark overwriting attack, and adaptive attack.
Deep learning based sferics recognition for AMT data processing in the dead band
Sep 22, 2022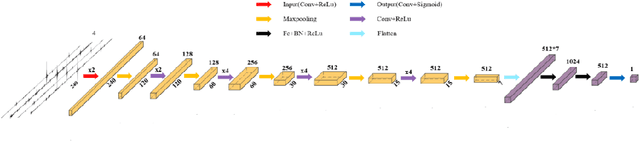
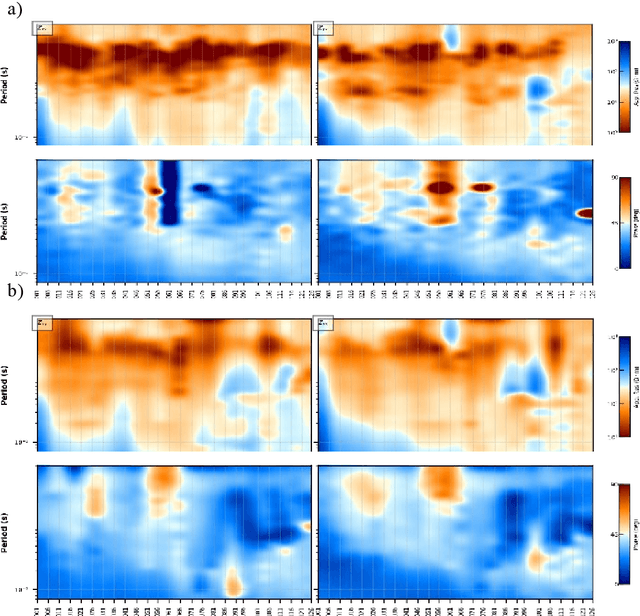
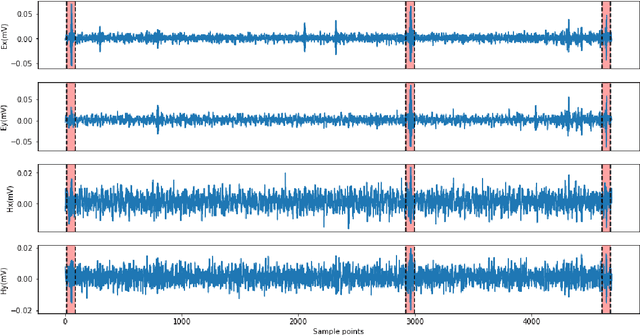
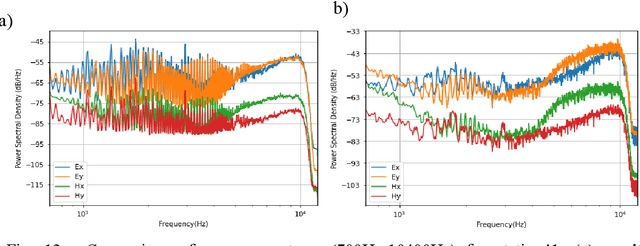
In the audio magnetotellurics (AMT) sounding data processing, the absence of sferic signals in some time ranges typically results in a lack of energy in the AMT dead band, which may cause unreliable resistivity estimate. We propose a deep convolutional neural network (CNN) to automatically recognize sferic signals from redundantly recorded data in a long time range and use them to compensate for the resistivity estimation. We train the CNN by using field time series data with different signal to noise rations that were acquired from different regions in mainland China. To solve the potential overfitting problem due to the limited number of sferic labels, we propose a training strategy that randomly generates training samples (with random data augmentations) while optimizing the CNN model parameters. We stop the training process and data generation until the training loss converges. In addition, we use a weighted binary cross-entropy loss function to solve the sample imbalance problem to better optimize the network, use multiple reasonable metrics to evaluate network performance, and carry out ablation experiments to optimally choose the model hyperparameters. Extensive field data applications show that our trained CNN can robustly recognize sferic signals from noisy time series for subsequent impedance estimation. The subsequent processing results show that our method can significantly improve S/N and effectively solve the problem of lack of energy in dead band. Compared to the traditional processing method without sferic compensation, our method can generate a smoother and more reasonable apparent resistivity-phase curves and depolarized phase tensor, correct the estimation error of sudden drop of high-frequency apparent resistivity and abnormal behavior of phase reversal, and finally better restore the real shallow subsurface resistivity structure.
Imperceptible and Multi-channel Backdoor Attack against Deep Neural Networks
Jan 31, 2022Recent researches demonstrate that Deep Neural Networks (DNN) models are vulnerable to backdoor attacks. The backdoored DNN model will behave maliciously when images containing backdoor triggers arrive. To date, existing backdoor attacks are single-trigger and single-target attacks, and the triggers of most existing backdoor attacks are obvious thus are easy to be detected or noticed. In this paper, we propose a novel imperceptible and multi-channel backdoor attack against Deep Neural Networks by exploiting Discrete Cosine Transform (DCT) steganography. Based on the proposed backdoor attack method, we implement two variants of backdoor attacks, i.e., N-to-N backdoor attack and N-to-One backdoor attack. Specifically, for a colored image, we utilize DCT steganography to construct the trigger on different channels of the image. As a result, the trigger is stealthy and natural. Based on the proposed method, we implement multi-target and multi-trigger backdoor attacks. Experimental results demonstrate that the average attack success rate of the N-to-N backdoor attack is 93.95% on CIFAR-10 dataset and 91.55% on TinyImageNet dataset, respectively. The average attack success rate of N-to-One attack is 90.22% and 89.53% on CIFAR-10 and TinyImageNet datasets, respectively. Meanwhile, the proposed backdoor attack does not affect the classification accuracy of the DNN model. Moreover, the proposed attack is demonstrated to be robust to the state-of-the-art backdoor defense (Neural Cleanse).
Compression-Resistant Backdoor Attack against Deep Neural Networks
Jan 03, 2022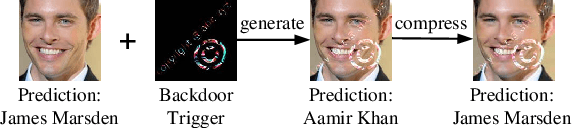
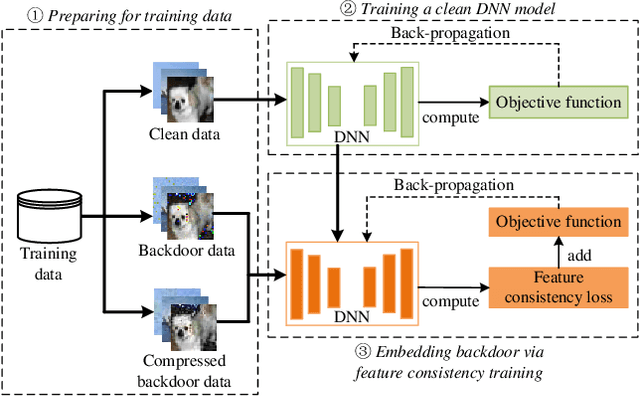

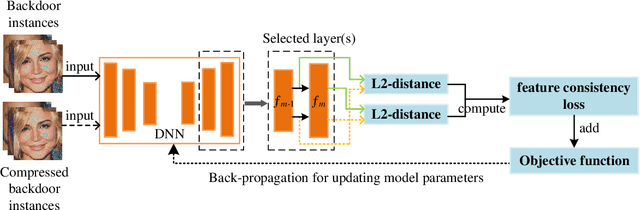
In recent years, many backdoor attacks based on training data poisoning have been proposed. However, in practice, those backdoor attacks are vulnerable to image compressions. When backdoor instances are compressed, the feature of specific backdoor trigger will be destroyed, which could result in the backdoor attack performance deteriorating. In this paper, we propose a compression-resistant backdoor attack based on feature consistency training. To the best of our knowledge, this is the first backdoor attack that is robust to image compressions. First, both backdoor images and their compressed versions are input into the deep neural network (DNN) for training. Then, the feature of each image is extracted by internal layers of the DNN. Next, the feature difference between backdoor images and their compressed versions are minimized. As a result, the DNN treats the feature of compressed images as the feature of backdoor images in feature space. After training, the backdoor attack against DNN is robust to image compression. Furthermore, we consider three different image compressions (i.e., JPEG, JPEG2000, WEBP) in feature consistency training, so that the backdoor attack is robust to multiple image compression algorithms. Experimental results demonstrate the effectiveness and robustness of the proposed backdoor attack. When the backdoor instances are compressed, the attack success rate of common backdoor attack is lower than 10%, while the attack success rate of our compression-resistant backdoor is greater than 97%. The compression-resistant attack is still robust even when the backdoor images are compressed with low compression quality. In addition, extensive experiments have demonstrated that, our compression-resistant backdoor attack has the generalization ability to resist image compression which is not used in the training process.
Detecting Backdoor in Deep Neural Networks via Intentional Adversarial Perturbations
Jun 22, 2021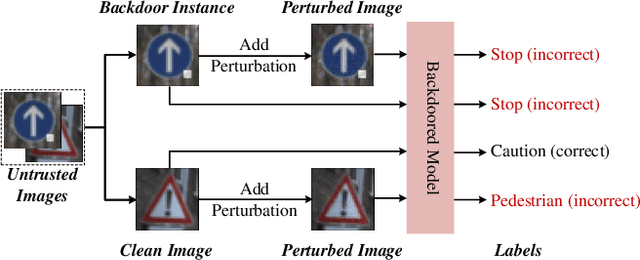



Recent researches show that deep learning model is susceptible to backdoor attacks. Many defenses against backdoor attacks have been proposed. However, existing defense works require high computational overhead or backdoor attack information such as the trigger size, which is difficult to satisfy in realistic scenarios. In this paper, a novel backdoor detection method based on adversarial examples is proposed. The proposed method leverages intentional adversarial perturbations to detect whether an image contains a trigger, which can be applied in both the training stage and the inference stage (sanitize the training set in training stage and detect the backdoor instances in inference stage). Specifically, given an untrusted image, the adversarial perturbation is added to the image intentionally. If the prediction of the model on the perturbed image is consistent with that on the unperturbed image, the input image will be considered as a backdoor instance. Compared with most existing defense works, the proposed adversarial perturbation based method requires low computational resources and maintains the visual quality of the images. Experimental results show that, the backdoor detection rate of the proposed defense method is 99.63%, 99.76% and 99.91% on Fashion-MNIST, CIFAR-10 and GTSRB datasets, respectively. Besides, the proposed method maintains the visual quality of the image as the l2 norm of the added perturbation are as low as 2.8715, 3.0513 and 2.4362 on Fashion-MNIST, CIFAR-10 and GTSRB datasets, respectively. In addition, it is also demonstrated that the proposed method can achieve high defense performance against backdoor attacks under different attack settings (trigger transparency, trigger size and trigger pattern). Compared with the existing defense work (STRIP), the proposed method has better detection performance on all the three datasets, and is more efficient than STRIP.
Detect and remove watermark in deep neural networks via generative adversarial networks
Jun 15, 2021
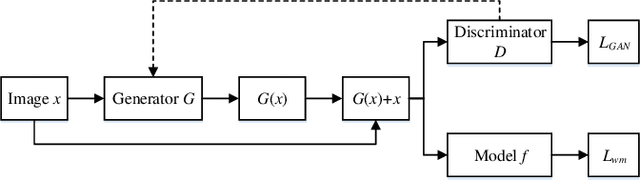

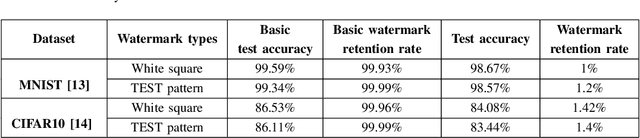
Deep neural networks (DNN) have achieved remarkable performance in various fields. However, training a DNN model from scratch requires a lot of computing resources and training data. It is difficult for most individual users to obtain such computing resources and training data. Model copyright infringement is an emerging problem in recent years. For instance, pre-trained models may be stolen or abuse by illegal users without the authorization of the model owner. Recently, many works on protecting the intellectual property of DNN models have been proposed. In these works, embedding watermarks into DNN based on backdoor is one of the widely used methods. However, when the DNN model is stolen, the backdoor-based watermark may face the risk of being detected and removed by an adversary. In this paper, we propose a scheme to detect and remove watermark in deep neural networks via generative adversarial networks (GAN). We demonstrate that the backdoor-based DNN watermarks are vulnerable to the proposed GAN-based watermark removal attack. The proposed attack method includes two phases. In the first phase, we use the GAN and few clean images to detect and reverse the watermark in the DNN model. In the second phase, we fine-tune the watermarked DNN based on the reversed backdoor images. Experimental evaluations on the MNIST and CIFAR10 datasets demonstrate that, the proposed method can effectively remove about 98% of the watermark in DNN models, as the watermark retention rate reduces from 100% to less than 2% after applying the proposed attack. In the meantime, the proposed attack hardly affects the model's performance. The test accuracy of the watermarked DNN on the MNIST and the CIFAR10 datasets drops by less than 1% and 3%, respectively.
AdvParams: An Active DNN Intellectual Property Protection Technique via Adversarial Perturbation Based Parameter Encryption
May 28, 2021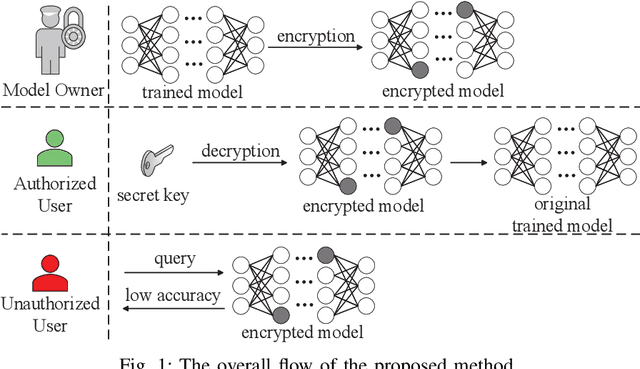

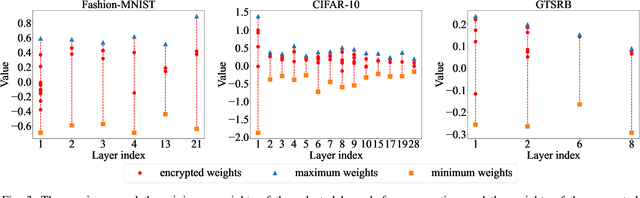
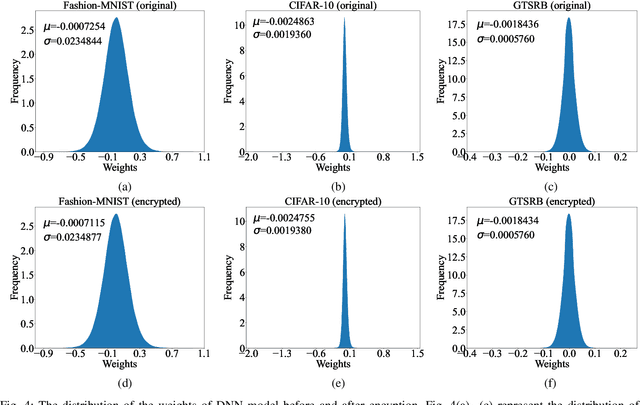
A well-trained DNN model can be regarded as an intellectual property (IP) of the model owner. To date, many DNN IP protection methods have been proposed, but most of them are watermarking based verification methods where model owners can only verify their ownership passively after the copyright of DNN models has been infringed. In this paper, we propose an effective framework to actively protect the DNN IP from infringement. Specifically, we encrypt the DNN model's parameters by perturbing them with well-crafted adversarial perturbations. With the encrypted parameters, the accuracy of the DNN model drops significantly, which can prevent malicious infringers from using the model. After the encryption, the positions of encrypted parameters and the values of the added adversarial perturbations form a secret key. Authorized user can use the secret key to decrypt the model. Compared with the watermarking methods which only passively verify the ownership after the infringement occurs, the proposed method can prevent infringement in advance. Moreover, compared with most of the existing active DNN IP protection methods, the proposed method does not require additional training process of the model, which introduces low computational overhead. Experimental results show that, after the encryption, the test accuracy of the model drops by 80.65%, 81.16%, and 87.91% on Fashion-MNIST, CIFAR-10, and GTSRB, respectively. Moreover, the proposed method only needs to encrypt an extremely low number of parameters, and the proportion of the encrypted parameters of all the model's parameters is as low as 0.000205%. The experimental results also indicate that, the proposed method is robust against model fine-tuning attack and model pruning attack. Moreover, for the adaptive attack where attackers know the detailed steps of the proposed method, the proposed method is also demonstrated to be robust.
Protecting the Intellectual Properties of Deep Neural Networks with an Additional Class and Steganographic Images
Apr 19, 2021


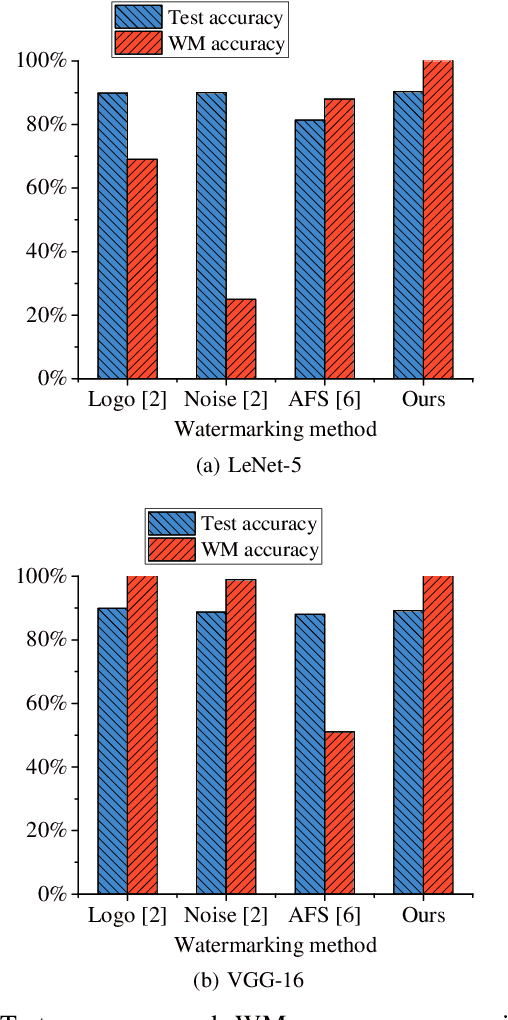
Recently, the research on protecting the intellectual properties (IP) of deep neural networks (DNN) has attracted serious concerns. A number of DNN copyright protection methods have been proposed. However, most of the existing watermarking methods focus on verifying the copyright of the model, which do not support the authentication and management of users' fingerprints, thus can not satisfy the requirements of commercial copyright protection. In addition, the query modification attack which was proposed recently can invalidate most of the existing backdoor-based watermarking methods. To address these challenges, in this paper, we propose a method to protect the intellectual properties of DNN models by using an additional class and steganographic images. Specifically, we use a set of watermark key samples to embed an additional class into the DNN, so that the watermarked DNN will classify the watermark key sample as the predefined additional class in the copyright verification stage. We adopt the least significant bit (LSB) image steganography to embed users' fingerprints into watermark key images. Each user will be assigned with a unique fingerprint image so that the user's identity can be authenticated later. Experimental results demonstrate that, the proposed method can protect the copyright of DNN models effectively. On Fashion-MNIST and CIFAR-10 datasets, the proposed method can obtain 100% watermark accuracy and 100% fingerprint authentication success rate. In addition, the proposed method is demonstrated to be robust to the model fine-tuning attack, model pruning attack, and the query modification attack. Compared with three existing watermarking methods (the logo-based, noise-based, and adversarial frontier stitching watermarking methods), the proposed method has better performance on watermark accuracy and robustness against the query modification attack.
Robust Backdoor Attacks against Deep Neural Networks in Real Physical World
Apr 15, 2021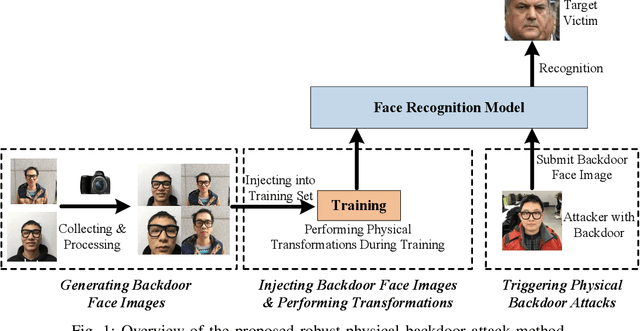
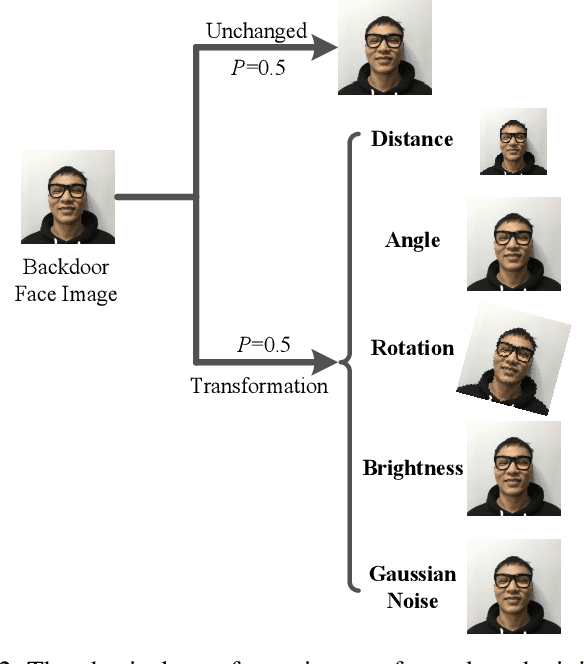
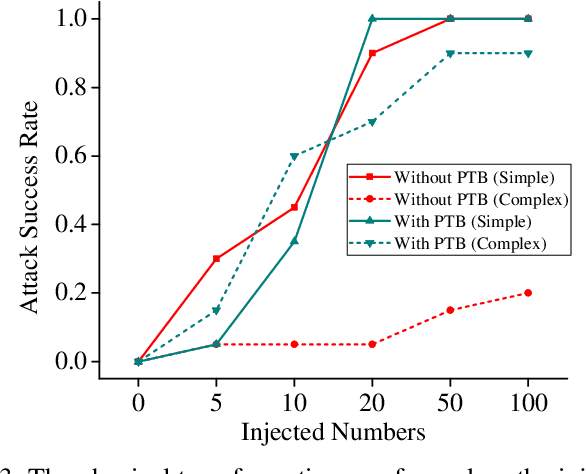

Deep neural networks (DNN) have been widely deployed in various practical applications. However, many researches indicated that DNN is vulnerable to backdoor attacks. The attacker can create a hidden backdoor in target DNN model, and trigger the malicious behaviors by submitting specific backdoor instance. However, almost all the existing backdoor works focused on the digital domain, while few studies investigate the backdoor attacks in real physical world. Restricted to a variety of physical constrains, the performance of backdoor attacks in the real world will be severely degraded. In this paper, we propose a robust physical backdoor attack method, PTB (physical transformations for backdoors), to implement the backdoor attacks against deep learning models in the physical world. Specifically, in the training phase, we perform a series of physical transformations on these injected backdoor instances at each round of model training, so as to simulate various transformations that a backdoor may experience in real world, thus improves its physical robustness. Experimental results on the state-of-the-art face recognition model show that, compared with the methods that without PTB, the proposed attack method can significantly improve the performance of backdoor attacks in real physical world. Under various complex physical conditions, by injecting only a very small ratio (0.5%) of backdoor instances, the success rate of physical backdoor attacks with the PTB method on VGGFace is 82%, while the attack success rate of backdoor attacks without the proposed PTB method is lower than 11%. Meanwhile, the normal performance of target DNN model has not been affected. This paper is the first work on the robustness of physical backdoor attacks, and is hopeful for providing guideline for the subsequent physical backdoor works.