 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression-Resistant Backdoor Attack against Deep Neural Networks
Jan 03, 2022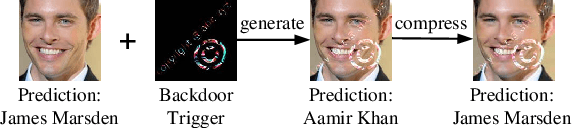
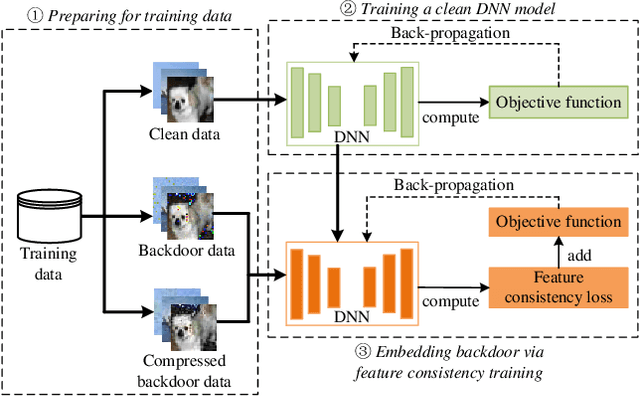

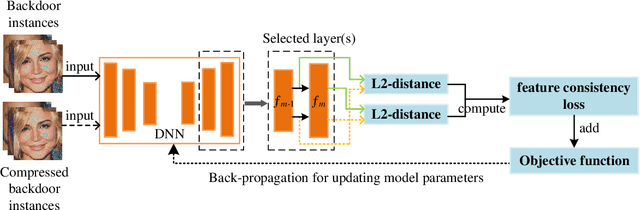
In recent years, many backdoor attacks based on training data poisoning have been proposed. However, in practice, those backdoor attacks are vulnerable to image compressions. When backdoor instances are compressed, the feature of specific backdoor trigger will be destroyed, which could result in the backdoor attack performance deteriorating. In this paper, we propose a compression-resistant backdoor attack based on feature consistency training. To the best of our knowledge, this is the first backdoor attack that is robust to image compressions. First, both backdoor images and their compressed versions are input into the deep neural network (DNN) for training. Then, the feature of each image is extracted by internal layers of the DNN. Next, the feature difference between backdoor images and their compressed versions are minimized. As a result, the DNN treats the feature of compressed images as the feature of backdoor images in feature space. After training, the backdoor attack against DNN is robust to image compression. Furthermore, we consider three different image compressions (i.e., JPEG, JPEG2000, WEBP) in feature consistency training, so that the backdoor attack is robust to multiple image compression algorithms. Experimental results demonstrate the effectiveness and robustness of the proposed backdoor attack. When the backdoor instances are compressed, the attack success rate of common backdoor attack is lower than 10%, while the attack success rate of our compression-resistant backdoor is greater than 97%. The compression-resistant attack is still robust even when the backdoor images are compressed with low compression quality. In addition, extensive experiments have demonstrated that, our compression-resistant backdoor attack has the generalization ability to resist image compression which is not used in the training process.
Detect and remove watermark in deep neural networks via generative adversarial networks
Jun 15, 2021
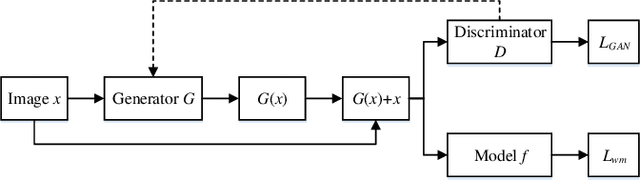

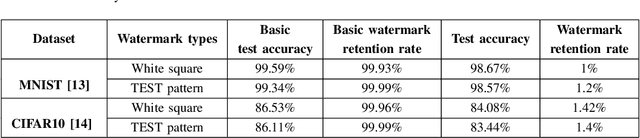
Deep neural networks (DNN) have achieved remarkable performance in various fields. However, training a DNN model from scratch requires a lot of computing resources and training data. It is difficult for most individual users to obtain such computing resources and training data. Model copyright infringement is an emerging problem in recent years. For instance, pre-trained models may be stolen or abuse by illegal users without the authorization of the model owner. Recently, many works on protecting the intellectual property of DNN models have been proposed. In these works, embedding watermarks into DNN based on backdoor is one of the widely used methods. However, when the DNN model is stolen, the backdoor-based watermark may face the risk of being detected and removed by an adversary. In this paper, we propose a scheme to detect and remove watermark in deep neural networks via generative adversarial networks (GAN). We demonstrate that the backdoor-based DNN watermarks are vulnerable to the proposed GAN-based watermark removal attack. The proposed attack method includes two phases. In the first phase, we use the GAN and few clean images to detect and reverse the watermark in the DNN model. In the second phase, we fine-tune the watermarked DNN based on the reversed backdoor images. Experimental evaluations on the MNIST and CIFAR10 datasets demonstrate that, the proposed method can effectively remove about 98% of the watermark in DNN models, as the watermark retention rate reduces from 100% to less than 2% after applying the proposed attack. In the meantime, the proposed attack hardly affects the model's performance. The test accuracy of the watermarked DNN on the MNIST and the CIFAR10 datasets drops by less than 1% and 3%, respectively.
Protecting the Intellectual Properties of Deep Neural Networks with an Additional Class and Steganographic Images
Apr 19, 2021


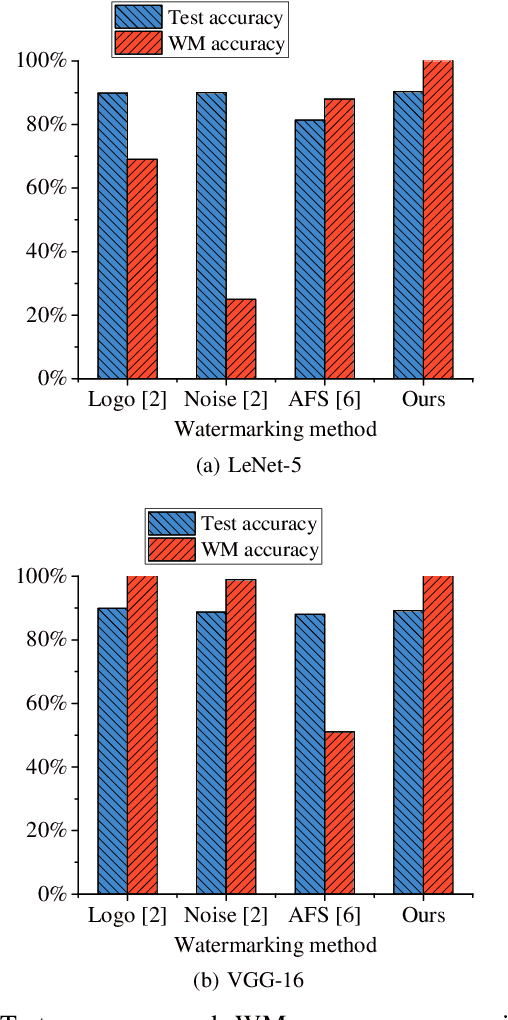
Recently, the research on protecting the intellectual properties (IP) of deep neural networks (DNN) has attracted serious concerns. A number of DNN copyright protection methods have been proposed. However, most of the existing watermarking methods focus on verifying the copyright of the model, which do not support the authentication and management of users' fingerprints, thus can not satisfy the requirements of commercial copyright protection. In addition, the query modification attack which was proposed recently can invalidate most of the existing backdoor-based watermarking methods. To address these challenges, in this paper, we propose a method to protect the intellectual properties of DNN models by using an additional class and steganographic images. Specifically, we use a set of watermark key samples to embed an additional class into the DNN, so that the watermarked DNN will classify the watermark key sample as the predefined additional class in the copyright verification stage. We adopt the least significant bit (LSB) image steganography to embed users' fingerprints into watermark key images. Each user will be assigned with a unique fingerprint image so that the user's identity can be authenticated later. Experimental results demonstrate that, the proposed method can protect the copyright of DNN models effectively. On Fashion-MNIST and CIFAR-10 datasets, the proposed method can obtain 100% watermark accuracy and 100% fingerprint authentication success rate. In addition, the proposed method is demonstrated to be robust to the model fine-tuning attack, model pruning attack, and the query modification attack. Compared with three existing watermarking methods (the logo-based, noise-based, and adversarial frontier stitching watermarking methods), the proposed method has better performance on watermark accuracy and robustness against the query modification attack.
Robust Backdoor Attacks against Deep Neural Networks in Real Physical World
Apr 15, 2021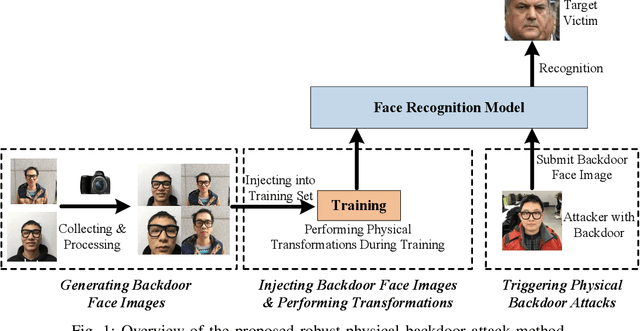
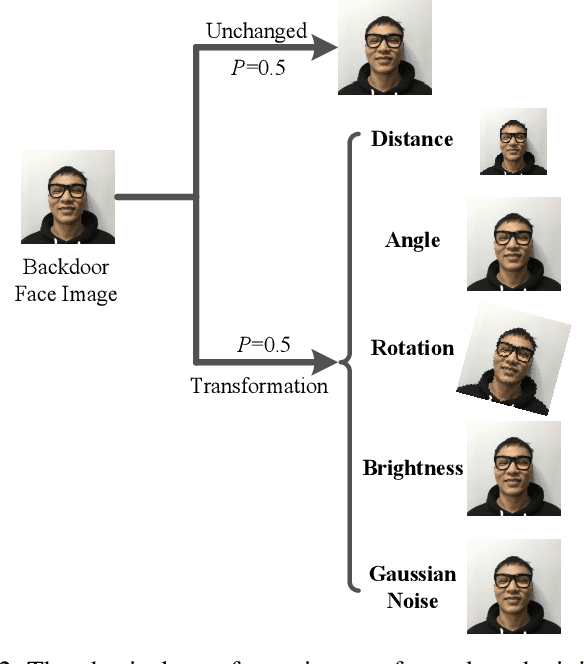
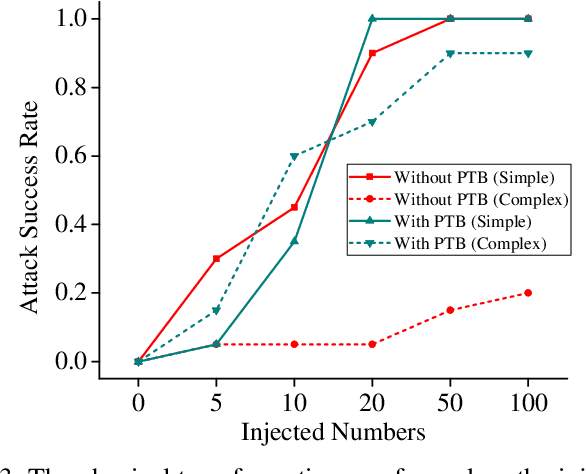

Deep neural networks (DNN) have been widely deployed in various practical applications. However, many researches indicated that DNN is vulnerable to backdoor attacks. The attacker can create a hidden backdoor in target DNN model, and trigger the malicious behaviors by submitting specific backdoor instance. However, almost all the existing backdoor works focused on the digital domain, while few studies investigate the backdoor attacks in real physical world. Restricted to a variety of physical constrains, the performance of backdoor attacks in the real world will be severely degraded. In this paper, we propose a robust physical backdoor attack method, PTB (physical transformations for backdoors), to implement the backdoor attacks against deep learning models in the physical world. Specifically, in the training phase, we perform a series of physical transformations on these injected backdoor instances at each round of model training, so as to simulate various transformations that a backdoor may experience in real world, thus improves its physical robustness. Experimental results on the state-of-the-art face recognition model show that, compared with the methods that without PTB, the proposed attack method can significantly improve the performance of backdoor attacks in real physical world. Under various complex physical conditions, by injecting only a very small ratio (0.5%) of backdoor instances, the success rate of physical backdoor attacks with the PTB method on VGGFace is 82%, while the attack success rate of backdoor attacks without the proposed PTB method is lower than 11%. Meanwhile, the normal performance of target DNN model has not been affected. This paper is the first work on the robustness of physical backdoor attacks, and is hopeful for providing guideline for the subsequent physical backdoor works.
ActiveGuard: An Active DNN IP Protection Technique via Adversarial Examples
Mar 02, 2021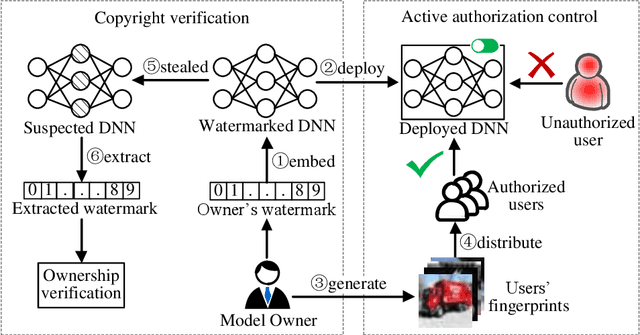
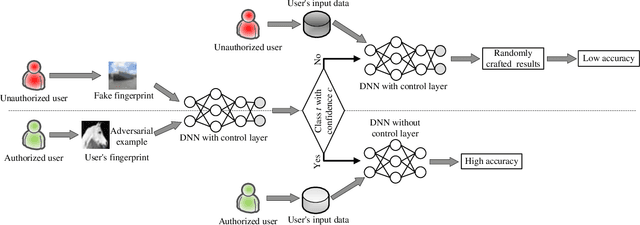

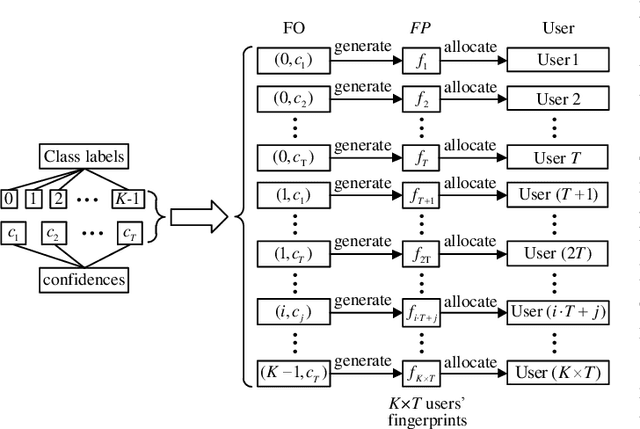
The training of Deep Neural Networks (DNN) is costly, thus DNN can be considered as the intellectual properties (IP) of model owners. To date, most of the existing protection works focus on verifying the ownership after the DNN model is stolen, which cannot resist piracy in advance. To this end, we propose an active DNN IP protection method based on adversarial examples against DNN piracy, named ActiveGuard. ActiveGuard aims to achieve authorization control and users' fingerprints management through adversarial examples, and can provide ownership verification. Specifically, ActiveGuard exploits the elaborate adversarial examples as users' fingerprints to distinguish authorized users from unauthorized users. Legitimate users can enter fingerprints into DNN for identity authentication and authorized usage, while unauthorized users will obtain poor model performance due to an additional control layer. In addition, ActiveGuard enables the model owner to embed a watermark into the weights of DNN. When the DNN is illegally pirated, the model owner can extract the embedded watermark and perform ownership verification. Experimental results show that, for authorized users, the test accuracy of LeNet-5 and Wide Residual Network (WRN) models are 99.15% and 91.46%, respectively, while for unauthorized users, the test accuracy of the two DNNs are only 8.92% (LeNet-5) and 10% (WRN), respectively. Besides, each authorized user can pass the fingerprint authentication with a high success rate (up to 100%). For ownership verification, the embedded watermark can be successfully extracted, while the normal performance of the DNN model will not be affected. Further, ActiveGuard is demonstrated to be robust against fingerprint forgery attack, model fine-tuning attack and pruning attack.
SocialGuard: An Adversarial Example Based Privacy-Preserving Technique for Social Images
Nov 27, 2020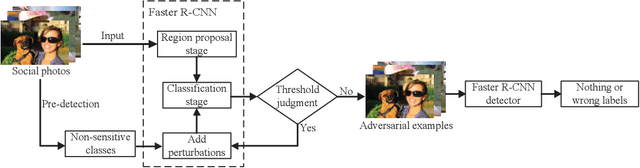
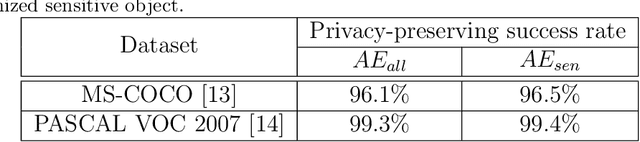

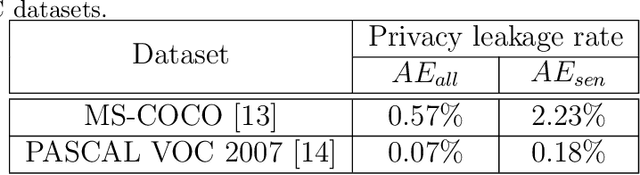
The popularity of various social platforms has prompted more people to share their routine photos online. However, undesirable privacy leakages occur due to such online photo sharing behaviors. Advanced deep neural network (DNN) based object detectors can easily steal users' personal information exposed in shared photos. In this paper, we propose a novel adversarial example based privacy-preserving technique for social images against object detectors based privacy stealing. Specifically, we develop an Object Disappearance Algorithm to craft two kinds of adversarial social images. One can hide all objects in the social images from being detected by an object detector, and the other can make the customized sensitive objects be incorrectly classified by the object detector. The Object Disappearance Algorithm constructs perturbation on a clean social image. After being injected with the perturbation, the social image can easily fool the object detector, while its visual quality will not be degraded. We use two metrics, privacy-preserving success rate and privacy leakage rate, to evaluate the effectiveness of the proposed method. Experimental results show that, the proposed method can effectively protect the privacy of social images. The privacy-preserving success rates of the proposed method on MS-COCO and PASCAL VOC 2007 datasets are high up to 96.1% and 99.3%, respectively, and the privacy leakage rates on these two datasets are as low as 0.57% and 0.07%, respectively. In addition, compared with existing image processing methods (low brightness, noise, blur, mosaic and JPEG compression), the proposed method can achieve much better performance in privacy protection and image visual quality maintenance.