 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Singular Defects in Large Language Models
Feb 10, 2025Large transformer models are known to produce high-norm tokens. In vision transformers (ViTs), such tokens have been mathematically modeled through the singular vectors of the linear approximations of layers. However, in large language models (LLMs), the underlying causes of high-norm tokens remain largely unexplored, and their different properties from those of ViTs require a new analysis framework. In this paper, we provide both theoretical insights and empirical validation across a range of recent models, leading to the following observations: i) The layer-wise singular direction predicts the abrupt explosion of token norms in LLMs. ii) The negative eigenvalues of a layer explain its sudden decay. iii) The computational pathways leading to high-norm tokens differ between initial and noninitial tokens. iv) High-norm tokens are triggered by the right leading singular vector of the matrix approximating the corresponding modules. We showcase two practical applications of these findings: the improvement of quantization schemes and the design of LLM signatures. Our findings not only advance the understanding of singular defects in LLMs but also open new avenues for their application. We expect that this work will stimulate further research into the internal mechanisms of LLMs and will therefore publicly release our code.
SINDER: Repairing the Singular Defects of DINOv2
Jul 23, 2024



Vision Transformer models trained on large-scale datasets, although effective, often exhibit artifacts in the patch token they extract. While such defects can be alleviated by re-training the entire model with additional classification tokens, the underlying reasons for the presence of these tokens remain unclear. In this paper, we conduct a thorough investigation of this phenomenon, combining theoretical analysis with empirical observations. Our findings reveal that these artifacts originate from the pre-trained network itself, specifically stemming from the leading left singular vector of the network's weights. Furthermore, to mitigate these defects, we propose a novel fine-tuning smooth regularization that rectifies structural deficiencies using only a small dataset, thereby avoiding the need for complete re-training. We validate our method on various downstream tasks, including unsupervised segmentation, classification, supervised segmentation, and depth estimation, demonstrating its effectiveness in improving model performance. Codes and checkpoints are available at https://github.com/haoqiwang/sinder.
Get the Best of Both Worlds: Improving Accuracy and Transferability by Grassmann Class Representation
Aug 03, 2023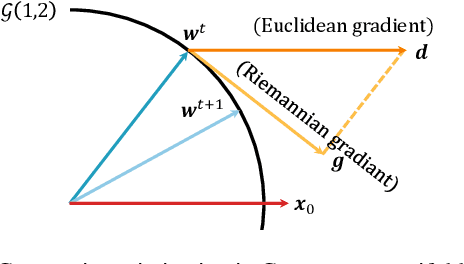


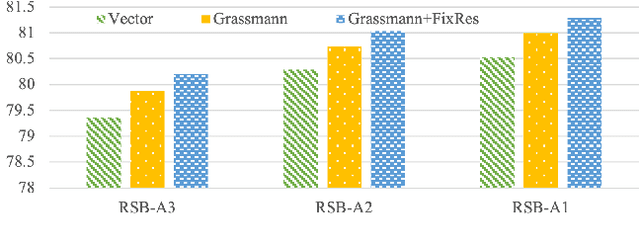
We generalize the class vectors found in neural networks to linear subspaces (i.e.~points in the Grassmann manifold) and show that the Grassmann Class Representation (GCR) enables the simultaneous improvement in accuracy and feature transferability. In GCR, each class is a subspace and the logit is defined as the norm of the projection of a feature onto the class subspace. We integrate Riemannian SGD into deep learning frameworks such that class subspaces in a Grassmannian are jointly optimized with the rest model parameters. Compared to the vector form, the representative capability of subspaces is more powerful. We show that on ImageNet-1K, the top-1 error of ResNet50-D, ResNeXt50, Swin-T and Deit3-S are reduced by 5.6%, 4.5%, 3.0% and 3.5%, respectively. Subspaces also provide freedom for features to vary and we observed that the intra-class feature variability grows when the subspace dimension increases. Consequently, we found the quality of GCR features is better for downstream tasks. For ResNet50-D, the average linear transfer accuracy across 6 datasets improves from 77.98% to 79.70% compared to the strong baseline of vanilla softmax. For Swin-T, it improves from 81.5% to 83.4% and for Deit3, it improves from 73.8% to 81.4%. With these encouraging results, we believe that more applications could benefit from the Grassmann class representation. Code is released at https://github.com/innerlee/GCR.
OpenOOD v1.5: Enhanced Benchmark for Out-of-Distribution Detection
Jun 17, 2023Out-of-Distribution (OOD) detection is critical for the reliable operation of open-world intelligent systems. Despite the emergence of an increasing number of OOD detection methods, the evaluation inconsistencies present challenges for tracking the progress in this field. OpenOOD v1 initiated the unification of the OOD detection evaluation but faced limitations in scalability and usability. In response, this paper presents OpenOOD v1.5, a significant improvement from its predecessor that ensures accurate, standardized, and user-friendly evaluation of OOD detection methodologies. Notably, OpenOOD v1.5 extends its evaluation capabilities to large-scale datasets such as ImageNet, investigates full-spectrum OOD detection which is important yet underexplored, and introduces new features including an online leaderboard and an easy-to-use evaluator. This work also contributes in-depth analysis and insights derived from comprehensive experimental results, thereby enriching the knowledge pool of OOD detection methodologies. With these enhancements, OpenOOD v1.5 aims to drive advancements and offer a more robust and comprehensive evaluation benchmark for OOD detection research.
OpenOOD: Benchmarking Generalized Out-of-Distribution Detection
Oct 13, 2022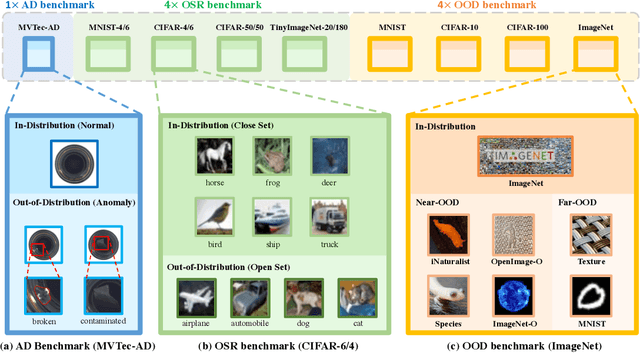
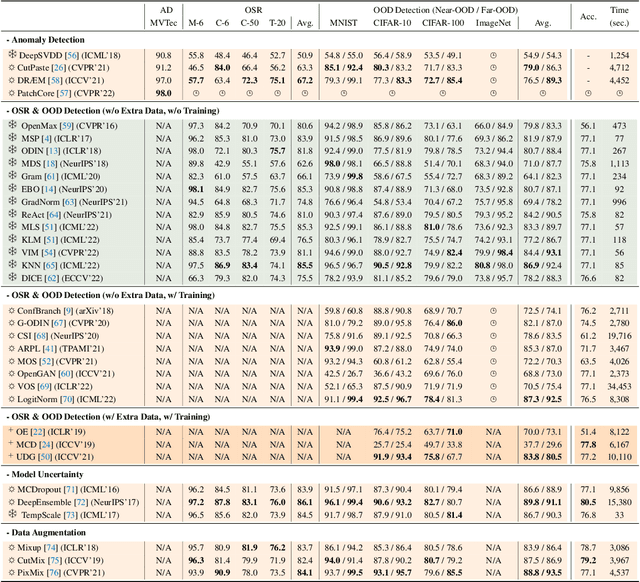
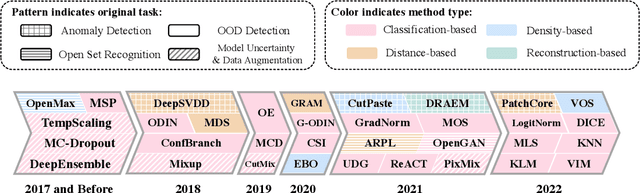
Out-of-distribution (OOD) detection is vital to safety-critical machine learning applications and has thus been extensively studied, with a plethora of methods developed in the literature. However, the field currently lacks a unified, strictly formulated, and comprehensive benchmark, which often results in unfair comparisons and inconclusive results. From the problem setting perspective, OOD detection is closely related to neighboring fields including anomaly detection (AD), open set recognition (OSR), and model uncertainty, since methods developed for one domain are often applicable to each other. To help the community to improve the evaluation and advance, we build a unified, well-structured codebase called OpenOOD, which implements over 30 methods developed in relevant fields and provides a comprehensive benchmark under the recently proposed generalized OOD detection framework. With a comprehensive comparison of these methods, we are gratified that the field has progressed significantly over the past few years, where both preprocessing methods and the orthogonal post-hoc methods show strong potential.
ViM: Out-Of-Distribution with Virtual-logit Matching
Mar 21, 2022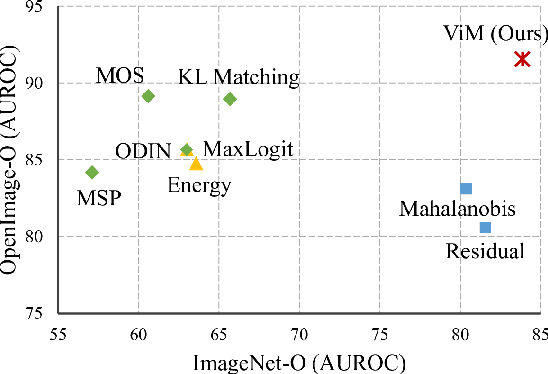

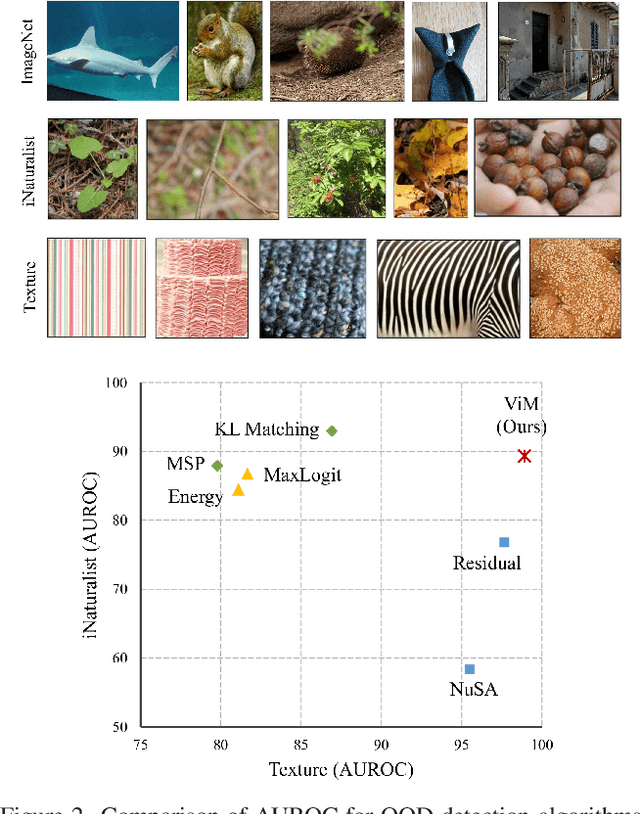
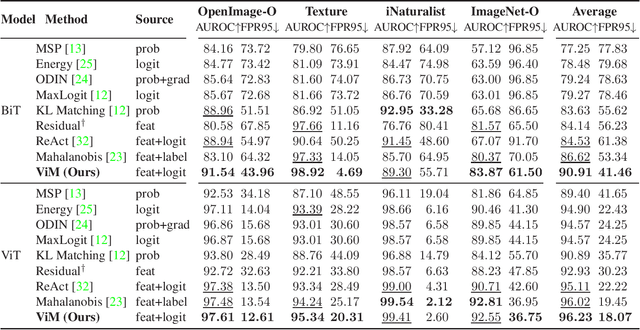
Most of the existing Out-Of-Distribution (OOD) detection algorithms depend on single input source: the feature, the logit, or the softmax probability. However, the immense diversity of the OOD examples makes such methods fragile. There are OOD samples that are easy to identify in the feature space while hard to distinguish in the logit space and vice versa. Motivated by this observation, we propose a novel OOD scoring method named Virtual-logit Matching (ViM), which combines the class-agnostic score from feature space and the In-Distribution (ID) class-dependent logits. Specifically, an additional logit representing the virtual OOD class is generated from the residual of the feature against the principal space, and then matched with the original logits by a constant scaling. The probability of this virtual logit after softmax is the indicator of OOD-ness. To facilitate the evaluation of large-scale OOD detection in academia, we create a new OOD dataset for ImageNet-1K, which is human-annotated and is 8.8x the size of existing datasets. We conducted extensive experiments, including CNNs and vision transformers, to demonstrate the effectiveness of the proposed ViM score. In particular, using the BiT-S model, our method gets an average AUROC 90.91% on four difficult OOD benchmarks, which is 4% ahead of the best baseline. Code and dataset are available at https://github.com/haoqiwang/vim.
Semantically Coherent Out-of-Distribution Detection
Aug 26, 2021
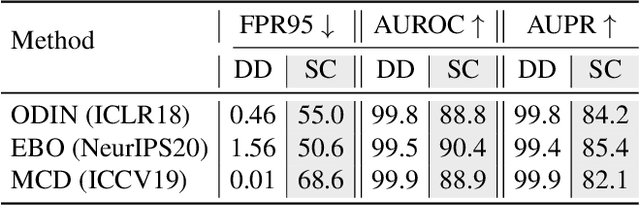
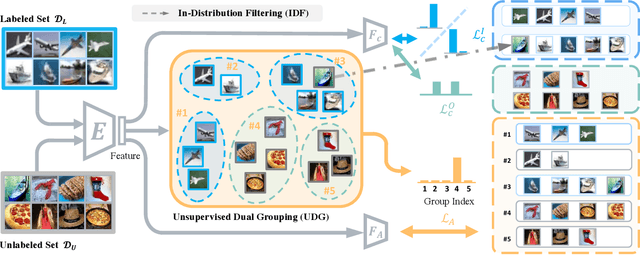
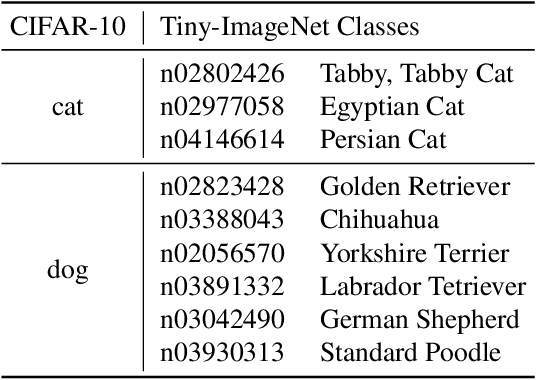
Current out-of-distribution (OOD) detection benchmarks are commonly built by defining one dataset as in-distribution (ID) and all others as OOD. However, these benchmarks unfortunately introduce some unwanted and impractical goals, e.g., to perfectly distinguish CIFAR dogs from ImageNet dogs, even though they have the same semantics and negligible covariate shifts. These unrealistic goals will result in an extremely narrow range of model capabilities, greatly limiting their use in real applications. To overcome these drawbacks, we re-design the benchmarks and propose the semantically coherent out-of-distribution detection (SC-OOD). On the SC-OOD benchmarks, existing methods suffer from large performance degradation, suggesting that they are extremely sensitive to low-level discrepancy between data sources while ignoring their inherent semantics. To develop an effective SC-OOD detection approach, we leverage an external unlabeled set and design a concise framework featured by unsupervised dual grouping (UDG) for the joint modeling of ID and OOD data. The proposed UDG can not only enrich the semantic knowledge of the model by exploiting unlabeled data in an unsupervised manner, but also distinguish ID/OOD samples to enhance ID classification and OOD detection tasks simultaneously. Extensive experiments demonstrate that our approach achieves state-of-the-art performance on SC-OOD benchmarks. Code and benchmarks are provided on our project page: https://jingkang50.github.io/projects/scood.
Detect and remove watermark in deep neural networks via generative adversarial networks
Jun 15, 2021
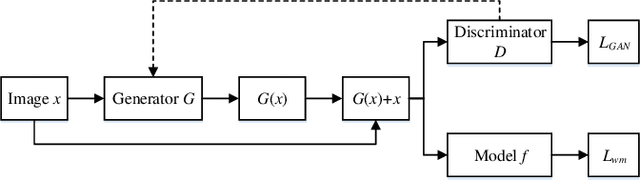

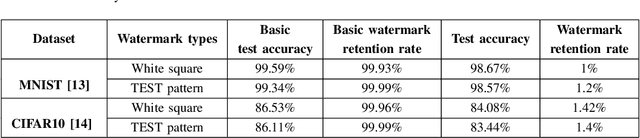
Deep neural networks (DNN) have achieved remarkable performance in various fields. However, training a DNN model from scratch requires a lot of computing resources and training data. It is difficult for most individual users to obtain such computing resources and training data. Model copyright infringement is an emerging problem in recent years. For instance, pre-trained models may be stolen or abuse by illegal users without the authorization of the model owner. Recently, many works on protecting the intellectual property of DNN models have been proposed. In these works, embedding watermarks into DNN based on backdoor is one of the widely used methods. However, when the DNN model is stolen, the backdoor-based watermark may face the risk of being detected and removed by an adversary. In this paper, we propose a scheme to detect and remove watermark in deep neural networks via generative adversarial networks (GAN). We demonstrate that the backdoor-based DNN watermarks are vulnerable to the proposed GAN-based watermark removal attack. The proposed attack method includes two phases. In the first phase, we use the GAN and few clean images to detect and reverse the watermark in the DNN model. In the second phase, we fine-tune the watermarked DNN based on the reversed backdoor images. Experimental evaluations on the MNIST and CIFAR10 datasets demonstrate that, the proposed method can effectively remove about 98% of the watermark in DNN models, as the watermark retention rate reduces from 100% to less than 2% after applying the proposed attack. In the meantime, the proposed attack hardly affects the model's performance. The test accuracy of the watermarked DNN on the MNIST and the CIFAR10 datasets drops by less than 1% and 3%, respectively.