 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect and remove watermark in deep neural networks via generative adversarial networks
Paper and Code
Jun 15, 2021
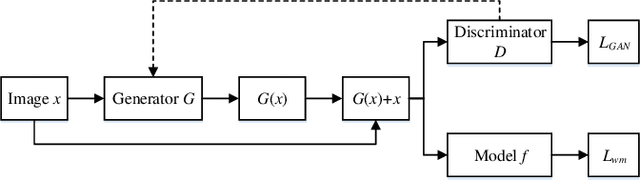

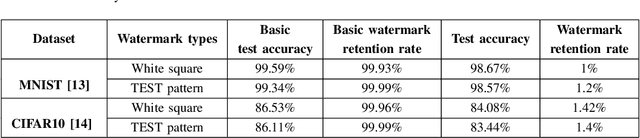
Deep neural networks (DNN) have achieved remarkable performance in various fields. However, training a DNN model from scratch requires a lot of computing resources and training data. It is difficult for most individual users to obtain such computing resources and training data. Model copyright infringement is an emerging problem in recent years. For instance, pre-trained models may be stolen or abuse by illegal users without the authorization of the model owner. Recently, many works on protecting the intellectual property of DNN models have been proposed. In these works, embedding watermarks into DNN based on backdoor is one of the widely used methods. However, when the DNN model is stolen, the backdoor-based watermark may face the risk of being detected and removed by an adversary. In this paper, we propose a scheme to detect and remove watermark in deep neural networks via generative adversarial networks (GAN). We demonstrate that the backdoor-based DNN watermarks are vulnerable to the proposed GAN-based watermark removal attack. The proposed attack method includes two phases. In the first phase, we use the GAN and few clean images to detect and reverse the watermark in the DNN model. In the second phase, we fine-tune the watermarked DNN based on the reversed backdoor images. Experimental evaluations on the MNIST and CIFAR10 datasets demonstrate that, the proposed method can effectively remove about 98% of the watermark in DNN models, as the watermark retention rate reduces from 100% to less than 2% after applying the proposed attack. In the meantime, the proposed attack hardly affects the model's performance. The test accuracy of the watermarked DNN on the MNIST and the CIFAR10 datasets drops by less than 1% and 3%, respectively.