 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAUQ: Vision-Aware Uncertainty Quantification for LVLM Self-Evaluation
Feb 24, 2026Large Vision-Language Models (LVLMs) frequently hallucinate, limiting their safe deployment in real-world applications. Existing LLM self-evaluation methods rely on a model's ability to estimate the correctness of its own outputs, which can improve deployment reliability; however, they depend heavily on language priors and are therefore ill-suited for evaluating vision-conditioned predictions. We propose VAUQ, a vision-aware uncertainty quantification framework for LVLM self-evaluation that explicitly measures how strongly a model's output depends on visual evidence. VAUQ introduces the Image-Information Score (IS), which captures the reduction in predictive uncertainty attributable to visual input, and an unsupervised core-region masking strategy that amplifies the influence of salient regions. Combining predictive entropy with this core-masked IS yields a training-free scoring function that reliably reflects answer correctness. Comprehensive experiments show that VAUQ consistently outperforms existing self-evaluation methods across multiple datasets.
Towards Reducible Uncertainty Modeling for Reliable Large Language Model Agents
Feb 04, 2026Uncertainty quantification (UQ) for large language models (LLMs) is a key building block for safety guardrails of daily LLM applications. Yet, even as LLM agents are increasingly deployed in highly complex tasks, most UQ research still centers on single-turn question-answering. We argue that UQ research must shift to realistic settings with interactive agents, and that a new principled framework for agent UQ is needed. This paper presents the first general formulation of agent UQ that subsumes broad classes of existing UQ setups. Under this formulation, we show that prior works implicitly treat LLM UQ as an uncertainty accumulation process, a viewpoint that breaks down for interactive agents in an open world. In contrast, we propose a novel perspective, a conditional uncertainty reduction process, that explicitly models reducible uncertainty over an agent's trajectory by highlighting "interactivity" of actions. From this perspective, we outline a conceptual framework to provide actionable guidance for designing UQ in LLM agent setups. Finally, we conclude with practical implications of the agent UQ in frontier LLM development and domain-specific applications, as well as open remaining problems.
Harnessing Reasoning Trajectories for Hallucination Detection via Answer-agreement Representation Shaping
Jan 24, 2026Large reasoning models (LRMs) often generate long, seemingly coherent reasoning traces yet still produce incorrect answers, making hallucination detection challenging. Although trajectories contain useful signals, directly using trace text or vanilla hidden states for detection is brittle: traces vary in form and detectors can overfit to superficial patterns rather than answer validity. We introduce Answer-agreement Representation Shaping (ARS), which learns detection-friendly trace-conditioned representations by explicitly encoding answer stability. ARS generates counterfactual answers through small latent interventions, specifically, perturbing the trace-boundary embedding, and labels each perturbation by whether the resulting answer agrees with the original. It then learns representations that bring answer-agreeing states together and separate answer-disagreeing ones, exposing latent instability indicative of hallucination risk. The shaped embeddings are plug-and-play with existing embedding-based detectors and require no human annotations during training. Experiments demonstrate that ARS consistently improves detection and achieves substantial gains over strong baselines.
Unlocking the Pre-Trained Model as a Dual-Alignment Calibrator for Post-Trained LLMs
Jan 07, 2026Post-training improves large language models (LLMs) but often worsens confidence calibration, leading to systematic overconfidence. Recent unsupervised post-hoc methods for post-trained LMs (PoLMs) mitigate this by aligning PoLM confidence to that of well-calibrated pre-trained counterparts. However, framing calibration as static output-distribution matching overlooks the inference-time dynamics introduced by post-training. In particular, we show that calibration errors arise from two regimes: (i) confidence drift, where final confidence inflates despite largely consistent intermediate decision processes, and (ii) process drift, where intermediate inference pathways diverge. Guided by this diagnosis, we propose Dual-Align, an unsupervised post-hoc framework for dual alignment in confidence calibration. Dual-Align performs confidence alignment to correct confidence drift via final-distribution matching, and introduces process alignment to address process drift by locating the layer where trajectories diverge and realigning the stability of subsequent inference. This dual strategy learns a single temperature parameter that corrects both drift types without sacrificing post-training performance gains. Experiments show consistent improvements over baselines, reducing calibration errors and approaching a supervised oracle.
Foundations of Unknown-aware Machine Learning
May 20, 2025Ensuring the reliability and safety of machine learning models in open-world deployment is a central challenge in AI safety. This thesis develops both algorithmic and theoretical foundations to address key reliability issues arising from distributional uncertainty and unknown classes, from standard neural networks to modern foundation models like large language models (LLMs). Traditional learning paradigms, such as empirical risk minimization (ERM), assume no distribution shift between training and inference, often leading to overconfident predictions on out-of-distribution (OOD) inputs. This thesis introduces novel frameworks that jointly optimize for in-distribution accuracy and reliability to unseen data. A core contribution is the development of an unknown-aware learning framework that enables models to recognize and handle novel inputs without labeled OOD data. We propose new outlier synthesis methods, VOS, NPOS, and DREAM-OOD, to generate informative unknowns during training. Building on this, we present SAL, a theoretical and algorithmic framework that leverages unlabeled in-the-wild data to enhance OOD detection under realistic deployment conditions. These methods demonstrate that abundant unlabeled data can be harnessed to recognize and adapt to unforeseen inputs, providing formal reliability guarantees. The thesis also extends reliable learning to foundation models. We develop HaloScope for hallucination detection in LLMs, MLLMGuard for defending against malicious prompts in multimodal models, and data cleaning methods to denoise human feedback used for better alignment. These tools target failure modes that threaten the safety of large-scale models in deployment. Overall, these contributions promote unknown-aware learning as a new paradigm, and we hope it can advance the reliability of AI systems with minimal human efforts.
Safety-Aware Fine-Tuning of Large Language Models
Oct 13, 2024
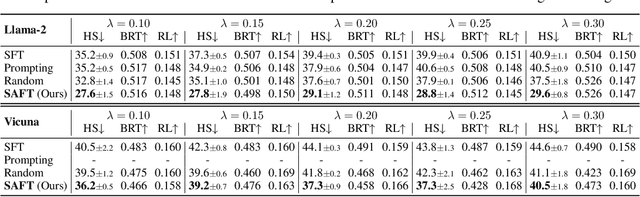

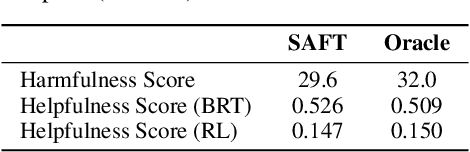
Fine-tuning Large Language Models (LLMs) has emerged as a common practice for tailoring models to individual needs and preferences. The choice of datasets for fine-tuning can be diverse, introducing safety concerns regarding the potential inclusion of harmful data samples. Manually filtering or avoiding such samples, however, can be labor-intensive and subjective. To address these difficulties, we propose a novel Safety-Aware Fine-Tuning (SAFT) framework designed to automatically detect and remove potentially harmful data, by leveraging a scoring function that exploits the subspace information of harmful and benign samples. Experimental results demonstrate the efficacy of SAFT across different LLMs and varying contamination rates, achieving reductions in harmfulness of up to 27.8%. Going beyond, we delve into the mechanism of our approach and validate its versatility in addressing practical challenges in real-world scenarios.
How Reliable Is Human Feedback For Aligning Large Language Models?
Oct 02, 2024



Most alignment research today focuses on designing new learning algorithms using datasets like Anthropic-HH, assuming human feedback data is inherently reliable. However, little attention has been given to the qualitative unreliability of human feedback and its impact on alignment. To address this gap, we conduct a comprehensive study and provide an in-depth analysis of human feedback data. We assess feedback reliability using a committee of gold reward models, revealing that over 25% of the dataset shows low or no agreement with these models, implying a high degree of unreliability. Through a qualitative analysis, we identify six key sources of unreliability, such as mis-labeling, subjective preferences, differing criteria and thresholds for helpfulness and harmlessness, etc. Lastly, to mitigate unreliability, we propose Source-Aware Cleaning, an automatic data-cleaning method guided by the insight of our qualitative analysis, to significantly improve data quality. Extensive experiments demonstrate that models trained on our cleaned dataset, HH-Clean, substantially outperform those trained on the original dataset. We release HH-Clean to support more reliable LLM alignment evaluation in the future.
HaloScope: Harnessing Unlabeled LLM Generations for Hallucination Detection
Sep 26, 2024The surge in applications of large language models (LLMs) has prompted concerns about the generation of misleading or fabricated information, known as hallucinations. Therefore, detecting hallucinations has become critical to maintaining trust in LLM-generated content. A primary challenge in learning a truthfulness classifier is the lack of a large amount of labeled truthful and hallucinated data. To address the challenge, we introduce HaloScope, a novel learning framework that leverages the unlabeled LLM generations in the wild for hallucination detection. Such unlabeled data arises freely upon deploying LLMs in the open world, and consists of both truthful and hallucinated information. To harness the unlabeled data, we present an automated membership estimation score for distinguishing between truthful and untruthful generations within unlabeled mixture data, thereby enabling the training of a binary truthfulness classifier on top. Importantly, our framework does not require extra data collection and human annotations, offering strong flexibility and practicality for real-world applications. Extensive experiments show that HaloScope can achieve superior hallucination detection performance, outperforming the competitive rivals by a significant margin. Code is available at https://github.com/deeplearningwisc/haloscope.
Out-of-Distribution Learning with Human Feedback
Aug 14, 2024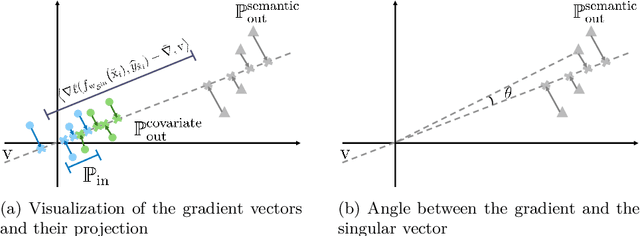
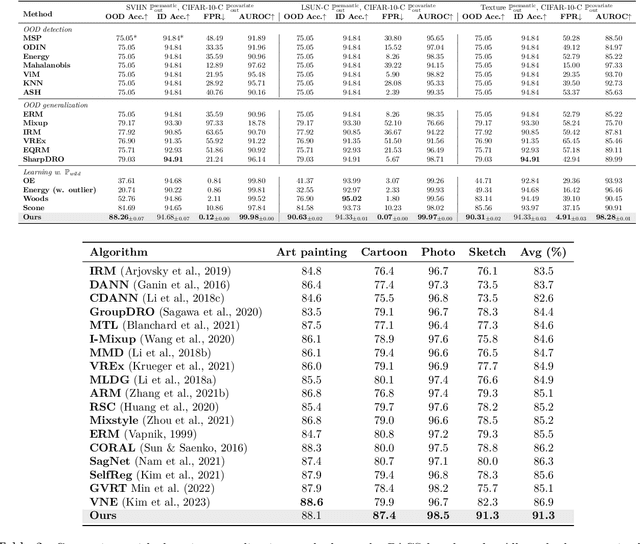
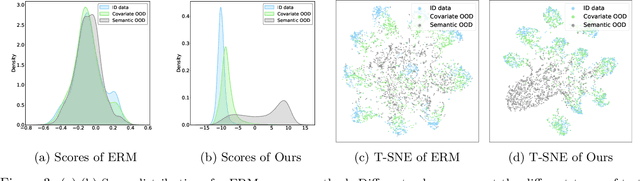

Out-of-distribution (OOD) learning often relies heavily on statistical approaches or predefined assumptions about OOD data distributions, hindering their efficacy in addressing multifaceted challenges of OOD generalization and OOD detection in real-world deployment environments. This paper presents a novel framework for OOD learning with human feedback, which can provide invaluable insights into the nature of OOD shifts and guide effective model adaptation. Our framework capitalizes on the freely available unlabeled data in the wild that captures the environmental test-time OOD distributions under both covariate and semantic shifts. To harness such data, our key idea is to selectively provide human feedback and label a small number of informative samples from the wild data distribution, which are then used to train a multi-class classifier and an OOD detector. By exploiting human feedback, we enhance the robustness and reliability of machine learning models, equipping them with the capability to handle OOD scenarios with greater precision. We provide theoretical insights on the generalization error bounds to justify our algorithm. Extensive experiments show the superiority of our method, outperforming the current state-of-the-art by a significant margin.
When and How Does In-Distribution Label Help Out-of-Distribution Detection?
May 28, 2024Detecting data points deviating from the training distribution is pivotal for ensuring reliable machine learning. Extensive research has been dedicated to the challenge, spanning classical anomaly detection techniques to contemporary out-of-distribution (OOD) detection approaches. While OOD detection commonly relies on supervised learning from a labeled in-distribution (ID) dataset, anomaly detection may treat the entire ID data as a single class and disregard ID labels. This fundamental distinction raises a significant question that has yet to be rigorously explored: when and how does ID label help OOD detection? This paper bridges this gap by offering a formal understanding to theoretically delineate the impact of ID labels on OOD detection. We employ a graph-theoretic approach, rigorously analyzing the separability of ID data from OOD data in a closed-form manner. Key to our approach is the characterization of data representations through spectral decomposition on the graph. Leveraging these representations, we establish a provable error bound that compares the OOD detection performance with and without ID labels, unveiling conditions for achieving enhanced OOD detection. Lastly, we present empirical results on both simulated and real datasets, validating theoretical guarantees and reinforcing our insights. Code is publicly available at https://github.com/deeplearning-wisc/id_label.