 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaMind: Modeling Human Social Thoughts with Metacognitive Multi-Agent Systems
May 25, 2025Human social interactions depend on the ability to infer others' unspoken intentions, emotions, and beliefs-a cognitive skill grounded in the psychological concept of Theory of Mind (ToM). While large language models (LLMs) excel in semantic understanding tasks, they struggle with the ambiguity and contextual nuance inherent in human communication. To bridge this gap, we introduce MetaMind, a multi-agent framework inspired by psychological theories of metacognition, designed to emulate human-like social reasoning. MetaMind decomposes social understanding into three collaborative stages: (1) a Theory-of-Mind Agent generates hypotheses user mental states (e.g., intent, emotion), (2) a Domain Agent refines these hypotheses using cultural norms and ethical constraints, and (3) a Response Agent generates contextually appropriate responses while validating alignment with inferred intent. Our framework achieves state-of-the-art performance across three challenging benchmarks, with 35.7% improvement in real-world social scenarios and 6.2% gain in ToM reasoning. Notably, it enables LLMs to match human-level performance on key ToM tasks for the first time. Ablation studies confirm the necessity of all components, which showcase the framework's ability to balance contextual plausibility, social appropriateness, and user adaptation. This work advances AI systems toward human-like social intelligence, with applications in empathetic dialogue and culturally sensitive interactions. Code is available at https://github.com/XMZhangAI/MetaMind.
Can Your Uncertainty Scores Detect Hallucinated Entity?
Feb 17, 2025



To mitigate the impact of hallucination nature of LLMs, many studies propose detecting hallucinated generation through uncertainty estimation. However, these approaches predominantly operate at the sentence or paragraph level, failing to pinpoint specific spans or entities responsible for hallucinated content. This lack of granularity is especially problematic for long-form outputs that mix accurate and fabricated information. To address this limitation, we explore entity-level hallucination detection. We propose a new data set, HalluEntity, which annotates hallucination at the entity level. Based on the dataset, we comprehensively evaluate uncertainty-based hallucination detection approaches across 17 modern LLMs. Our experimental results show that uncertainty estimation approaches focusing on individual token probabilities tend to over-predict hallucinations, while context-aware methods show better but still suboptimal performance. Through an in-depth qualitative study, we identify relationships between hallucination tendencies and linguistic properties and highlight important directions for future research.
CoCoLoFa: A Dataset of News Comments with Common Logical Fallacies Written by LLM-Assisted Crowds
Oct 04, 2024
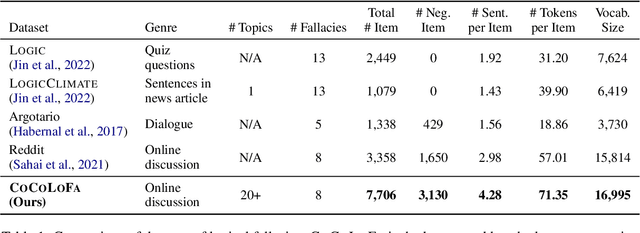
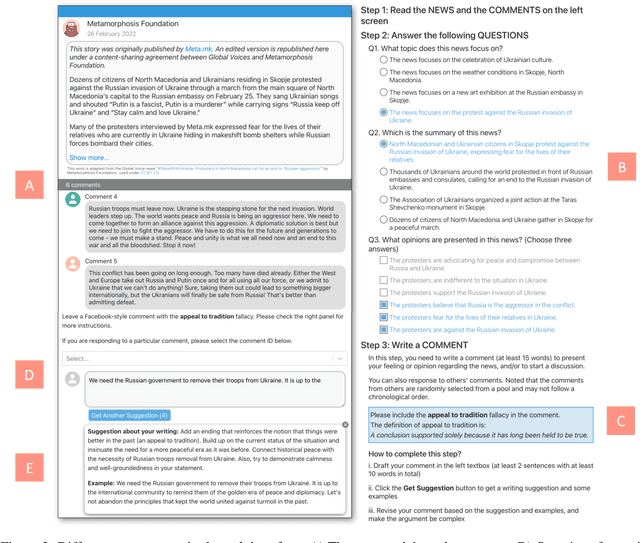
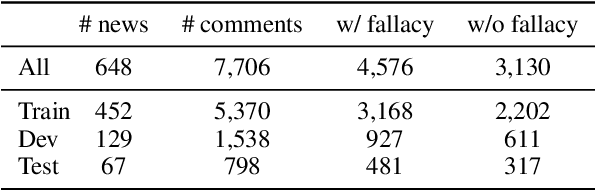
Detecting logical fallacies in texts can help users spot argument flaws, but automating this detection is not easy. Manually annotating fallacies in large-scale, real-world text data to create datasets for developing and validating detection models is costly. This paper introduces CoCoLoFa, the largest known logical fallacy dataset, containing 7,706 comments for 648 news articles, with each comment labeled for fallacy presence and type. We recruited 143 crowd workers to write comments embodying specific fallacy types (e.g., slippery slope) in response to news articles. Recognizing the complexity of this writing task, we built an LLM-powered assistant into the workers' interface to aid in drafting and refining their comments. Experts rated the writing quality and labeling validity of CoCoLoFa as high and reliable. BERT-based models fine-tuned using CoCoLoFa achieved the highest fallacy detection (F1=0.86) and classification (F1=0.87) performance on its test set, outperforming the state-of-the-art LLMs. Our work shows that combining crowdsourcing and LLMs enables us to more effectively construct datasets for complex linguistic phenomena that crowd workers find challenging to produce on their own.
How Reliable Is Human Feedback For Aligning Large Language Models?
Oct 02, 2024



Most alignment research today focuses on designing new learning algorithms using datasets like Anthropic-HH, assuming human feedback data is inherently reliable. However, little attention has been given to the qualitative unreliability of human feedback and its impact on alignment. To address this gap, we conduct a comprehensive study and provide an in-depth analysis of human feedback data. We assess feedback reliability using a committee of gold reward models, revealing that over 25% of the dataset shows low or no agreement with these models, implying a high degree of unreliability. Through a qualitative analysis, we identify six key sources of unreliability, such as mis-labeling, subjective preferences, differing criteria and thresholds for helpfulness and harmlessness, etc. Lastly, to mitigate unreliability, we propose Source-Aware Cleaning, an automatic data-cleaning method guided by the insight of our qualitative analysis, to significantly improve data quality. Extensive experiments demonstrate that models trained on our cleaned dataset, HH-Clean, substantially outperform those trained on the original dataset. We release HH-Clean to support more reliable LLM alignment evaluation in the future.
Multi-VQG: Generating Engaging Questions for Multiple Images
Nov 18, 2022


Generating engaging content has drawn much recent attention in the NLP community. Asking questions is a natural way to respond to photos and promote awareness. However, most answers to questions in traditional question-answering (QA) datasets are factoids, which reduce individuals' willingness to answer. Furthermore, traditional visual question generation (VQG) confines the source data for question generation to single images, resulting in a limited ability to comprehend time-series information of the underlying event. In this paper, we propose generating engaging questions from multiple images. We present MVQG, a new dataset, and establish a series of baselines, including both end-to-end and dual-stage architectures. Results show that building stories behind the image sequence enables models to generate engaging questions, which confirms our assumption that people typically construct a picture of the event in their minds before asking questions. These results open up an exciting challenge for visual-and-language models to implicitly construct a story behind a series of photos to allow for creativity and experience sharing and hence draw attention to downstream applications.