 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCoLoFa: A Dataset of News Comments with Common Logical Fallacies Written by LLM-Assisted Crowds
Paper and Code

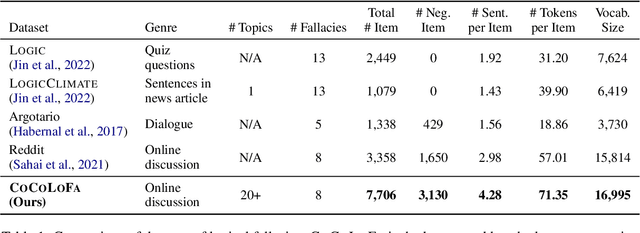
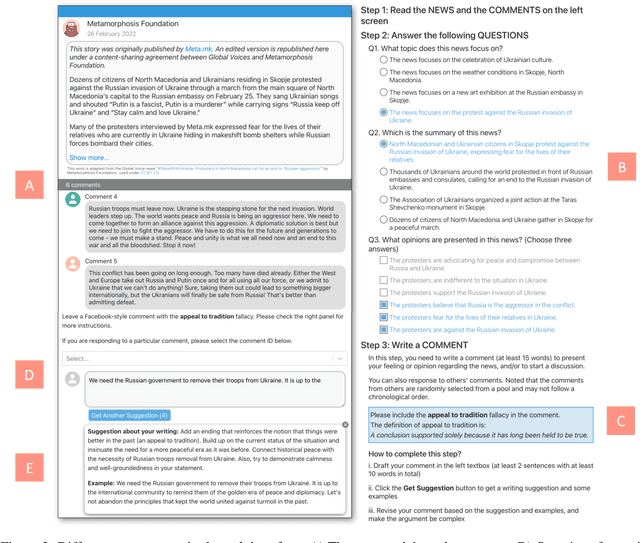
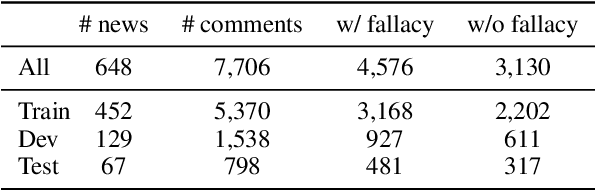
Detecting logical fallacies in texts can help users spot argument flaws, but automating this detection is not easy. Manually annotating fallacies in large-scale, real-world text data to create datasets for developing and validating detection models is costly. This paper introduces CoCoLoFa, the largest known logical fallacy dataset, containing 7,706 comments for 648 news articles, with each comment labeled for fallacy presence and type. We recruited 143 crowd workers to write comments embodying specific fallacy types (e.g., slippery slope) in response to news articles. Recognizing the complexity of this writing task, we built an LLM-powered assistant into the workers' interface to aid in drafting and refining their comments. Experts rated the writing quality and labeling validity of CoCoLoFa as high and reliable. BERT-based models fine-tuned using CoCoLoFa achieved the highest fallacy detection (F1=0.86) and classification (F1=0.87) performance on its test set, outperforming the state-of-the-art LLMs. Our work shows that combining crowdsourcing and LLMs enables us to more effectively construct datasets for complex linguistic phenomena that crowd workers find challenging to produce on their own.