 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Reinforcement: When Reward Is Sparse, It's Better to Be Dense
Oct 08, 2025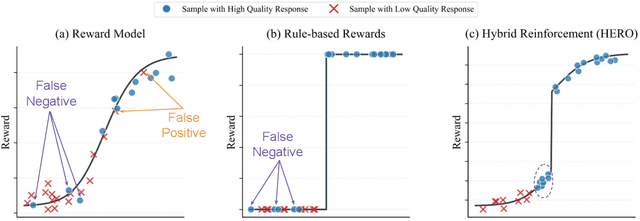
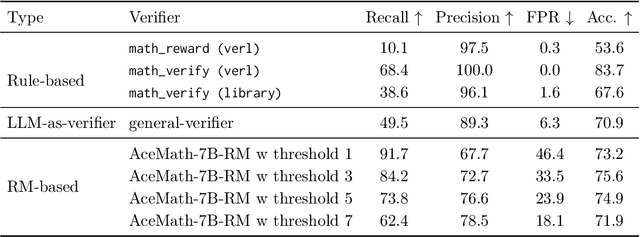
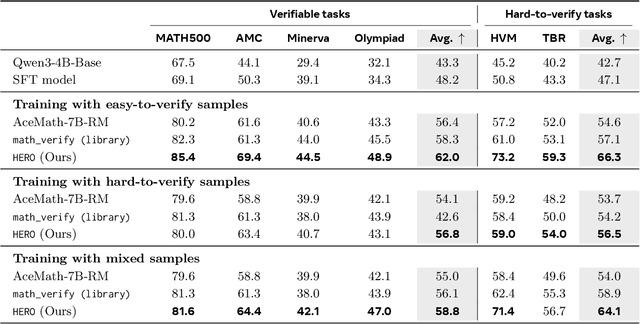
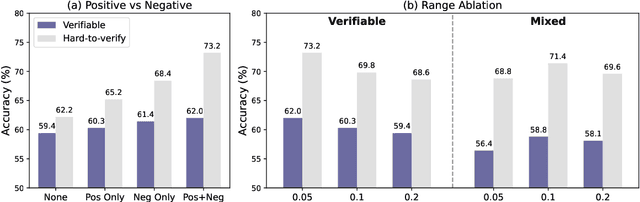
Post-training for reasoning of large language models (LLMs) increasingly relies on verifiable rewards: deterministic checkers that provide 0-1 correctness signals. While reliable, such binary feedback is brittle--many tasks admit partially correct or alternative answers that verifiers under-credit, and the resulting all-or-nothing supervision limits learning. Reward models offer richer, continuous feedback, which can serve as a complementary supervisory signal to verifiers. We introduce HERO (Hybrid Ensemble Reward Optimization), a reinforcement learning framework that integrates verifier signals with reward-model scores in a structured way. HERO employs stratified normalization to bound reward-model scores within verifier-defined groups, preserving correctness while refining quality distinctions, and variance-aware weighting to emphasize challenging prompts where dense signals matter most. Across diverse mathematical reasoning benchmarks, HERO consistently outperforms RM-only and verifier-only baselines, with strong gains on both verifiable and hard-to-verify tasks. Our results show that hybrid reward design retains the stability of verifiers while leveraging the nuance of reward models to advance reasoning.
RESTRAIN: From Spurious Votes to Signals -- Self-Driven RL with Self-Penalization
Oct 02, 2025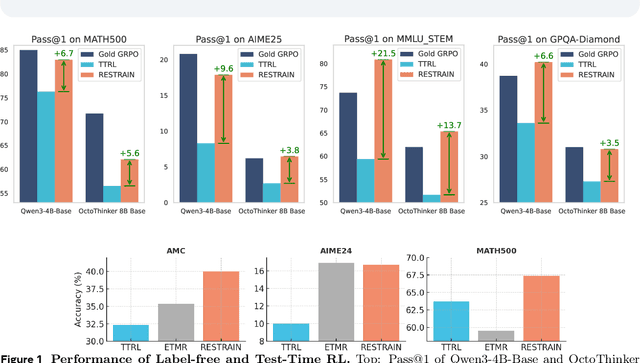
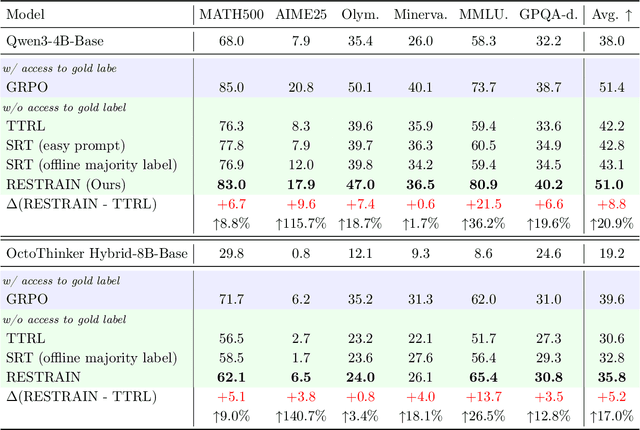
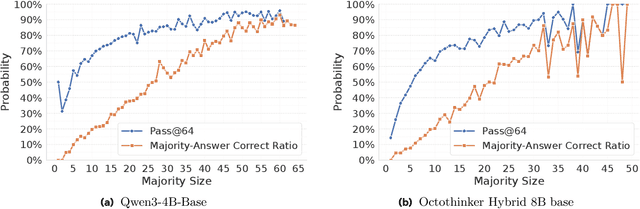
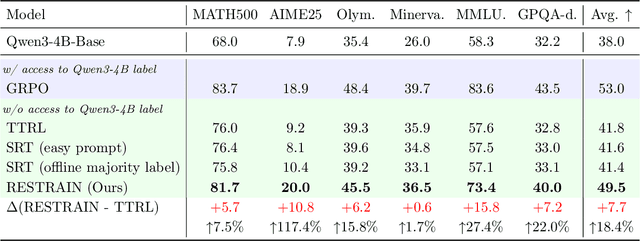
Reinforcement learning with human-annotated data has boosted chain-of-thought reasoning in large reasoning models, but these gains come at high costs in labeled data while faltering on harder tasks. A natural next step is experience-driven learning, where models improve without curated labels by adapting to unlabeled data. We introduce RESTRAIN (REinforcement learning with Self-restraint), a self-penalizing RL framework that converts the absence of gold labels into a useful learning signal. Instead of overcommitting to spurious majority votes, RESTRAIN exploits signals from the model's entire answer distribution: penalizing overconfident rollouts and low-consistency examples while preserving promising reasoning chains. The self-penalization mechanism integrates seamlessly into policy optimization methods such as GRPO, enabling continual self-improvement without supervision. On challenging reasoning benchmarks, RESTRAIN delivers large gains using only unlabeled data. With Qwen3-4B-Base and OctoThinker Hybrid-8B-Base, it improves Pass@1 by up to +140.7 percent on AIME25, +36.2 percent on MMLU_STEM, and +19.6 percent on GPQA-Diamond, nearly matching gold-label training while using no gold labels. These results demonstrate that RESTRAIN establishes a scalable path toward stronger reasoning without gold labels.
CodeLutra: Boosting LLM Code Generation via Preference-Guided Refinement
Nov 07, 2024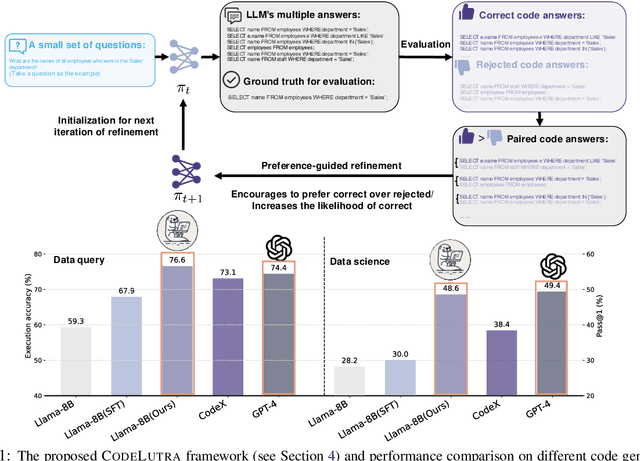



Large Language Models (LLMs) have significantly advanced code generation but often require substantial resources and tend to over-generalize, limiting their efficiency for specific tasks. Fine-tuning smaller, open-source LLMs presents a viable alternative; however, it typically lags behind cutting-edge models due to supervised fine-tuning's reliance solely on correct code examples, which restricts the model's ability to learn from its own mistakes and adapt to diverse programming challenges. To bridge this gap, we introduce CodeLutra, a novel framework that enhances low-performing LLMs by leveraging both successful and failed code generation attempts. Unlike conventional fine-tuning, CodeLutra employs an iterative preference learning mechanism to compare correct and incorrect solutions as well as maximize the likelihood of correct codes. Through continuous iterative refinement, CodeLutra enables smaller LLMs to match or surpass GPT-4's performance in various code generation tasks without relying on vast external datasets or larger auxiliary models. On a challenging data analysis task, using just 500 samples improved Llama-3-8B's accuracy from 28.2% to 48.6%, approaching GPT-4's performance. These results highlight CodeLutra's potential to close the gap between open-source and closed-source models, making it a promising approach in the field of code generation.
How Reliable Is Human Feedback For Aligning Large Language Models?
Oct 02, 2024



Most alignment research today focuses on designing new learning algorithms using datasets like Anthropic-HH, assuming human feedback data is inherently reliable. However, little attention has been given to the qualitative unreliability of human feedback and its impact on alignment. To address this gap, we conduct a comprehensive study and provide an in-depth analysis of human feedback data. We assess feedback reliability using a committee of gold reward models, revealing that over 25% of the dataset shows low or no agreement with these models, implying a high degree of unreliability. Through a qualitative analysis, we identify six key sources of unreliability, such as mis-labeling, subjective preferences, differing criteria and thresholds for helpfulness and harmlessness, etc. Lastly, to mitigate unreliability, we propose Source-Aware Cleaning, an automatic data-cleaning method guided by the insight of our qualitative analysis, to significantly improve data quality. Extensive experiments demonstrate that models trained on our cleaned dataset, HH-Clean, substantially outperform those trained on the original dataset. We release HH-Clean to support more reliable LLM alignment evaluation in the future.
Your Weak LLM is Secretly a Strong Teacher for Alignment
Sep 13, 2024The burgeoning capabilities of large language models (LLMs) have underscored the need for alignment to ensure these models act in accordance with human values and intentions. Existing alignment frameworks present constraints either in the form of expensive human effort or high computational costs. This paper explores a promising middle ground, where we employ a weak LLM that is significantly less resource-intensive than top-tier models, yet offers more automation than purely human feedback. We present a systematic study to evaluate and understand weak LLM's ability to generate feedback for alignment. Our empirical findings demonstrate that weak LLMs can provide feedback that rivals or even exceeds that of fully human-annotated data. Our study indicates a minimized impact of model size on feedback efficacy, shedding light on a scalable and sustainable alignment strategy. To deepen our understanding of alignment under weak LLM feedback, we conduct a series of qualitative and quantitative analyses, offering novel insights into the quality discrepancies between human feedback vs. weak LLM feedback.
Activate and Reject: Towards Safe Domain Generalization under Category Shift
Oct 07, 2023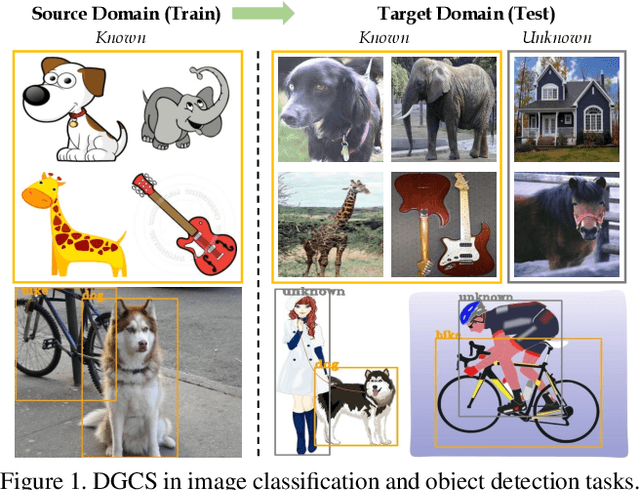

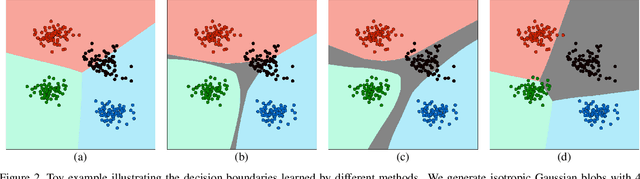
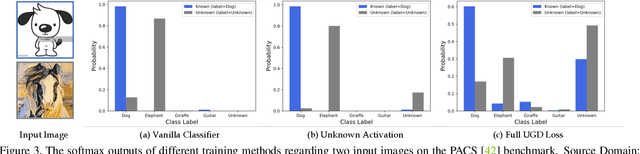
Albeit the notable performance on in-domain test points, it is non-trivial for deep neural networks to attain satisfactory accuracy when deploying in the open world, where novel domains and object classes often occur. In this paper, we study a practical problem of Domain Generalization under Category Shift (DGCS), which aims to simultaneously detect unknown-class samples and classify known-class samples in the target domains. Compared to prior DG works, we face two new challenges: 1) how to learn the concept of ``unknown'' during training with only source known-class samples, and 2) how to adapt the source-trained model to unseen environments for safe model deployment. To this end, we propose a novel Activate and Reject (ART) framework to reshape the model's decision boundary to accommodate unknown classes and conduct post hoc modification to further discriminate known and unknown classes using unlabeled test data. Specifically, during training, we promote the response to the unknown by optimizing the unknown probability and then smoothing the overall output to mitigate the overconfidence issue. At test time, we introduce a step-wise online adaptation method that predicts the label by virtue of the cross-domain nearest neighbor and class prototype information without updating the network's parameters or using threshold-based mechanisms. Experiments reveal that ART consistently improves the generalization capability of deep networks on different vision tasks. For image classification, ART improves the H-score by 6.1% on average compared to the previous best method. For object detection and semantic segmentation, we establish new benchmarks and achieve competitive performance.
Non-Parametric Outlier Synthesis
Mar 06, 2023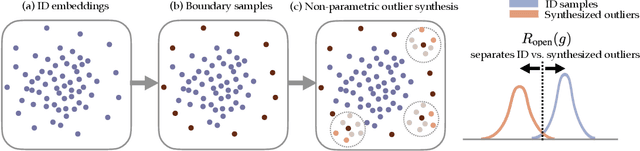
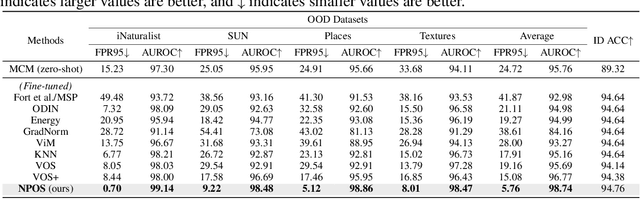
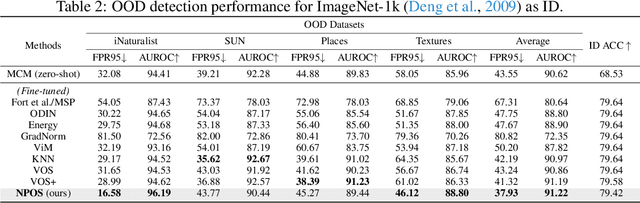
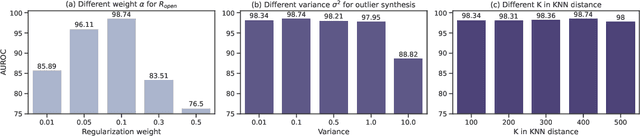
Out-of-distribution (OOD) detection is indispensable for safely deploying machine learning models in the wild. One of the key challenges is that models lack supervision signals from unknown data, and as a result, can produce overconfident predictions on OOD data. Recent work on outlier synthesis modeled the feature space as parametric Gaussian distribution, a strong and restrictive assumption that might not hold in reality. In this paper, we propose a novel framework, Non-Parametric Outlier Synthesis (NPOS), which generates artificial OOD training data and facilitates learning a reliable decision boundary between ID and OOD data. Importantly, our proposed synthesis approach does not make any distributional assumption on the ID embeddings, thereby offering strong flexibility and generality. We show that our synthesis approach can be mathematically interpreted as a rejection sampling framework. Extensive experiments show that NPOS can achieve superior OOD detection performance, outperforming the competitive rivals by a significant margin. Code is publicly available at https://github.com/deeplearning-wisc/npos.
Pyramid Feature Alignment Network for Video Deblurring
Mar 28, 2022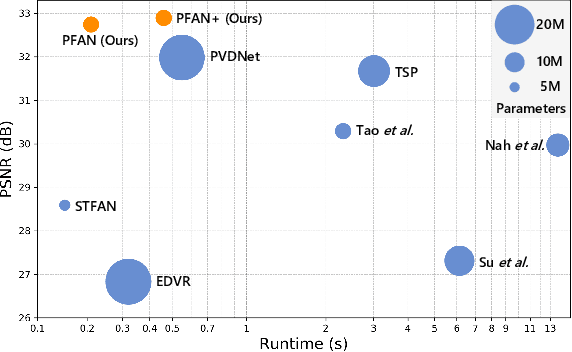
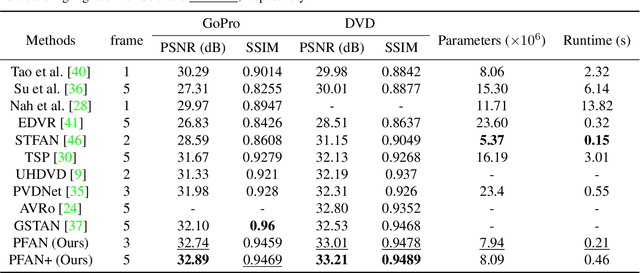
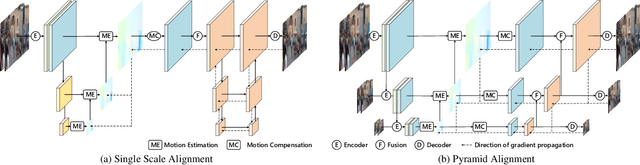

Video deblurring remains a challenging task due to various causes of blurring. Traditional methods have considered how to utilize neighboring frames by the single-scale alignment for restoration. However, they typically suffer from misalignment caused by severe blur. In this work, we aim to better utilize neighboring frames with high efficient feature alignment. We propose a Pyramid Feature Alignment Network (PFAN) for video deblurring. First, the multi-scale feature of blurry frames is extracted with the strategy of Structure-to-Detail Downsampling (SDD) before alignment. This downsampling strategy makes the edges sharper, which is helpful for alignment. Then we align the feature at each scale and reconstruct the image at the corresponding scale. This strategy effectively supervises the alignment at each scale, overcoming the problem of propagated errors from the above scales at the alignment stage. To better handle the challenges of complex and large motions, instead of aligning features at each scale separately, lower-scale motion information is used to guide the higher-scale motion estimation. Accordingly, a Cascade Guided Deformable Alignment (CGDA) is proposed to integrate coarse motion into deformable convolution for finer and more accurate alignment. As demonstrated in extensive experiments, our proposed PFAN achieves superior performance with competitive speed compared to the state-of-the-art methods.
Predicate correlation learning for scene graph generation
Jul 06, 2021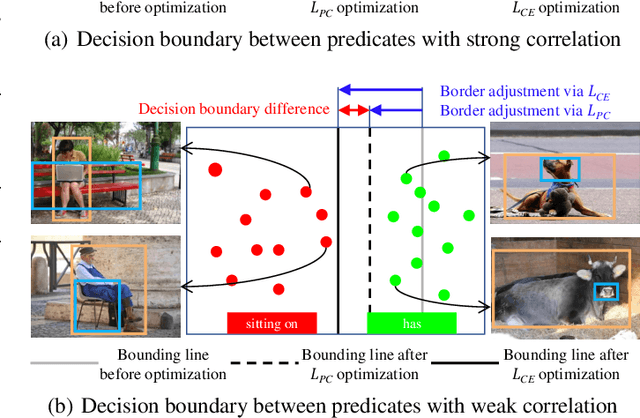
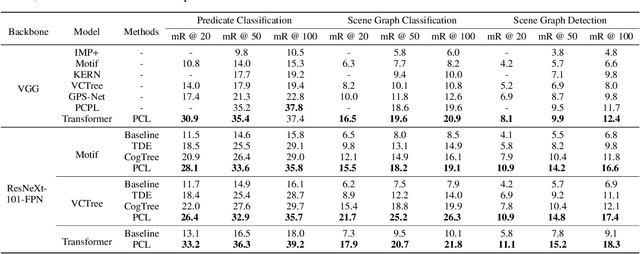
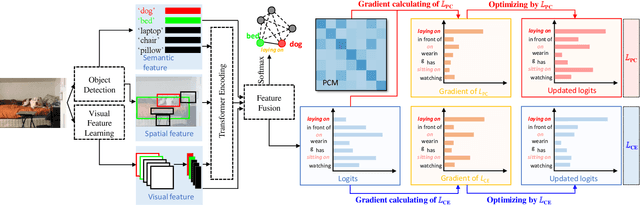
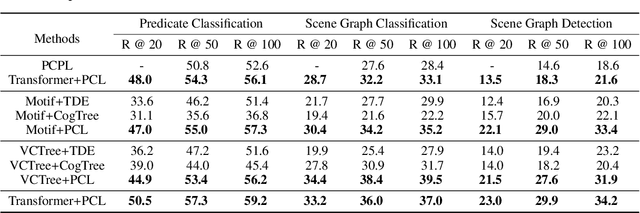
For a typical Scene Graph Generation (SGG) method, there is often a large gap in the performance of the predicates' head classes and tail classes. This phenomenon is mainly caused by the semantic overlap between different predicates as well as the long-tailed data distribution. In this paper, a Predicate Correlation Learning (PCL) method for SGG is proposed to address the above two problems by taking the correlation between predicates into consideration. To describe the semantic overlap between strong-correlated predicate classes, a Predicate Correlation Matrix (PCM) is defined to quantify the relationship between predicate pairs, which is dynamically updated to remove the matrix's long-tailed bias. In addition, PCM is integrated into a Predicate Correlation Loss function ($L_{PC}$) to reduce discouraging gradients of unannotated classes. The proposed method is evaluated on Visual Genome benchmark, where the performance of the tail classes is significantly improved when built on the existing methods.