 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestions beyond Pixels: Integrating Commonsense Knowledge in Visual Question Generation for Remote Sensing
Feb 22, 2026With the rapid development of remote sensing image archives, asking questions about images has become an effective way of gathering specific information or performing semantic image retrieval. However, current automatically generated questions tend to be simplistic and template-based, which hinders the deployment of question answering or visual dialogue systems for real-world applications. To enrich and diversify the questions with both image content and commonsense knowledge, we propose a Knowledge-aware Remote Sensing Visual Question Generation model (KRSVQG). The proposed model incorporates related knowledge triplets from external knowledge sources to broaden the question content, while employing image captioning as an intermediary representation to ground questions to the corresponding images. Moreover, KRSVQG utilizes a vision-language pre-training and fine-tuning strategy, enabling the model's adaptation to low data regimes. To evaluate the proposed KRSVQG model, we construct two knowledge-aware remote sensing visual question generation datasets: the NWPU-300 dataset and the TextRS-300 dataset. Evaluations, including metrics and human assessment, demonstrate that KRSVQG outperforms existing methods and leads to rich questions, grounded in both image and domain knowledge. As a key practice in vision-language research, knowledge-aware visual question generation advances the understanding of image content beyond pixels, facilitating the development of knowledge-enriched vision-language systems with vision-grounded human commonsense.
Knowledge-aware Visual Question Generation for Remote Sensing Images
Feb 22, 2026With the rapid development of remote sensing image archives, asking questions about images has become an effective way of gathering specific information or performing image retrieval. However, automatically generated image-based questions tend to be simplistic and template-based, which hinders the real deployment of question answering or visual dialogue systems. To enrich and diversify the questions, we propose a knowledge-aware remote sensing visual question generation model, KRSVQG, that incorporates external knowledge related to the image content to improve the quality and contextual understanding of the generated questions. The model takes an image and a related knowledge triplet from external knowledge sources as inputs and leverages image captioning as an intermediary representation to enhance the image grounding of the generated questions. To assess the performance of KRSVQG, we utilized two datasets that we manually annotated: NWPU-300 and TextRS-300. Results on these two datasets demonstrate that KRSVQG outperforms existing methods and leads to knowledge-enriched questions, grounded in both image and domain knowledge.
SPARC: Separating Perception And Reasoning Circuits for Test-time Scaling of VLMs
Feb 06, 2026Despite recent successes, test-time scaling - i.e., dynamically expanding the token budget during inference as needed - remains brittle for vision-language models (VLMs): unstructured chains-of-thought about images entangle perception and reasoning, leading to long, disorganized contexts where small perceptual mistakes may cascade into completely wrong answers. Moreover, expensive reinforcement learning with hand-crafted rewards is required to achieve good performance. Here, we introduce SPARC (Separating Perception And Reasoning Circuits), a modular framework that explicitly decouples visual perception from reasoning. Inspired by sequential sensory-to-cognitive processing in the brain, SPARC implements a two-stage pipeline where the model first performs explicit visual search to localize question-relevant regions, then conditions its reasoning on those regions to produce the final answer. This separation enables independent test-time scaling with asymmetric compute allocation (e.g., prioritizing perceptual processing under distribution shift), supports selective optimization (e.g., improving the perceptual stage alone when it is the bottleneck for end-to-end performance), and accommodates compressed contexts by running global search at lower image resolutions and allocating high-resolution processing only to selected regions, thereby reducing total visual tokens count and compute. Across challenging visual reasoning benchmarks, SPARC outperforms monolithic baselines and strong visual-grounding approaches. For instance, SPARC improves the accuracy of Qwen3VL-4B on the $V^*$ VQA benchmark by 6.7 percentage points, and it surpasses "thinking with images" by 4.6 points on a challenging OOD task despite requiring a 200$\times$ lower token budget.
GeoExplorer: Active Geo-localization with Curiosity-Driven Exploration
Jul 31, 2025Active Geo-localization (AGL) is the task of localizing a goal, represented in various modalities (e.g., aerial images, ground-level images, or text), within a predefined search area. Current methods approach AGL as a goal-reaching reinforcement learning (RL) problem with a distance-based reward. They localize the goal by implicitly learning to minimize the relative distance from it. However, when distance estimation becomes challenging or when encountering unseen targets and environments, the agent exhibits reduced robustness and generalization ability due to the less reliable exploration strategy learned during training. In this paper, we propose GeoExplorer, an AGL agent that incorporates curiosity-driven exploration through intrinsic rewards. Unlike distance-based rewards, our curiosity-driven reward is goal-agnostic, enabling robust, diverse, and contextually relevant exploration based on effective environment modeling. These capabilities have been proven through extensive experiments across four AGL benchmarks, demonstrating the effectiveness and generalization ability of GeoExplorer in diverse settings, particularly in localizing unfamiliar targets and environments.
VinaBench: Benchmark for Faithful and Consistent Visual Narratives
Mar 26, 2025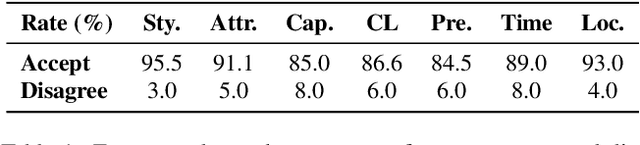
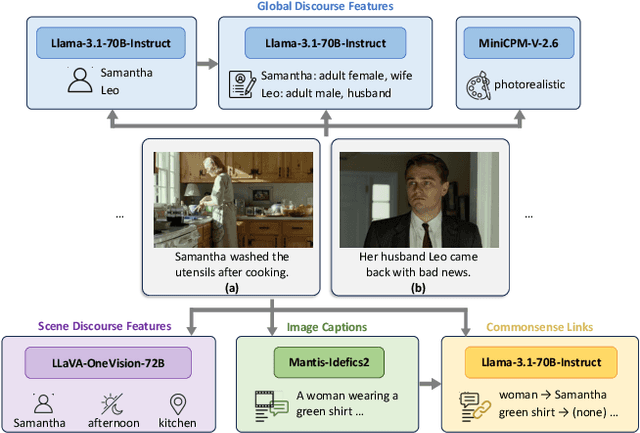
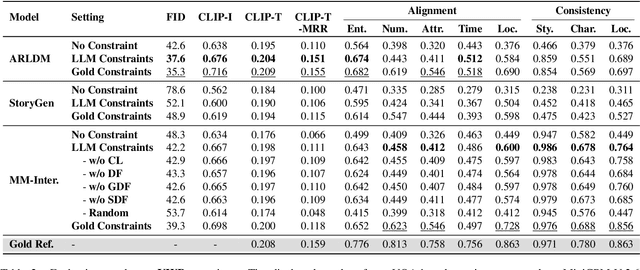
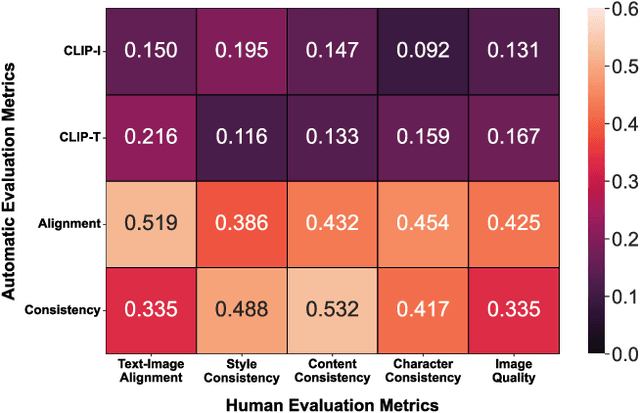
Visual narrative generation transforms textual narratives into sequences of images illustrating the content of the text. However, generating visual narratives that are faithful to the input text and self-consistent across generated images remains an open challenge, due to the lack of knowledge constraints used for planning the stories. In this work, we propose a new benchmark, VinaBench, to address this challenge. Our benchmark annotates the underlying commonsense and discourse constraints in visual narrative samples, offering systematic scaffolds for learning the implicit strategies of visual storytelling. Based on the incorporated narrative constraints, we further propose novel metrics to closely evaluate the consistency of generated narrative images and the alignment of generations with the input textual narrative. Our results across three generative vision models demonstrate that learning with VinaBench's knowledge constraints effectively improves the faithfulness and cohesion of generated visual narratives.
Unsupervised Multi-view UAV Image Geo-localization via Iterative Rendering
Nov 22, 2024



Unmanned Aerial Vehicle (UAV) Cross-View Geo-Localization (CVGL) presents significant challenges due to the view discrepancy between oblique UAV images and overhead satellite images. Existing methods heavily rely on the supervision of labeled datasets to extract viewpoint-invariant features for cross-view retrieval. However, these methods have expensive training costs and tend to overfit the region-specific cues, showing limited generalizability to new regions. To overcome this issue, we propose an unsupervised solution that lifts the scene representation to 3d space from UAV observations for satellite image generation, providing robust representation against view distortion. By generating orthogonal images that closely resemble satellite views, our method reduces view discrepancies in feature representation and mitigates shortcuts in region-specific image pairing. To further align the rendered image's perspective with the real one, we design an iterative camera pose updating mechanism that progressively modulates the rendered query image with potential satellite targets, eliminating spatial offsets relative to the reference images. Additionally, this iterative refinement strategy enhances cross-view feature invariance through view-consistent fusion across iterations. As such, our unsupervised paradigm naturally avoids the problem of region-specific overfitting, enabling generic CVGL for UAV images without feature fine-tuning or data-driven training. Experiments on the University-1652 and SUES-200 datasets demonstrate that our approach significantly improves geo-localization accuracy while maintaining robustness across diverse regions. Notably, without model fine-tuning or paired training, our method achieves competitive performance with recent supervised methods.
Knowledge-aware Text-Image Retrieval for Remote Sensing Images
May 06, 2024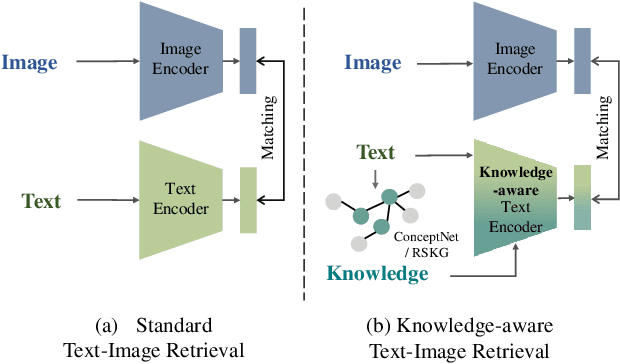
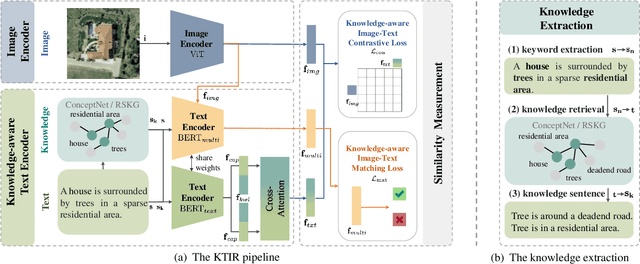

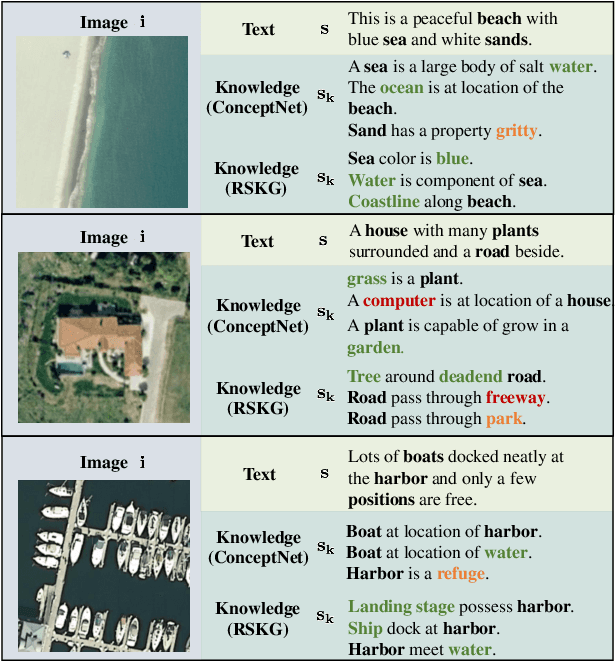
Image-based retrieval in large Earth observation archives is challenging because one needs to navigate across thousands of candidate matches only with the query image as a guide. By using text as information supporting the visual query, the retrieval system gains in usability, but at the same time faces difficulties due to the diversity of visual signals that cannot be summarized by a short caption only. For this reason, as a matching-based task, cross-modal text-image retrieval often suffers from information asymmetry between texts and images. To address this challenge, we propose a Knowledge-aware Text-Image Retrieval (KTIR) method for remote sensing images. By mining relevant information from an external knowledge graph, KTIR enriches the text scope available in the search query and alleviates the information gaps between texts and images for better matching. Moreover, by integrating domain-specific knowledge, KTIR also enhances the adaptation of pre-trained vision-language models to remote sensing applications. Experimental results on three commonly used remote sensing text-image retrieval benchmarks show that the proposed knowledge-aware method leads to varied and consistent retrievals, outperforming state-of-the-art retrieval methods.
ConGeo: Robust Cross-view Geo-localization across Ground View Variations
Mar 20, 2024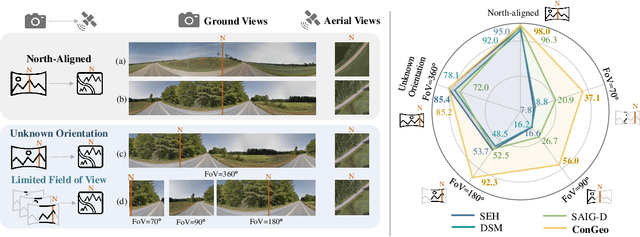
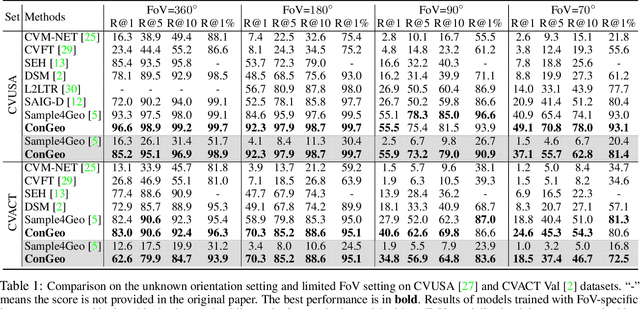
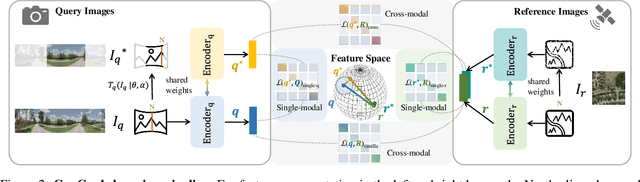

Cross-view geo-localization aims at localizing a ground-level query image by matching it to its corresponding geo-referenced aerial view. In real-world scenarios, the task requires accommodating diverse ground images captured by users with varying orientations and reduced field of views (FoVs). However, existing learning pipelines are orientation-specific or FoV-specific, demanding separate model training for different ground view variations. Such models heavily depend on the North-aligned spatial correspondence and predefined FoVs in the training data, compromising their robustness across different settings. To tackle this challenge, we propose ConGeo, a single- and cross-modal Contrastive method for Geo-localization: it enhances robustness and consistency in feature representations to improve a model's invariance to orientation and its resilience to FoV variations, by enforcing proximity between ground view variations of the same location. As a generic learning objective for cross-view geo-localization, when integrated into state-of-the-art pipelines, ConGeo significantly boosts the performance of three base models on four geo-localization benchmarks for diverse ground view variations and outperforms competing methods that train separate models for each ground view variation.
ConVQG: Contrastive Visual Question Generation with Multimodal Guidance
Feb 20, 2024



Asking questions about visual environments is a crucial way for intelligent agents to understand rich multi-faceted scenes, raising the importance of Visual Question Generation (VQG) systems. Apart from being grounded to the image, existing VQG systems can use textual constraints, such as expected answers or knowledge triplets, to generate focused questions. These constraints allow VQG systems to specify the question content or leverage external commonsense knowledge that can not be obtained from the image content only. However, generating focused questions using textual constraints while enforcing a high relevance to the image content remains a challenge, as VQG systems often ignore one or both forms of grounding. In this work, we propose Contrastive Visual Question Generation (ConVQG), a method using a dual contrastive objective to discriminate questions generated using both modalities from those based on a single one. Experiments on both knowledge-aware and standard VQG benchmarks demonstrate that ConVQG outperforms the state-of-the-art methods and generates image-grounded, text-guided, and knowledge-rich questions. Our human evaluation results also show preference for ConVQG questions compared to non-contrastive baselines.
Predicate correlation learning for scene graph generation
Jul 06, 2021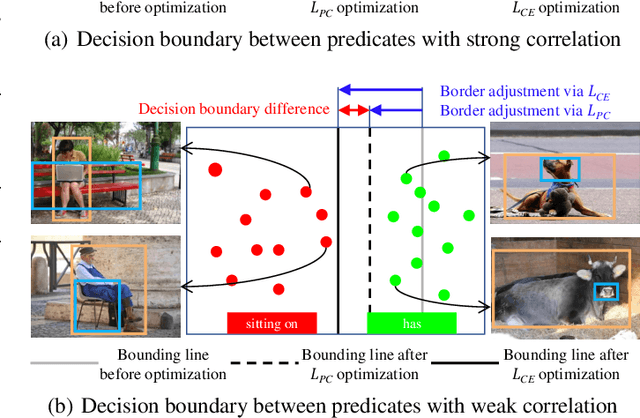
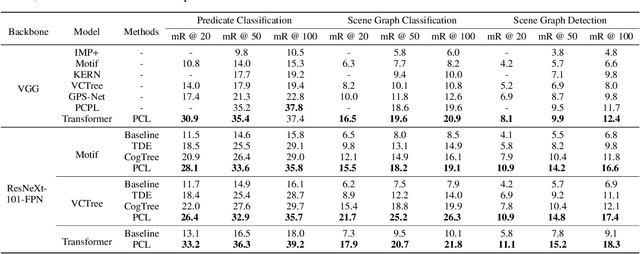
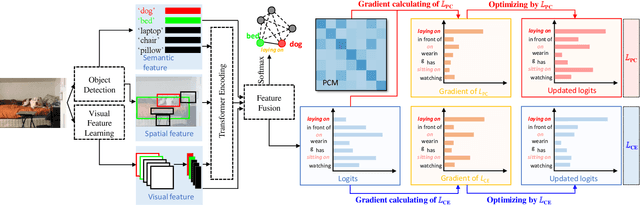
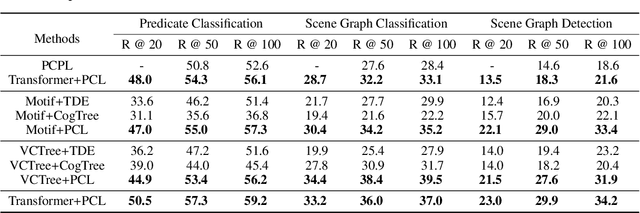
For a typical Scene Graph Generation (SGG) method, there is often a large gap in the performance of the predicates' head classes and tail classes. This phenomenon is mainly caused by the semantic overlap between different predicates as well as the long-tailed data distribution. In this paper, a Predicate Correlation Learning (PCL) method for SGG is proposed to address the above two problems by taking the correlation between predicates into consideration. To describe the semantic overlap between strong-correlated predicate classes, a Predicate Correlation Matrix (PCM) is defined to quantify the relationship between predicate pairs, which is dynamically updated to remove the matrix's long-tailed bias. In addition, PCM is integrated into a Predicate Correlation Loss function ($L_{PC}$) to reduce discouraging gradients of unannotated classes. The proposed method is evaluated on Visual Genome benchmark, where the performance of the tail classes is significantly improved when built on the existing methods.