 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-aware Text-Image Retrieval for Remote Sensing Images
May 06, 2024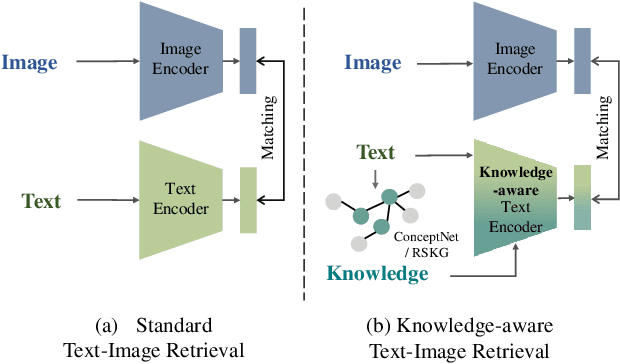
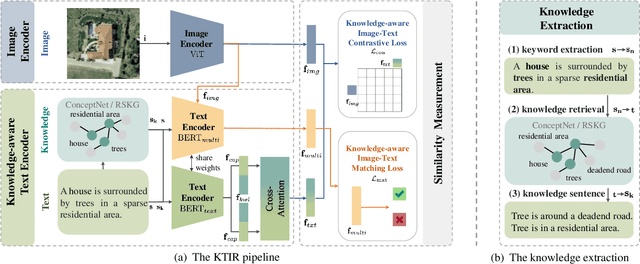

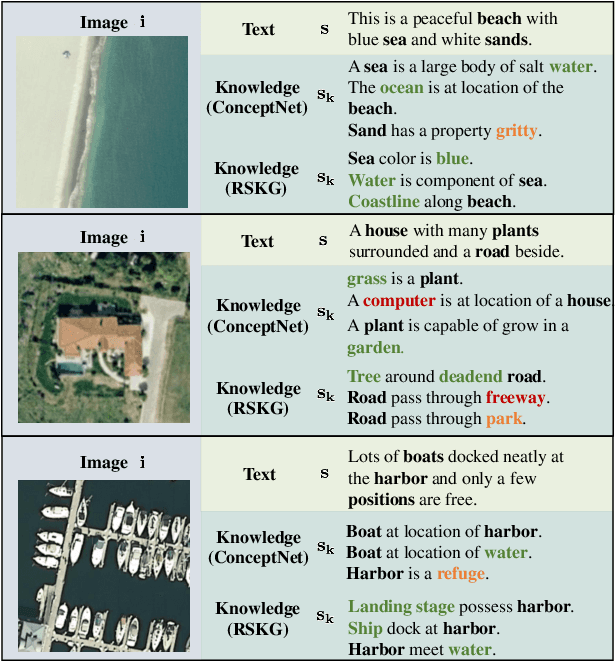
Image-based retrieval in large Earth observation archives is challenging because one needs to navigate across thousands of candidate matches only with the query image as a guide. By using text as information supporting the visual query, the retrieval system gains in usability, but at the same time faces difficulties due to the diversity of visual signals that cannot be summarized by a short caption only. For this reason, as a matching-based task, cross-modal text-image retrieval often suffers from information asymmetry between texts and images. To address this challenge, we propose a Knowledge-aware Text-Image Retrieval (KTIR) method for remote sensing images. By mining relevant information from an external knowledge graph, KTIR enriches the text scope available in the search query and alleviates the information gaps between texts and images for better matching. Moreover, by integrating domain-specific knowledge, KTIR also enhances the adaptation of pre-trained vision-language models to remote sensing applications. Experimental results on three commonly used remote sensing text-image retrieval benchmarks show that the proposed knowledge-aware method leads to varied and consistent retrievals, outperforming state-of-the-art retrieval methods.
ConVQG: Contrastive Visual Question Generation with Multimodal Guidance
Feb 20, 2024



Asking questions about visual environments is a crucial way for intelligent agents to understand rich multi-faceted scenes, raising the importance of Visual Question Generation (VQG) systems. Apart from being grounded to the image, existing VQG systems can use textual constraints, such as expected answers or knowledge triplets, to generate focused questions. These constraints allow VQG systems to specify the question content or leverage external commonsense knowledge that can not be obtained from the image content only. However, generating focused questions using textual constraints while enforcing a high relevance to the image content remains a challenge, as VQG systems often ignore one or both forms of grounding. In this work, we propose Contrastive Visual Question Generation (ConVQG), a method using a dual contrastive objective to discriminate questions generated using both modalities from those based on a single one. Experiments on both knowledge-aware and standard VQG benchmarks demonstrate that ConVQG outperforms the state-of-the-art methods and generates image-grounded, text-guided, and knowledge-rich questions. Our human evaluation results also show preference for ConVQG questions compared to non-contrastive baselines.