 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcoWikiRS: Learning Ecological Representation of Satellite Images from Weak Supervision with Species Observations and Wikipedia
Apr 28, 2025The presence of species provides key insights into the ecological properties of a location such as land cover, climatic conditions or even soil properties. We propose a method to predict such ecological properties directly from remote sensing (RS) images by aligning them with species habitat descriptions. We introduce the EcoWikiRS dataset, consisting of high-resolution aerial images, the corresponding geolocated species observations, and, for each species, the textual descriptions of their habitat from Wikipedia. EcoWikiRS offers a scalable way of supervision for RS vision language models (RS-VLMs) for ecology. This is a setting with weak and noisy supervision, where, for instance, some text may describe properties that are specific only to part of the species' niche or is irrelevant to a specific image. We tackle this by proposing WINCEL, a weighted version of the InfoNCE loss. We evaluate our model on the task of ecosystem zero-shot classification by following the habitat definitions from the European Nature Information System (EUNIS). Our results show that our approach helps in understanding RS images in a more ecologically meaningful manner. The code and the dataset are available at https://github.com/eceo-epfl/EcoWikiRS.
What to align in multimodal contrastive learning?
Sep 11, 2024Humans perceive the world through multisensory integration, blending the information of different modalities to adapt their behavior. Contrastive learning offers an appealing solution for multimodal self-supervised learning. Indeed, by considering each modality as a different view of the same entity, it learns to align features of different modalities in a shared representation space. However, this approach is intrinsically limited as it only learns shared or redundant information between modalities, while multimodal interactions can arise in other ways. In this work, we introduce CoMM, a Contrastive MultiModal learning strategy that enables the communication between modalities in a single multimodal space. Instead of imposing cross- or intra- modality constraints, we propose to align multimodal representations by maximizing the mutual information between augmented versions of these multimodal features. Our theoretical analysis shows that shared, synergistic and unique terms of information naturally emerge from this formulation, allowing us to estimate multimodal interactions beyond redundancy. We test CoMM both in a controlled and in a series of real-world settings: in the former, we demonstrate that CoMM effectively captures redundant, unique and synergistic information between modalities. In the latter, CoMM learns complex multimodal interactions and achieves state-of-the-art results on the six multimodal benchmarks.
Knowledge-aware Text-Image Retrieval for Remote Sensing Images
May 06, 2024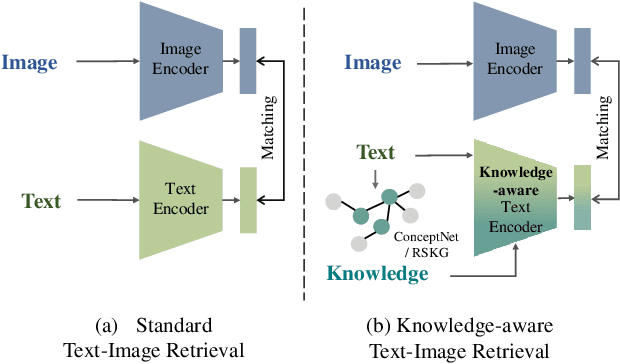
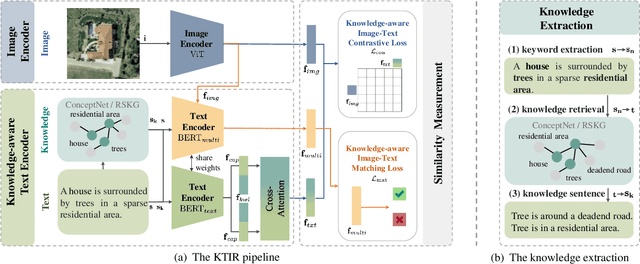

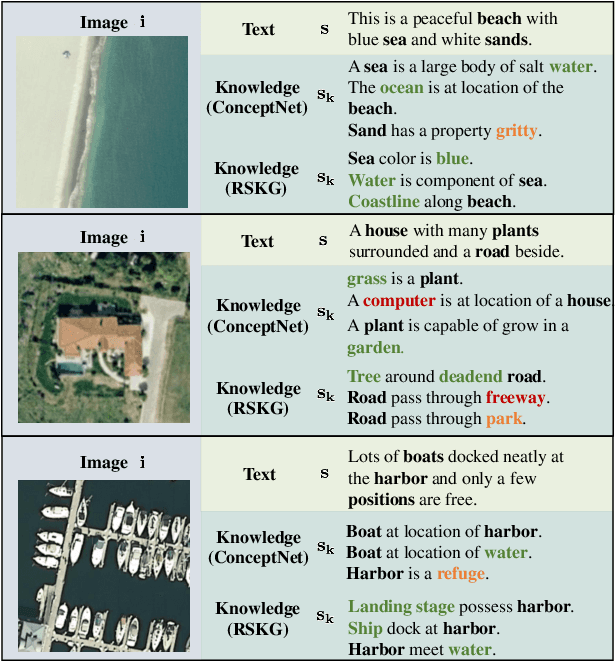
Image-based retrieval in large Earth observation archives is challenging because one needs to navigate across thousands of candidate matches only with the query image as a guide. By using text as information supporting the visual query, the retrieval system gains in usability, but at the same time faces difficulties due to the diversity of visual signals that cannot be summarized by a short caption only. For this reason, as a matching-based task, cross-modal text-image retrieval often suffers from information asymmetry between texts and images. To address this challenge, we propose a Knowledge-aware Text-Image Retrieval (KTIR) method for remote sensing images. By mining relevant information from an external knowledge graph, KTIR enriches the text scope available in the search query and alleviates the information gaps between texts and images for better matching. Moreover, by integrating domain-specific knowledge, KTIR also enhances the adaptation of pre-trained vision-language models to remote sensing applications. Experimental results on three commonly used remote sensing text-image retrieval benchmarks show that the proposed knowledge-aware method leads to varied and consistent retrievals, outperforming state-of-the-art retrieval methods.
ConGeo: Robust Cross-view Geo-localization across Ground View Variations
Mar 20, 2024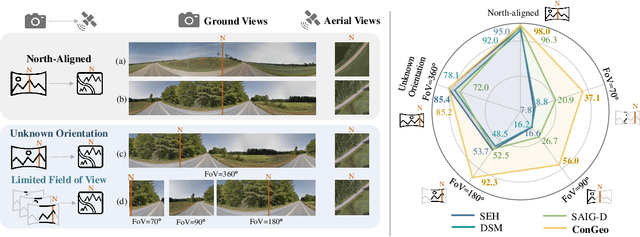
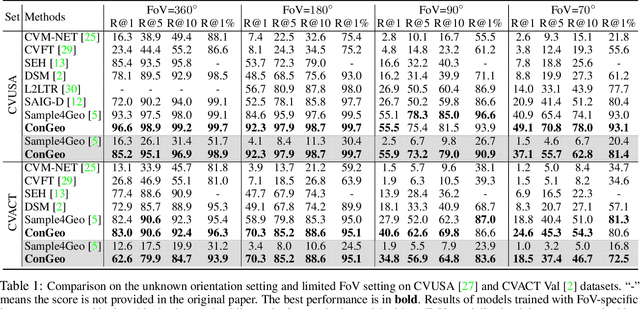
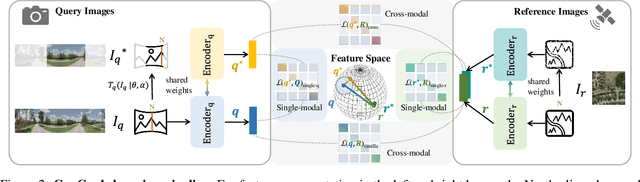

Cross-view geo-localization aims at localizing a ground-level query image by matching it to its corresponding geo-referenced aerial view. In real-world scenarios, the task requires accommodating diverse ground images captured by users with varying orientations and reduced field of views (FoVs). However, existing learning pipelines are orientation-specific or FoV-specific, demanding separate model training for different ground view variations. Such models heavily depend on the North-aligned spatial correspondence and predefined FoVs in the training data, compromising their robustness across different settings. To tackle this challenge, we propose ConGeo, a single- and cross-modal Contrastive method for Geo-localization: it enhances robustness and consistency in feature representations to improve a model's invariance to orientation and its resilience to FoV variations, by enforcing proximity between ground view variations of the same location. As a generic learning objective for cross-view geo-localization, when integrated into state-of-the-art pipelines, ConGeo significantly boosts the performance of three base models on four geo-localization benchmarks for diverse ground view variations and outperforms competing methods that train separate models for each ground view variation.
ConVQG: Contrastive Visual Question Generation with Multimodal Guidance
Feb 20, 2024



Asking questions about visual environments is a crucial way for intelligent agents to understand rich multi-faceted scenes, raising the importance of Visual Question Generation (VQG) systems. Apart from being grounded to the image, existing VQG systems can use textual constraints, such as expected answers or knowledge triplets, to generate focused questions. These constraints allow VQG systems to specify the question content or leverage external commonsense knowledge that can not be obtained from the image content only. However, generating focused questions using textual constraints while enforcing a high relevance to the image content remains a challenge, as VQG systems often ignore one or both forms of grounding. In this work, we propose Contrastive Visual Question Generation (ConVQG), a method using a dual contrastive objective to discriminate questions generated using both modalities from those based on a single one. Experiments on both knowledge-aware and standard VQG benchmarks demonstrate that ConVQG outperforms the state-of-the-art methods and generates image-grounded, text-guided, and knowledge-rich questions. Our human evaluation results also show preference for ConVQG questions compared to non-contrastive baselines.
Semi-Supervised Semantic Segmentation in Earth Observation: The MiniFrance Suite, Dataset Analysis and Multi-task Network Study
Oct 15, 2020

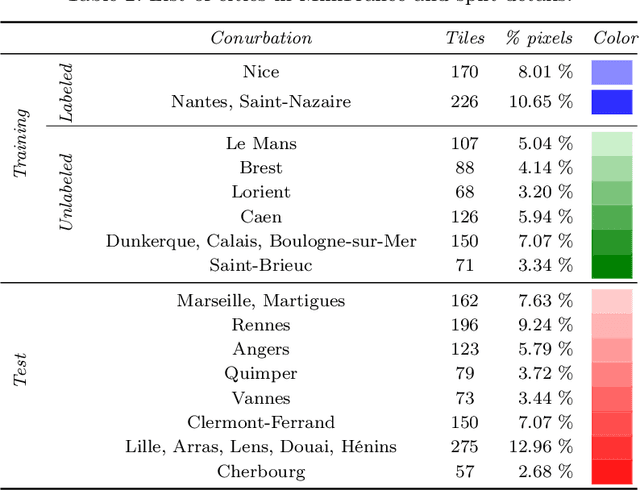
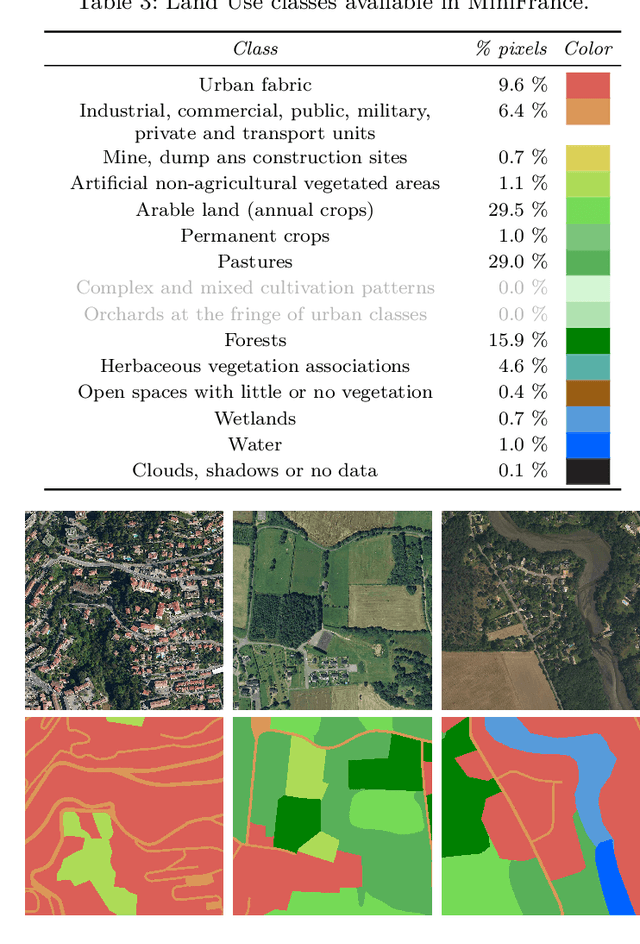
The development of semi-supervised learning techniques is essential to enhance the generalization capacities of machine learning algorithms. Indeed, raw image data are abundant while labels are scarce, therefore it is crucial to leverage unlabeled inputs to build better models. The availability of large databases have been key for the development of learning algorithms with high level performance. Despite the major role of machine learning in Earth Observation to derive products such as land cover maps, datasets in the field are still limited, either because of modest surface coverage, lack of variety of scenes or restricted classes to identify. We introduce a novel large-scale dataset for semi-supervised semantic segmentation in Earth Observation, the MiniFrance suite. MiniFrance has several unprecedented properties: it is large-scale, containing over 2000 very high resolution aerial images, accounting for more than 200 billions samples (pixels); it is varied, covering 16 conurbations in France, with various climates, different landscapes, and urban as well as countryside scenes; and it is challenging, considering land use classes with high-level semantics. Nevertheless, the most distinctive quality of MiniFrance is being the only dataset in the field especially designed for semi-supervised learning: it contains labeled and unlabeled images in its training partition, which reproduces a life-like scenario. Along with this dataset, we present tools for data representativeness analysis in terms of appearance similarity and a thorough study of MiniFrance data, demonstrating that it is suitable for learning and generalizes well in a semi-supervised setting. Finally, we present semi-supervised deep architectures based on multi-task learning and the first experiments on MiniFrance.